

Aplikace se zvětšují a jsou složitější, takže vývojáři hledají způsoby, jak zvýšit výkon a optimalizovat uživatelskou zkušenost. Rozdělení kódu řeší tyto problémy řízením toho, jak a kdy se načítají různé části kódu aplikace. Zkoumání dělení kódu, jeho výhod, metod implementace, osvědčených postupů a toho, jak se nástroje líbí SMART TS XL může usnadnit jeho přijetí, zejména v souvislosti s modernizací starších aplikací.
Co je dělení kódu?
Dělení kódu je technika používaná k rozdělení velkých databází kódů na menší, spravovatelné bloky nebo svazky. Tento přístup umožňuje aplikaci načíst pouze nezbytné části kódu v konkrétním okamžiku, spíše než načítat celou kódovou základnu předem. To pomáhá zlepšit počáteční dobu načítání, snižuje využití paměti a poskytuje plynulejší uživatelský zážitek.
Například v jednostránkových aplikacích (SPA) může být veškerý kód tradičně sdružen do jednoho velkého souboru JavaScript. Jak aplikace roste, tento soubor se zvětšuje, což vede k pomalejšímu načítání. Rozdělení kódu řeší tento problém rozdělením kódu na menší části, což umožňuje aplikaci načíst pouze to, co je vyžadováno pro aktuální stránku nebo funkci.
Proč na dělení kódu záleží
Význam rozdělení kódu spočívá v jeho schopnosti optimalizovat výkon aplikací a uživatelskou zkušenost. Velké balíčky kódů mohou výrazně ovlivnit dobu načítání, zejména v pomalejších sítích nebo mobilních zařízeních. Snížením množství kódu, který je třeba stáhnout a spustit, má rozdělení kódu za následek rychlejší interakce a citlivější aplikaci. V dnešním digitálním prostředí může i krátké zpoždění načítání způsobit, že uživatelé aplikaci opustí, což má za následek ztrátu zapojení a potenciálních příjmů.
Rozdělení kódu také pomáhá minimalizovat nároky na paměť aplikace tím, že zajišťuje, aby byly do paměti v daném okamžiku nahrány pouze nezbytné moduly. To je výhodné pro aplikace s bohatými, funkcemi bohatými rozhraními, kde nejsou vyžadovány všechny funkce současně.
Jak funguje dělení kódu
Statické dělení kódu (rozdělení kódu na základě trasy)
Statické dělení kódu, známé také jako „rozdělení kódu na základě cesty“, zahrnuje rozdělení kódu na kousky v době sestavování na základě předem stanovených pravidel. Tento přístup se běžně používá ve webových aplikacích, které mají odlišné trasy nebo pohledy, jako jsou SPA.
V této metodě je každá trasa nebo hlavní komponenta během procesu sestavování svázána do vlastního souboru. Když uživatel naviguje na konkrétní trasu, aplikace načte pouze odpovídající balíček. Statické dělení kódu je často implementováno pomocí modulových svazků, které automaticky rozdělují kód do samostatných svazků podle specifikace vývojáře.
Například v aplikaci React lze statického rozdělení kódu dosáhnout pomocí syntaxe import(). Níže uvedený kód ukazuje, jak lze různé trasy rozdělit do samostatných svazků:
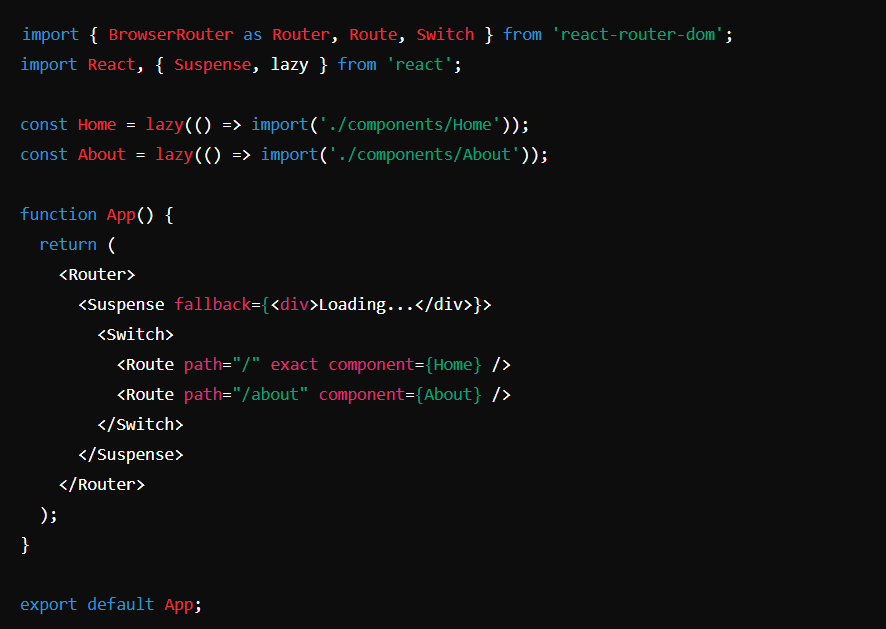
V tomto příkladu jsou komponenty Home a About rozděleny do samostatných svazků. Tyto balíčky se načítají dynamicky, když uživatel naviguje na příslušné trasy, což snižuje množství kódu, který je třeba načíst zpočátku.
Dynamické dělení kódu (rozdělení kódu na vyžádání)
Dynamické dělení kódu, známé také jako „on-demand“ nebo „líné načítání“, zahrnuje rozdělení kódu za běhu na základě interakcí uživatele. Tato strategie používá dynamické importy (import()) k načtení konkrétních částí kódu pouze v případě, že jsou potřeba. Na rozdíl od statického dělení kódu umožňuje dynamické dělení podrobnější kontrolu, což umožňuje vývojářům rozdělovat kód v rámci komponent nebo dokonce na úrovni funkcí.
Dynamické dělení kódu je užitečné zejména pro načítání málo používaných komponent, jako jsou modály, widgety nebo knihovny třetích stran, čímž se snižuje počáteční velikost balíčku. Zde je příklad dynamického rozdělení kódu v komponentě React:

V tomto příkladu se LazyComponent načte pouze tehdy, když uživatel klikne na tlačítko. To zkracuje dobu počátečního načítání a zajišťuje, že nepotřebný kód nebude spuštěn, dokud nebude vyžadován. Komponenta Suspense se používá ke zpracování stavu načítání a poskytuje uživateli zpětnou vazbu během načítání komponenty.
Výhody dělení kódu
Vylepšená doba počátečního načítání
Jednou z hlavních výhod rozdělení kódu je zlepšení počáteční doby načítání aplikace. Rozdělením kódové základny na menší části si prohlížeč stáhne pouze základní kód potřebný pro první obrazovku nebo interakci uživatele. Výsledkem je rychlejší počáteční načítání, protože prohlížeč nemusí zpracovávat velké, monolitické soubory před vykreslením aplikace.
V jednostránkových aplikacích (SPA), kde jsou všechny komponenty tradičně spojeny dohromady, umožňuje rozdělení kódu aplikaci načíst pouze komponenty nezbytné pro aktuální zobrazení. To výrazně zkracuje čas do prvního smysluplného nátěru, zlepšuje vnímaný výkon a odezvu aplikace.
Vylepšený výkon aplikací
Rozdělení kódu optimalizuje výkon aplikace tím, že snižuje nároky na paměť a množství JavaScriptu, který je třeba spustit. Načítáním kódu po menších segmentech aplikace minimalizuje zátěž na systémové prostředky, což má za následek plynulejší interakce, zejména na zařízeních s omezeným výpočetním výkonem.
Když uživatelé procházejí různými částmi aplikace, rozdělení kódu zajišťuje, že se v případě potřeby načítají pouze požadované části. Tento mechanismus načítání na vyžádání zabraňuje zbytečnému spouštění kódu, což může zlepšit celkový výkon a vést k pohotovější uživatelské zkušenosti.
Efektivní řízení zdrojů
Při dělení kódu se do paměti v daném okamžiku načítají pouze nezbytné moduly nebo funkce. Toto selektivní načítání zajišťuje efektivnější využití systémových prostředků, zejména paměti. Když aplikace nenačte veškerý kód předem, systém může alokovat zdroje pro běh základních komponent, čímž se vyhne potenciálnímu zpomalení způsobenému nadměrným využitím paměti.
Tento aspekt je zvláště cenný pro aplikace, které jsou bohaté na funkce a mají složitá uživatelská rozhraní. Díky efektivní správě zdrojů může aplikace zvládnout více funkcí bez odpovídajícího poklesu výkonu.
Rychlejší následné načítání s ukládáním do mezipaměti
Další klíčovou výhodou dělení kódu je vylepšené ukládání do mezipaměti. Když je aplikace rozdělena do několika menších balíčků, může prohlížeč ukládat do mezipaměti jednotlivé části. Při dalších návštěvách je třeba stáhnout pouze nové nebo aktualizované bloky. To znamená, že části aplikace, které se nezměnily, již budou v mezipaměti prohlížeče, což má za následek rychlejší načítání pro vracející se uživatele.
V tradičních monolitických aplikacích by jakákoli drobná změna vyžadovala, aby si uživatelé stáhli celý balíček znovu. Rozdělení kódu tento problém zmírňuje tím, že zajišťuje, že jsou znovu načteny pouze změněné části, což snižuje spotřebu dat a urychluje následné interakce.
Vylepšená škálovatelnost a udržovatelnost
Rozdělení aplikace na menší, spravovatelné moduly přirozeně usnadňuje údržbu a škálování. Rozdělení kódu podporuje modulární design, kde se vývojáři zaměřují na vytváření a aktualizaci jednotlivých částí kódu. Tato modularita zjednodušuje proces ladění, protože problémy lze izolovat na konkrétní části aplikace.
Jak aplikace roste a jsou zaváděny nové funkce, mohou vývojáři rozdělit další moduly na nové části, aniž by to ovlivnilo výkon stávajícího kódu. Tento přístup umožňuje nepřetržitý vývoj a nasazení, což aplikaci umožňuje efektivnější škálování.
Hladší uživatelská zkušenost
Když uživatelé interagují s aplikací, očekávají bezproblémový zážitek s minimálním zpožděním. Rozdělení kódu přispívá k plynulejšímu uživatelskému zážitku díky asynchronnímu načítání nových modulů na pozadí, když uživatelé procházejí různými částmi aplikace. Předběžným načtením nebo předběžným načtením kódu pro další možné interakce může aplikace poskytnout téměř okamžité odezvy a snížit vnímanou latenci.
Například ve webové aplikaci rozdělení kódu umožňuje rychlé načtení úvodní stránky, zatímco předběžné načítání na pozadí načítá další zdroje. Tato strategie zajišťuje, že následné navigace budou rychlé a plynulé, protože potřebný kód byl načten dříve, než si jej uživatel vyžádá.
Lepší manipulace se složitými aplikacemi
Ve velkých aplikacích může správa složitých funkcí vést k ohromně velkému balíku kódu, který snižuje výkon. Rozdělení kódu řeší tento problém tím, že umožňuje vývojářům rozdělit tyto složité funkce do menších, nezávislých modulů, které lze v případě potřeby načíst.
Tato modularizace zajišťuje, že během uživatelských interakcí jsou zpracovávány pouze relevantní části kódové základny, čímž se předchází úzkým místům výkonu. Díky správě složitosti tímto způsobem umožňuje dělení kódu vývojářům vytvářet bohaté aplikace s vysokými funkcemi bez kompromisů ve výkonu.
Vylepšená flexibilita pro aktualizace funkcí
Rozdělení kódu poskytuje flexibilitu při aktualizaci nebo přidávání funkcí do aplikace. Vzhledem k tomu, že různé funkce jsou izolovány do samostatných částí, mohou vývojáři upravovat nebo zavádět nové funkce, aniž by to ovlivnilo celou kódovou základnu. Tento oddělený přístup minimalizuje riziko zavádění chyb a zajišťuje, že změny mají omezený dopad na ostatní části aplikace.
Když je přidána nová funkce, lze ji seskupit do vlastního bloku, který lze v případě potřeby dynamicky načíst. To nejen urychluje proces nasazení, ale také snižuje pravděpodobnost problémů s regresí ve stávajících funkcích.
Optimalizované využití sítě
Omezením počáteční velikosti balíčku optimalizuje rozdělení kódu využití sítě. To je výhodné zejména pro uživatele s pomalejším připojením nebo mobilními zařízeními, kde velké balíčky mohou vést k prodloužení doby načítání. Protože je načítán pouze kód nezbytný pro aktuální interakci uživatele, jsou síťové zdroje využívány efektivněji.
Navíc díky předběžnému načítání nebo načítání zdrojů na základě očekávaného chování uživatelů zajišťuje rozdělení kódu, že aplikace načte pouze to, co je nezbytné, čímž se zabrání plýtvání šířkou pásma, které přichází se stahováním nepoužívaných modulů.
Usnadňuje implementaci progresivní webové aplikace (PWA).
Pro vývojáře vytvářející progresivní webové aplikace (PWA) je rozdělení kódu zásadní. Cílem PWA je poskytovat na webu zážitek podobný aplikacím s rychlými časy načítání a možnostmi offline. Rozdělení kódu podporuje tento cíl tím, že snižuje velikost počátečního stahování a umožňuje dynamické načítání obsahu na základě interakce uživatele. Bezproblémově také spolupracuje se servisními pracovníky, kteří mohou jednotlivé bloky ukládat do mezipaměti, aby usnadnili offline přístup a rychlé načítání, což dále zlepšuje zážitek z PWA.
Nejlepší postupy pro dělení kódu
Zatímco rozdělení kódu může výrazně zvýšit výkon aplikace, dodržování osvědčených postupů maximalizuje jeho výhody:
Vyhněte se nadměrnému dělení
Rozdělení kódu na příliš mnoho malých částí může vést k nadměrnému počtu síťových požadavků, což může způsobit více škody než užitku. Je důležité najít rovnováhu mezi snížením velikosti balíčku a minimalizací počtu požadavků HTTP.
Seskupit podobné moduly
Při rozdělování kódu seskupte podobné moduly, které se často používají společně, do jednoho bloku. To snižuje nadbytečné zatížení a zajišťuje dostupnost souvisejících funkcí v případě potřeby.
Optimalizujte prioritu zatížení
Použijte techniky jako preload a prefetch k optimalizaci priority načítání bloků kódu. To pomáhá rychleji načítat kritické části a zároveň přednačítat méně naléhavé, což dále zlepšuje uživatelský dojem.
Testování a profilování
Pravidelně testujte a profilujte aplikaci, abyste mohli sledovat dopad rozdělení kódu na výkon. Testovací nástroje mohou identifikovat úzká místa a pomoci optimalizovat strategii rozdělení.
Výzvy a úvahy
Zatímco dělení kódu je výkonná technika pro zvýšení výkonu webových aplikací, přichází s vlastní sadou výzev a úvah. Správná implementace rozdělení kódu vyžaduje pečlivé plánování a hluboké pochopení architektury aplikace, chování uživatelů a potenciálních úskalí. Zde jsou některé z hlavních výzev a úvah, kterým vývojáři čelí při implementaci dělení kódu:
Zvýšená složitost správy kódové báze
Jednou z nejvýznamnějších výzev při dělení kódu je přidaná složitost, kterou přináší do kódové základny. Když je aplikace rozdělena na menší, nezávisle načtené části, vývojáři musí řídit, kdy a jak se tyto části načítají. To zahrnuje řešení asynchronního načítání modulů, zajištění bezproblémové spolupráce dynamicky importovaných komponent se zbytkem aplikace a řešení případných chyb během načítání.
Tato složitost může prodloužit křivku učení pro nové vývojáře, kteří se připojují k projektu, a může ztížit ladění. Chyby ve správě rozděleného kódu mohou vést k chybám za běhu nebo neočekávanému chování, což má dopad na stabilitu aplikace.
Správa závislostí a duplikace kódu
Při rozdělování kódu do menších balíčků je důležité sledovat závislosti obsažené v každém bloku. Pokud dva nebo více bloků sdílí společné závislosti, mohou skončit zahrnutím těchto závislostí samostatně, což vede k duplikaci kódu napříč balíčky. Tato redundance zvyšuje celkovou velikost souborů, které je třeba stáhnout, což může negovat výkonnostní výhody dělení kódu.
Aby se to zmírnilo, musí být vývojáři pilní analyzovat jejich strom závislostí a pomocí optimalizačních strategií, jako je extrahování sdílených závislostí do samostatných svazků. To však přidává další vrstvu složitosti do procesu sestavování a vyžaduje pravidelné sledování, jak se aplikace vyvíjí.
Zpracování stavu načítání
Při použití dynamických importů se komponenty nebo moduly načítají asynchronně. To znamená, že mezi okamžikem, kdy uživatel spustí akci (např. navigace na novou trasu) a okamžikem stažení a spuštění odpovídajícího bloku kódu, může být prodleva. Během této prodlevy musí uživatelské rozhraní zpracovat stav načítání elegantně, obvykle zobrazením číselníku načítání nebo zástupného obsahu.
Správná správa tohoto stavu načítání je zásadní pro udržení hladkého uživatelského zážitku. Špatná manipulace může mít za následek pomalé a nereagující rozhraní, které může uživatele frustrovat a způsobit, že aplikaci opustí. Kromě toho musí vývojáři řešit potenciální chyby při načítání (např. selhání sítě) a poskytovat smysluplnou zpětnou vazbu uživatelům, když takové situace nastanou.
Vyrovnávání počtu kusů
Rozdělení kódu na příliš mnoho malých částí může vést k nadměrnému počtu síťových požadavků. Když prohlížeč zadá více požadavků na načtení každého bloku, může to způsobit zpoždění kvůli latenci sítě, zejména u pomalých připojení. Na druhou stranu vytváření menšího počtu větších bloků může zlepšit efektivitu sítě, ale přesto může vést k velkým souborům, jejichž stahování a analýza trvá déle.
Nalezení správné rovnováhy mezi počtem kusů a jejich velikostí je zásadní. To často vyžaduje, aby vývojáři profilovali aplikaci, experimentovali s různými strategiemi dělení a doladili konfiguraci tak, aby vyhovovala konkrétnímu případu použití. Tento proces pokračuje, protože změny v kódové základně aplikace nebo chování uživatele mohou vyžadovat úpravy ve způsobu rozdělení kódu.
Dopad na výkon počátečního zatížení
Ačkoli rozdělení kódu může zlepšit výkon načítání tím, že zpozdí načítání určitých částí kódové základny, může mít někdy opačný účinek, pokud není implementováno promyšleně. Pokud se například počáteční blok, který načítá základní funkce aplikace, stane příliš velkým, může to zpomalit počáteční dobu vykreslování. Pokud je navíc příliš mnoho kritických komponent rozděleno do samostatných částí, které je třeba okamžitě načíst, může to mít za následek více současných síťových požadavků, což může zpozdit počáteční vykreslování.
Pro optimalizaci výkonu při počátečním načítání musí vývojáři pečlivě vybrat, které části kódové základny zahrnout do počátečního balíčku a které rozdělit na samostatné části. To zahrnuje pochopení, které komponenty a moduly jsou nezbytné pro první interakci s uživatelem, a odložení načítání méně kritických funkcí, dokud to nebude potřeba.
Ukládání do mezipaměti a verzování
Ukládání do mezipaměti je klíčovým faktorem při zlepšování výkonu aplikace. Díky rozdělení kódu lze každý blok uložit do mezipaměti nezávisle, čímž se sníží množství dat, která je třeba stáhnout při dalších návštěvách. To však také zavádí složitost správy mezipaměti a verzování. Když se kód změní, jak zajistíte, že se načtou správné, aktualizované bloky, aniž by uživatel zaznamenal chyby způsobené zastaralými soubory v mezipaměti?
Správné strategie vynechání mezipaměti, jako je použití hashování obsahu v názvech souborů, jsou nezbytné k zajištění toho, že uživatelé vždy obdrží nejnovější verzi každého bloku. Správná implementace těchto strategií však vyžaduje pečlivé plánování a pochopení toho, jak prohlížeče a sítě pro doručování obsahu (CDN) zacházejí s ukládáním do mezipaměti.
Monitorování a analýza
Rozdělení kódu může ovlivnit způsob, jakým jsou sledovány a analyzovány interakce uživatelů. Když jsou bloky načítány dynamicky, může být náročnější efektivně monitorovat chování uživatelů, například sledovat, jak dlouho trvá, než se určité funkce stanou interaktivními, nebo měřit dopad konkrétních bloků na výkon.
K vyřešení tohoto problému potřebují vývojáři integrovat monitorovací a analytické nástroje, které podporují dynamické načítání. Tyto nástroje mohou poskytnout informace o tom, jak rozdělení kódu ovlivňuje uživatelskou zkušenost, a pomohou vývojářům vyladit jejich strategii rozdělení.
Testování a profilování
Testování aplikace, která používá rozdělení kódu, vyžaduje další úvahy. Vývojáři musí zajistit, aby rozdělené komponenty hladce spolupracovaly a správně zvládaly asynchronní stavy načítání. Automatizované testy by měly pokrývat scénáře, jako je pomalé načítání komponent, zpracování chyb během dynamických importů a uživatelské interakce při načítání bloků.
Nástroje profilování se stávají nezbytnými při optimalizaci strategie dělení. Vývojáři potřebují pravidelně profilovat aplikaci, aby identifikovali úzká hrdla, monitorovali velikosti bloků a analyzovali síťové požadavky, aby zajistili, že rozdělení kódu přinese požadované výhody výkonu.
Dopad na uživatelskou zkušenost
V konečném důsledku je cílem rozdělení kódu zlepšit uživatelskou zkušenost. Nesprávné použití však může mít za následek negativní zkušenosti, jako jsou opožděné interakce, příliš často se objevující spinnery načítání nebo neočekávané chování během navigace. Vývojáři musí mít při navrhování strategie dělení kódu na paměti cestu uživatele, aby zajistili, že aplikace zůstane rychlá, citlivá a plynulá.
Jak SMART TS XL Může být užitečné pro účely dělení kódu
SMART TS XL je sofistikovaný nástroj navržený tak, aby poskytoval hloubkovou analýzu velkých kódových základen, odhaloval vzory a zvýraznil oblasti, které mohou těžit z optimalizace, modernizace a restrukturalizace. Pokud jde o dělení kódu, SMART TS XL dokáže určit, které části aplikace jsou vhodnými kandidáty na rozdělení, a pomoci vývojářům činit informovaná rozhodnutí za účelem optimalizace výkonu.
SMART TS XL také identifikuje malé, ale silně odkazované soubory. Vývojáři mohou tyto informace použít k určení, zda lze tyto soubory refaktorovat do menších nezávislých modulů, které lze v případě potřeby dynamicky načítat.
Analýza závislostí souborů a interakcí mezi programy
Dělení kódu se může stát složitým, pokud existují vzájemné závislosti mezi různými moduly. SMART TS XLSchopnost mapovat odkazy na soubory a interakce je zde neocenitelná. Umožňuje vývojářům pochopit, které soubory jsou úzce propojeny a které mají širší závislosti napříč aplikací. Tento náhled je nezbytný při rozhodování o tom, kam rozdělit kód, aby se zabránilo nadbytečnému načítání a zbytečné složitosti.
Odhalením interakcí a závislostí SMART TS XL umožňuje vývojářům vytvořit jasný kód strategie rozdělení, která minimalizuje duplicitní kód mezi bloky a zajišťuje, že společné nástroje a sdílené moduly jsou zpracovávány optimalizovaným způsobem.
Odhalování skrytých složitostí v malých souborech s vysokým využitím
SMART TS XL dokáže identifikovat malé soubory, které mají překvapivě vysoký počet odkazů. Tyto soubory často představují pomocné funkce, které se používají v celém systému. Pochopení jejich role a distribuce napříč kódovou základnou umožňuje vývojářům rozhodnout, jak lze tyto nástroje začlenit do strategie dělení kódu.
SMART TS XLSchopnost detekovat tyto vzory zajišťuje, že při rozdělování kódu jsou brány v úvahu i často přehlížené obslužné funkce.
Podpora starší modernizace pomocí statistik rozdělení kódu
Starší aplikace často obsahují monolitické struktury s pevně spojenými součástmi. SMART TS XL vyniká při skenování prostřednictvím starších kódových základen a identifikaci potenciálních oblastí pro modularizaci. Zdůrazněním přítomnosti velkých souborů a mapováním jejich rozsáhlých referencí pomáhá tento nástroj vývojářům určit priority, které části staršího systému by měly být rozděleny do menších modulů.
Během procesu modernizace dědictví kódové základny, SMART TS XL může pomoci určit, které segmenty kódu jsou pro tok dat systému nejkritičtější, jako jsou klíčové programy založené na přirozeném prostředí nebo složité rutiny COBOL. To umožňuje vývojářům implementovat rozdělení kódu způsobem, který nejen zlepší výkon, ale také zachová integritu starší logiky.
Monitorování potenciálních redundantních příležitostí pro vyčištění a rozdělení kódu
SMART TS XL dokáže detekovat soubory s nízkým počtem odkazů a minimální velikostí. Tyto by mohly označte nadbytečný nebo zastaralý kód které mohou zahltit systém. Vyčištěním takových souborů mohou vývojáři zefektivnit kódovou základnu a usnadnit implementaci dělení kódu.
Navíc, SMART TS XLPodrobná analýza může vývojářům pomoci identifikovat moduly, které mají překrývající se funkce nebo by mohly být konsolidovány. Jakmile jsou nadbytečné soubory konsolidovány nebo odstraněny, zbývající kódová základna se stává modulárnější a vhodná pro dělení kódu.
Strategické plánování pro dělení kódu
SMART TS XLData, včetně distribuce velikosti souboru, počtu referencí a vzorců interakce, umožňují strategické plánování rozdělení kódu. Vývojáři mohou tyto informace použít k rozhodnutí, které části aplikace by měly být zahrnuty do počátečního balíčku a které části lze načíst asynchronně. Porovnáním počtu referencí s velikostí souborů SMART TS XL pomáhá určit „hotspoty“ v rámci aplikace – moduly, které jsou velké a intenzivně využívané, což jsou vynikající kandidáti na rozdělení za účelem zvýšení výkonu.
Závěr
Rozdělení kódu není univerzální řešení, ale spíše dynamický nástroj v sadě nástrojů pro vývojáře. Při správné implementaci dokáže přeměnit pomalou, monolitickou aplikaci na rychlý, citlivý a škálovatelný systém. Vylepšuje uživatelskou zkušenost tím, že načítá pouze nezbytné části kódu, snižuje využití paměti a optimalizuje správu zdrojů. Jeho implementace však vyžaduje pečlivé zvážení potenciálních problémů, včetně zvýšené složitosti, zpracování stavů načítání, správy závislostí a vyvážení velikostí bloků. Pochopením těchto výzev a důkladným provedením analýza dopadu, statická analýza kóduDíky neustálému testování mohou vývojáři zvládnout dělení kódu a vytvářet vysoce výkonné aplikace zaměřené na uživatele. V éře, kde je výkon klíčovým rozdílem v digitálních zážitcích, nabízí dělení kódu sofistikovanou metodu, jak udržet aplikace štíhlé, citlivé a přizpůsobitelné měnícím se požadavkům.
SMART TS XL poskytuje hloubkový pohled do struktury a použití kódu v rámci softwarového systému, což z něj činí nepostradatelný nástroj pro vedení rozhodování o dělení kódu. Jeho schopnost analyzovat velikosti souborů, počty referencí, závislosti a interakce pomáhá vývojářům identifikovat kritické části aplikace, které by nejvíce těžily z rozdělení kódu. Odhalením skrytých složitostí, sledováním potenciálního propouštění a podporou starší modernizace, SMART TS XL vybavuje vývojáře informacemi potřebnými k optimalizaci jejich aplikací, snížení velikosti balíků a zkrácení doby načítání. To v konečném důsledku vede k modulárnějšímu, škálovatelnějšímu a výkonnějšímu systému přizpůsobenému jedinečným požadavkům každé aplikace.