
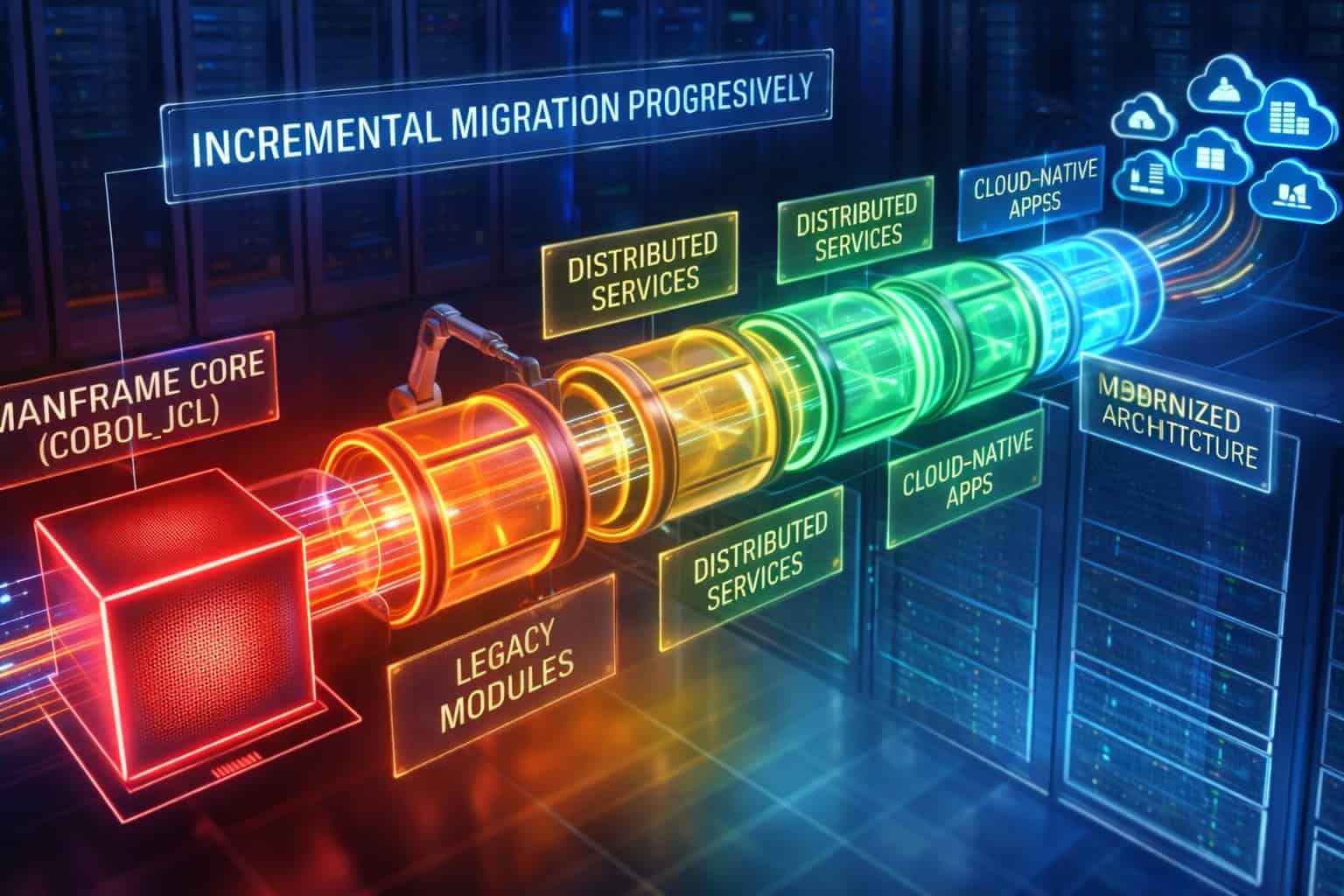
ミッションクリティカルな業務を中断することなく近代化を目指す企業にとって、メインフレームの段階的な移行は今や主流の戦略となっています。全面的な書き換えやリスクの高いカットオーバーではなく、COBOLプログラム、JCLワークフロー、分散サービス全体にわたる段階的な変革を追求する組織が増えています。このアプローチは、移行プロセス全体を通してシステムがトランザクション処理、バッチ処理、そして規制遵守を継続しなければならない大規模環境の運用実態を反映しています。
段階的な移行は魅力的であるにもかかわらず、独特の技術的複雑さをもたらします。COBOLロジック、JCLオーケストレーション、分散ランタイムは、それぞれ独立して進化するように設計されることはほとんどありませんでした。数十年にわたり、実行フロー、データタイミング、障害処理はこれらのレイヤー間で密接に絡み合ってきました。移行プロジェクトで要素を一つずつ抽出または近代化しようとすると、隠れた結合が予期せぬ形で表面化し、進捗を遅らせ、運用リスクを増大させます。これらの課題は、既に多くの課題を抱えている環境では、さらに深刻化します。 レガシーシステムの近代化アプローチドキュメントは実際のシステムの動作を反映しなくなります。
最も困難な問題は、個々のプログラムやサービスレベルで発生することは稀です。むしろ、バッチ処理とオンライン処理、スケジュール実行とイベント駆動フロー、そして決定論的なメインフレームロジックと分散リトライセマンティクスの境界で顕在化します。実行パスとデータの依存関係を明確に理解せずにこれらの境界を越えると、段階的な移行作業はしばしば行き詰まります。一見限定的な変更のように見えても、プラットフォーム全体に波及し、チームは着実な変革ではなく、長期にわたる安定化サイクルを強いられることになります。
COBOL、JCL、分散サービス間の移行を成功させるには、ツールや移行パターンだけでは不十分です。現在のシステムがどのように実行されているか、コンポーネント間で責任がどのように分担されているか、そしてシステムの各部分が独立して移行した場合に動作がどのように変化するかを正確に理解する必要があります。企業が移行を進めるにつれて、 段階的な近代化戦略実行の継続性、データ フローの整合性、および障害のセマンティクスについて推論する能力は、制御された進行と変換の停滞を決定づける要因になります。
COBOLプログラムとJCLワークフロー間の構造的結合
メインフレームの段階的な移行では、COBOLプログラムとJCLワークフローが構造的に不可分であるという事実が過小評価されがちです。これらは別々の成果物として管理されることが多いものの、その実行セマンティクスは数十年にわたって共に進化してきました。JCLはプログラムのスケジュール設定だけにとどまりません。実行順序、条件分岐、再起動動作、データセットのライフサイクル、そしてCOBOLコードが暗黙的に依存しているリカバリセマンティクスを定義します。移行中にこれらの要素を個別に扱うと、コードレベルではすぐには目に見えないリスクが生じます。
この結合は、移行プロジェクトがCOBOLロジックの抽出やモダナイゼーションに重点を置き、運用コンテキストを考慮に入れない場合に特に問題となります。プログラム単体の動作は、本番環境のジョブストリーム内での動作と一致することはほとんどありません。この関係性を無視した段階的な移行は、機能の逸脱、データ状態の不整合、そして安定化サイクルの長期化につながることが多く、段階的な移行のメリットを損ないます。
スケジューリングロジックだけでなく実行制御層としての JCL
JCLは、プログラムを順番に呼び出すことを主な役割とするスケジューリングまたはオーケストレーションのメカニズムであると誤解されることがよくあります。実際には、JCLは実行制御層として機能し、COBOLプログラムの実行方法とタイミング、どのような条件で分岐するか、そして成功と失敗の両方の状態にどのように対応するかを定義します。条件文、戻りコードチェック、データセット配置ルールは、プログラム自体の外部にあるビジネスロジックと運用ロジックをエンコードします。
COBOLプログラムが関連するJCLコンテキストなしで段階的に移行される場合、この制御ロジックは暗黙的に再実装されるか、完全に無視されることがよくあります。その結果、実稼働環境の標準から微妙に逸脱した動作が発生します。単独では機能的に正しく見えるプログラムでも、異なる条件下で実行されたり、異なるデータスコープを処理したり、期待通りに下流のステップをトリガーできなかったりすることがあります。
この問題は、JCLに時間の経過とともに階層化された条件が蓄積されている環境では深刻化します。緊急時の修正、規制上の例外、運用上の安全対策などは、アプリケーションロジックではなくジョブストリームに直接エンコードされることがよくあります。これらの構成要素は特定の状況下でのみ有効になる場合があり、分析中に見落とされやすいです。この制御層を可視化できないと、移行チームは本番環境の安定性に不可欠な動作を失ってしまうリスクがあります。
したがって、JCLを実行制御メカニズムとして理解することは、安全な増分移行に不可欠です。これにより、モダナイゼーションの取り組みにおいて、機能的な成果だけでなく、それらの成果がいつどのように生成されるかを制御する運用上のセマンティクスも維持されることが保証されます。
条件付きジョブフローと移行境界への影響
条件付きジョブフローは、移行境界を明確に定める上で最も大きな障壁の一つです。多くのメインフレーム環境では、戻りコード、データセットの可用性、あるいは外部シグナルに基づいて実行パスが分岐します。これらの条件によって、どのプログラムが実行され、どのステップがスキップされ、ジョブストリーム全体でどのようにデータが処理されるかが決まります。
段階的な移行作業では、多くの場合、この現実を反映しない線形実行モデルが前提となります。条件付きジョブフローを考慮せずにCOBOLプログラムを抽出または再ホストすると、移行されたコンポーネントが意図したよりも頻繁に、または異なる状況で実行される可能性があります。この不一致により、データ整合性のリスクや予測不可能な運用動作が発生します。
条件付きフローは、ロールバックとリカバリを複雑化させます。従来の環境では、JCL条件によってリスタートポイントと補償動作が定義されていました。フローの一部が移行され、一部がメインフレーム上に残る場合、一貫したリスタートセマンティクスの維持が困難になります。チームは、プラットフォーム間でリカバリ手順が整合しなくなり、インシデント発生時の運用リスクが増大することに気付く可能性があります。
これらの問題は、移行境界を定義する前にジョブフローの構造を分析することの重要性を浮き彫りにしています。動作の連続性を確保するためには、条件付き実行パスを特定し、維持する必要があります。この課題は、 JCLのマッピング方法プログラム呼び出しコンテキストを理解することは、システムを正確に理解する上で非常に重要です。
暗黙的な結合メカニズムとしてのデータセットライフサイクル
制御フローに加え、データセットはCOBOLプログラムとJCLワークフロー間の暗黙的な結合層を形成します。JCLは、データセットの作成、保持、共有、および破棄のルールを定義し、ジョブストリームにおけるデータの移動を制御します。COBOLプログラムは多くの場合、これらのルールを暗黙的に前提としており、データの可用性とライフサイクルの管理をJCLに依存しています。
増分移行では、データセットの取り扱いは、元のセマンティクスを完全に再現することなく、頻繁に再解釈または抽象化されます。一時データセットが永続化される、共有データセットが重複する、クリーンアップロジックが変更されるといった問題が発生する場合があります。これらの変更は、下流の処理やデータの整合性に連鎖的な影響を及ぼす可能性があります。
課題は、データセットのライフサイクルが一元的に文書化されていることがほとんどないことです。複数のジョブステップにわたってコード化され、運用上の慣例によって強化されています。コードレベルの分析のみに焦点を当てた移行チームは、これらの依存関係を見逃し、微妙ながらも影響の大きい逸脱につながる可能性があります。
データセットのセマンティクスを維持するには、ジョブストリームにおけるデータの流れと、ライフサイクルルールが実行にどのように影響するかを理解する必要があります。この理解がなければ、増分移行によって、負荷や障害発生時にのみ顕在化する隠れたデータ結合の問題が発生するリスクがあります。
ジョブ設計に組み込まれた再起動と回復のセマンティクス
メインフレーム環境における再起動と回復の動作は、多くの場合、アプリケーションロジックではなくジョブ設計に直接組み込まれています。JCLの再起動パラメータ、チェックポイント規則、条件付き再実行ロジックは、システムが部分的な障害からどのように回復するかを定義します。COBOLプログラムは、これらのメカニズムを念頭に置き、確実に再起動が保証されることを前提として記述されています。
移行作業によってプログラムがジョブコンテキストから切り離されると、これらの前提はもはや成り立たなくなる可能性があります。移行されたコンポーネントには同等の再起動セマンティクスが備わっていない場合があり、チームは復旧手順を再設計するか、リスクの増大を受け入れることを余儀なくされます。この再設計作業はしばしば過小評価され、段階的な移行プログラムの遅延の原因となります。
移行フェーズ全体にわたって一貫したリカバリ動作を維持することは、運用の安定性にとって非常に重要です。これにより、コンポーネントがプラットフォーム間で移行されても、障害処理が予測可能になります。この懸念は、より広範な課題と密接に関連しています。 並行実行期間の管理リカバリの一貫性が決定的な成功要因となります。
したがって、COBOLとJCLの構造的な結合は移行の障害ではなく、明確に対処しなければならない現実です。これらの関係を理解し、尊重し、変換フェーズ全体にわたって意図的に維持することで、段階的な移行は成功します。
増分移行がバッチとオンラインの境界で中断される理由
バッチ処理システムとオンライントランザクションシステムの境界は、メインフレームの段階的移行において最も脆弱な点の一つです。バッチワークロードとオンラインワークロードはしばしば別々の領域として議論されますが、成熟したエンタープライズ環境では、これらは緊密に連携したシステムとして動作します。バッチジョブは、オンラインシステムがほぼリアルタイムで消費するデータを準備、集計、調整します。これらの領域を独立して扱う段階的移行では、実行タイミング、データの可用性、または障害処理が異なる場合、しばしば不安定さに遭遇します。
この脆弱性は、バッチパイプラインの一部がメインフレーム上に残され、オンラインサービスが段階的に分散プラットフォームに移行するハイブリッドアーキテクチャにおいてさらに顕著になります。数十年にわたりバッチオンライン調整を規定してきた前提は、実行が複数のランタイムにまたがるともはや通用しなくなります。バッチ出力がオンラインの期待値とどのように整合するかを正確に理解していないと、移行プロジェクトはこの境界で行き詰まってしまいます。これは技術的な不可能性ではなく、動作の不確実性によるものです。
バッチ完了とオンライン可用性の間の時間的依存関係
段階的な移行において最も過小評価されている課題の一つは、バッチ実行とオンラインシステムの可用性の間に時間的な依存関係が存在することです。多くのオンラインアプリケーションは、トランザクションを処理する前に、特定のバッチサイクルが正常に完了していることを前提としています。こうした前提は、明示的な同期メカニズムによって強制されることはほとんどありません。むしろ、運用スケジュール、締め切り時間、そして非公式な運用手順書に組み込まれています。
バッチワークロードを段階的に移行する場合、実行タイミングが変化することがよくあります。分散バッチフレームワークは、メインフレームと比較して、実行速度が速かったり遅かったり、再試行セマンティクスが異なったりすることがあります。完了タイミングのわずかなずれでも、オンラインシステムが準備が不十分なデータセットにさらされ、診断が困難な不整合な動作につながる可能性があります。
これらのタイミングの問題は、段階的な移行において特に深刻です。段階的な移行では、一部のバッチステップがメインフレームで実行され、他のバッチステップが分散プラットフォームで実行されるからです。オンラインシステムでは、元の環境では存在しなかった混在状態が発生する可能性があります。かつては予測可能なバッチウィンドウに依存していたリカバリ手順は信頼性が低下し、運用リスクが増大します。
バッチオンライン境界を越えて安定性を維持するには、時間的な依存関係を理解し、維持することが不可欠です。これらの関係を明示的にモデル化しないと、増分移行によって、負荷や障害が発生した場合にのみ発生する微妙な競合状態が発生します。
オンラインロジックに組み込まれたデータ一貫性の期待
オンラインアプリケーションは、バッチ処理の動作に起因するデータ整合性に関する暗黙の前提をしばしば組み込んでいます。例えば、オンライントランザクションでは、ユーザーアクティビティが開始される前に、参照テーブルが完全に更新されていること、残高が調整されていること、集計が完了していることなどが想定されます。これらの前提は、従来バッチ実行順序によって保証されていたため、動的に検証されることはほとんどありません。
増分移行はこれらの保証を損ないます。バッチステップが再配置または再実装されると、一貫性モデルが変化する可能性があります。分散システムでは、以前は隠されていた中間状態が公開されたり、強い一貫性が前提とされていた場所に結果整合性が適用されたりする可能性があります。このような状態を処理するように設計されていないオンラインロジックは、予測できない動作を示し始めます。
この不一致はフィードバックループを生み出し、移行を複雑化させます。オンライン障害が発生するとバッチプロセスの調査が開始されますが、バッチの変更はオンラインの安定性要件によって制約されます。移行チームは境界の片側を凍結しなければ作業を進めることができず、段階的なアプローチが損なわれてしまいます。
この課題に対処するには、データの一貫性に関する前提を明示的に設定する必要があります。移行作業では、どのバッチ出力がオンラインの正確性にとって重要かを特定し、同等の保証が維持されるようにする必要があります。この問題は、 増分データ移行戦略部分的なデータの移動によって一貫性のリスクが生じます。
バッチドメインとオンラインドメイン間の障害伝播
バッチオンライン境界を越える障害は、増分移行中に特に特定が困難です。バッチ障害が数時間後にオンラインの問題として顕在化したり、オンライン過負荷により共有リソースに起因するバッチ遅延が発生したりする可能性があります。ハイブリッド環境では、コンポーネントが複数のプラットフォームにまたがるため、これらの相互作用の追跡がさらに困難になります。
増分移行では、新たな統合ポイントや実行コンテキストが導入されるため、障害パスの数が増加します。移行後のバッチステップで発生した障害は、元の環境とは異なる形で伝播し、過去のパターンと一致しないオンライン症状を引き起こす可能性があります。復旧チームは、問題が移行後のコンポーネントに起因するのか、それとも既存のコンポーネントに起因するのかを判断するのに苦労し、解決を遅らせます。
バッチドメインとオンラインドメインを横断した統一的な実行可視性の欠如が、この問題を悪化させています。監視ツールは多くの場合、どちらか一方のドメインに焦点を当てているため、境界にギャップが生じています。インシデント発生時には、チームはシグナルを手動で相関させる必要があり、MTTRと復旧のばらつきが増加します。
障害の伝播を理解するには、バッチシステムとオンラインシステムが通常時と例外時の両方でどのように相互作用するかを分析する必要があります。この分析がなければ、段階的な移行によって新たな運用上の盲点が生じ、安定性を阻害することになります。
バッチオンラインインターフェースにおける段階的なカットオーバーの複雑さ
バッチオンライン境界で段階的に機能を切り替えていく作業は、それ自体が複雑性を伴います。移行計画では、コンポーネントを個別に切り替えられると想定されることがよくあります。しかし実際には、動作の整合性を維持するために、バッチシステムとオンラインシステムは調整されたフェーズで切り替えを行う必要があります。
部分的なカットオーバーでは、一部のトランザクションが移行されたバッチ出力に依存し、他のトランザクションが従来の処理に依存するハイブリッドな実行パスが作成されます。このような混在状態は包括的なテストが困難であり、多くの場合、本番環境で初めて問題が明らかになります。境界の片側を元に戻しても元の動作に戻らない可能性があるため、ロールバック手順は複雑になります。
この複雑さにより、組織は移行の進捗を遅らせる保守的なカットオーバー戦略を採用せざるを得なくなります。チームは、すべてのインタラクションを確実に理解できるまで移行を遅らせ、段階的な移行による俊敏性のメリットを損ないます。
カットオーバーの複雑さに対処するには、バッチオンラインインタラクションとその依存関係に関する正確な知識が必要です。 バッチワークロードの近代化の課題 慎重な順序付けと影響の認識の必要性を強調します。
実行タイミング、データの一貫性、障害の伝播、カットオーバーのシーケンスが個別の問題ではなく統合システムとして理解され、管理されている場合、増分移行はバッチオンライン境界で成功します。
COBOL抽出時の実行パスの継続性の管理
COBOLの増分抽出は、コード中心の作業として提示されることが多いですが、その真の複雑さは、コンポーネントがプラットフォーム間を移動する際に実行パスの連続性を維持することにあります。COBOLプログラムは、独立したユニットとして動作することはほとんどありません。その動作は、呼び出しコンテキスト、上流のデータ準備、下流の消費、そして環境条件によって形作られ、これらが総合的に本番環境での実行展開を規定します。抽出作業がプログラムロジックのみに焦点を絞ると、これらのコンテキスト要因が見落とされやすくなります。
実行パスの連続性は、移行されたコンポーネントが従来のコンポーネントと一貫した動作をするかどうかを左右するため、非常に重要です。制御フロー、呼び出しタイミング、データ処理におけるわずかな差異でも、微妙な動作のずれが生じる可能性があります。大規模企業では、このようなずれが移行フェーズを跨いで蓄積され、予測不可能なシステム動作を引き起こし、進捗を遅らせ、段階的なアプローチへの信頼性を損ないます。
移行フェーズ全体で条件付きロジックの忠実性を維持する
COBOLプログラムに埋め込まれた条件付きロジックは、数十年にわたるビジネス上の例外、規制上の対応、運用上の安全対策を反映していることがよくあります。これらの条件は、抽出時にはすぐには分からないデータ値、実行コンテキスト、または外部シグナルに依存する場合があります。これらの条件の忠実性を維持することは、実行の継続性を維持するために不可欠です。
段階的な移行では、新しいプラットフォームやフレームワークに合わせて条件付きロジックが頻繁に再解釈またはリファクタリングされます。このようなリファクタリングは可読性やパフォーマンスを向上させる可能性がありますが、元の条件を深く理解した上で行われなければ、実行動作が変わってしまうリスクがあります。稀な状況でのみ実行されるように設計されたロジックが、より頻繁に実行されるようになったり、逆にその逆になったりして、システムの結果が変化する可能性があります。
このリスクは、条件付き動作が複数のプログラムにまたがる場合に増大します。あるCOBOLモジュールで評価された条件が、データの変更や戻りコードを通じて間接的に下流の実行パスに影響を与える可能性があります。これらの相互作用をモデル化せずに単一のプログラムを抽出すると、実行フローを制御する暗黙の契約が破られる可能性があります。
この課題に対処するには、プログラム内だけでなく、実行パス全体にわたって条件付きロジックを特定する必要があります。チームは、条件がいつアクティブになるか、どのくらいの頻度で発生するか、そして下流にどのような影響を引き起こすかを理解する必要があります。この理解がなければ、増分抽出によって動作の相違が生じ、テストだけでは検出が困難になります。
呼び出しコンテキストシフトとその隠れた効果
COBOLプログラムは、その呼び出し方法に大きく左右されます。パラメータ、実行環境、呼び出しコンテキストは、多くの場合文書化されていない形でプログラムの動作に影響を与えます。増分抽出は、呼び出しメカニズムを頻繁に変更し、JCL駆動型の実行をサービス呼び出し、スケジューラ、または分散ジョブフレームワークに置き換えます。
これらの変更により、実行パスが微妙に変化する可能性があります。パラメータの渡し方が異なったり、デフォルト値が変更されたり、環境の想定が成り立たなくなったりする可能性があります。例えば、JCLによる暗黙的なデータセット割り当てに依存していたプログラムは、新しいコンテキストで呼び出されたときにリソース不足に遭遇する可能性があります。
呼び出しコンテキストのシフトは、エラー処理や再起動の挙動にも影響を及ぼします。プログラムは、その呼び出し方法に応じて障害への対応が異なり、リカバリのセマンティクスに影響を与える可能性があります。こうした違いは、本番環境でインシデントが発生するまで顕在化しない可能性があり、その時点でロールバックのコストが増大します。
したがって、呼び出しコンテキストを理解することは、安全な抽出の前提条件です。チームは、プログラムが現在どのように呼び出され、どのような仮定が立てられ、そしてそれらの仮定がターゲット環境でどのように解釈されるかをマッピングする必要があります。この懸念は、 プログラム使用状況検出技術実行コンテキストによって実際のシステム動作が決まります。
抽出されたコンポーネントと残りのコンポーネント間の実行順序の依存関係
増分抽出では、一部のコンポーネントが移行され、他のコンポーネントがメインフレームに残る混合実行環境が作成されます。このような環境では、実行順序の依存関係が重要な問題となります。COBOLプログラムは、上流の特定のステップが完了し、下流のコンシューマが予測可能な順序で実行されることを前提としていることがよくあります。
実行チェーンの各部分が独立して動作する場合、これらの前提はもはや成り立たなくなる可能性があります。分散システムでは、並列処理や異なるスケジューリングセマンティクスが導入され、確立された順序が乱れる可能性があります。かつては順次実行されていたプログラムが、並列実行に移行し、競合状態やデータ競合の問題が発生する場合があります。
これらの順序依存関係は、明示的に文書化されることはほとんどありません。技術的な制約ではなく、スケジュール規則や運用上の規律によって強制されます。したがって、段階的な移行では、実行の継続性を維持するために、これらの依存関係を明らかにし、維持する必要があります。
これを怠ると、再現が困難な断続的な問題が発生する可能性があります。システムは低負荷時には安定しているように見えても、ピーク時には実行順序がずれて機能しなくなる可能性があります。このような障害は移行の進捗状況に対する信頼性を損ない、チームは変更を一時停止したり元に戻したりせざるを得なくなります。
累積的な移住リスクとしての行動漂流
動作ドリフトとは、移行フェーズを経るごとに、レガシーシステムと移行後のシステムの動作が徐々に乖離していくことを指します。各移行フェーズでは、個別には許容範囲内に見える小さな変更が、時間の経過とともに蓄積され、大きな差異へと発展していく可能性があります。
このドリフトは、テスト中に検出されないことが多いため、特に危険です。テストは通常、実行パスの全範囲ではなく、特定のシナリオにおける機能的結果を検証します。そのため、ドリフトはまれな状況やエッジケースでのみ表面化する可能性があります。
行動のドリフトを管理するには、実行の継続性を継続的に検証する必要があります。チームは、出力だけでなく、実行パスや意思決定ポイントを環境間で比較する必要があります。この比較は、行動が変化している場所を特定し、その変化が意図的なものかどうかを特定するのに役立ちます。
このプロセスにおいて、実行パス分析は重要な役割を果たします。コンポーネントの移行に伴ってコードパスがどのように変化するかを理解することで、組織はドリフトを制御し、段階的な進捗に対する信頼性を維持できます。このような制御がなければ、移行作業は予測可能な変革ではなく、取り返しのつかない実験になってしまうリスクがあります。
実行の継続性を最優先に考えることで、COBOLの増分抽出は成功します。システムの計算内容だけでなく動作も保存することで、安定性や信頼性を損なうことなく移行を進めることができます。
分散サービス統合が移行リスクの主な要因となる
分散サービスは、柔軟性と拡張性の向上を目的としたモダナイゼーションの一環として、メインフレーム環境に導入されることがよくあります。これらのサービスは段階的な移行を可能にしますが、既存の実行モデルと慎重に連携させないと、大きなリスクを増大させる要因にもなります。COBOLプログラムとJCLワークフローは、決定論的な実行と厳密に制御されたデータ移動を念頭に設計されています。一方、分散サービスは根本的に異なる前提に基づいて動作します。
段階的な移行が進むにつれて、決定論的なメインフレームロジックと非同期分散サービスの共存により、動作上の緊張が生じます。統合ポイントは、実行タイミング、障害処理、データ整合性のセマンティクスが乖離する領域となります。意図的な制御がなければ、これらの乖離は運用リスクを増大させ、移行の進行を遅らせます。特に、レガシーコンポーネントと並行してサービスを段階的に導入する場合は顕著です。
非同期通信と決定論的バッチ実行
分散サービスとメインフレームのワークロードの最も顕著な違いの一つは、通信モデルにあります。メインフレームのバッチ処理は、ステップが事前に定義された順序で実行され、完了状態が既知の、決定論的な実行シーケンスに従います。一方、分散サービスは非同期メッセージングに依存することが多く、実行順序は保証されず、応答が遅延したり再試行されたりする可能性があります。
非同期サービスを段階的に統合すると、バッチワークフローに組み込まれた前提が成り立たなくなる可能性があります。COBOLプログラムでは、次のジョブステップが実行される前に下流のプロセスが完了することを想定しているのに対し、分散サービスではリクエストを個別に処理する場合があります。この不一致により、部分的な更新、データ競合、あるいはワークフローの停止が発生する可能性があります。
増分移行では、ハイブリッドな実行チェーンが導入されるため、状況はさらに複雑になります。一部のステップは確定的に維持される一方で、他のステップは非同期となり、元のシステムには存在しなかった実行パスが作成されます。確定的なフロー向けに設計されたリカバリ手順では、実行中のメッセージや遅延した処理を考慮に入れられない場合があり、運用上の不確実性が増大します。
非同期通信がバッチ実行とどのように相互作用するかを理解することは、安全な移行にとって不可欠です。この理解がなければ、分散サービスは非決定性をもたらし、従来のワークフローの予測可能性を損ないます。
再試行セマンティクスと従来の前提への影響
分散サービスでは、回復力を向上させるために再試行メカニズムが一般的に実装されています。一時的な障害、タイムアウト、またはネットワークの問題が発生した場合、リクエストは自動的に再試行されることがあります。これらの再試行は最新のシステムでは効果的ですが、レガシーコンポーネントの前提に反する可能性があります。
COBOLプログラムとJCLワークフローは、通常、呼び出しごとに1回の実行を想定しています。分散サービスがメインフレーム処理をトリガーする操作を再試行すると、更新の重複や不整合な状態が発生する可能性があります。再試行は必ずしもシミュレートされていない障害条件下で発生するため、これらの問題はテスト中に検出するのが困難です。
段階的な移行では、レガシーロジックと並行して新しいサービスが導入されるため、このリスクにさらされる可能性が高まります。チームは、移行されたコンポーネントが以前は存在しなかった再試行動作の対象になっていることに気付かない可能性があります。時間が経つにつれて、これはデータ異常につながり、移行に対する信頼性を損なう可能性があります。
再試行セマンティクスの管理には、分散コンポーネントとメインフレームコンポーネント間の明示的な連携が必要です。レガシーシステムは、冪等性制御または統合設計を通じて、意図しない再実行から保護する必要があります。こうした対策がなければ、再試行は暗黙のリスク増幅要因となります。
スキーマドリフトと契約進化の課題
システム間のデータ契約は、特に段階的な移行シナリオにおいては、静的になることはほとんどありません。分散サービスは急速に進化し、新たな要件を反映したスキーマの変更が頻繁に発生します。しかし、レガシーシステムは適応性が低く、固定されたレコードレイアウトに依存している場合があります。
スキーマドリフトは、分散サービスとメインフレームコンポーネントの整合性が崩れたときに発生します。サービス内で追加または再解釈されたフィールドがCOBOLプログラムで認識されず、解析エラーや誤った処理につながる可能性があります。段階的な移行では、サービスが独立して進化するにつれて、これらの問題が散発的に発生する可能性があります。
プラットフォーム間で明示的な契約が遵守されていないことが、この課題をさらに複雑にしています。分散サービスは柔軟なシリアル化形式に依存する一方で、メインフレームのプログラムは厳格なレイアウトを要求します。厳密な調整がなければ、スキーマの変更は予期せぬ形で伝播してしまいます。
この問題は、 データエンコーディングの不一致の処理データ表現の微妙な違いが統合を阻害するケースがあります。段階的な移行では、統合の失敗を防ぐためにスキーマのずれを積極的に管理する必要があります。
レイテンシ増幅と障害伝播
分散サービスは、従来のメインフレーム処理では見られないネットワーク遅延と部分的な障害モードをもたらします。メインフレームのコンポーネントは、制御された環境内で高スループットと低遅延を実現するように設計されていますが、分散統合は変動性をもたらします。
レイテンシ増幅は、分散サービスにおける遅延が実行チェーンを通じて連鎖的に伝播することで発生します。サービスからの応答が遅いと、バッチ処理の進行が阻害されたり、オンラインパフォーマンスが低下したりする可能性があります。段階的な移行では、システムがこれらの影響に徐々にさらされるため、予測が困難になります。
障害の伝播もより複雑になります。一時的なサービス障害は、バッチの遅延、オンライントランザクションエラー、あるいはデータ状態の不整合といった波及効果をもたらす可能性があります。復旧手順はこれらの相互作用を考慮する必要がありますが、多くの場合、単一のプラットフォームを前提として設計されています。
段階的な移行は、分散サービスが従来の実行セマンティクスに与える影響を十分に認識した上で統合された場合にのみ成功します。この認識がなければ、新しいサービスが追加されるたびに、移行作業の複雑さとリスクが増大します。
したがって、分散サービス統合は単なる技術的な詳細ではなく、段階的な移行の成功を左右する中心的な要素です。その影響を制御することは、プラットフォーム間でモダナイズを行いながら安定性を維持するために不可欠です。
システム全体の停止や並列実行を伴わない増分移行
メインフレームの段階的移行を推進する最も強力な要因の一つは、本番運用を中断することなく近代化を進める必要性です。大企業では、システムを長期間停止したり、完全な並列環境を無期限に稼働させたりできる選択肢はほとんどありません。ビジネスサイクル、規制上の義務、そして顧客の需要に応えるために、コアシステムが進化しても継続的な可用性が求められます。
しかし、システムのフリーズや長時間の並行実行を回避するには、独自の技術的課題が生じます。段階的な移行では、継続的な進捗と運用の継続性のバランスを取り、本番環境を不安定にすることなく変更を導入、検証し、必要に応じて元に戻す必要があります。このバランスを実現するには、実行範囲の慎重な管理、明確なロールバック境界、そして共存が時間の経過とともにシステムの動作に及ぼす影響を理解することが不可欠です。
運用上のリスクを制限する安全な移行増分を定義する
増分移行は、各移行ステップが境界が明確で制御可能な変更を表す場合に成功します。このような増分を定義することは、移行するプログラムやサービスを個別に選択するよりもはるかに複雑です。安全な増分は、実行依存関係、データの所有権、そしてコード境界を超えた障害セマンティクスを考慮する必要があります。
実際には、移行範囲が技術的な都合のみに基づいて定義されている場合、安全でない増分がしばしば発生します。COBOLプログラムが自己完結的であるように見えるという理由でプログラムを抽出すると、より大きな実行チェーンにおけるその役割が無視される可能性があります。このようなプログラムを移行すると、下流のシステムが負荷や障害発生時に異なる動作をする可能性が高くなり、運用上のリスクが増大します。
安全な増分は、変更による運用への影響範囲を制限することで定義されます。これは、移行されたコンポーネントが、大規模な復旧作業を強いられることなく、独立して障害を起こさないことを意味します。これを実現するには、どのコンポーネントが実行パスを共有しているか、どの変更が新たな依存関係をもたらしているか、そしてロールバックの境界がどこに存在するかを把握する必要があります。
この規律がなければ、段階的な移行は制御された変革ではなく、リスクの高い実験となってしまいます。チームは移行を一時停止したり、システムを安定させるためにアドホックな並列処理を導入せざるを得なくなり、段階的な進歩の本来のメリットが損なわれる可能性があります。
長期並列実行モデルの回避
並列実行は、移行中のリスク軽減戦略としてよく用いられます。レガシーコンポーネントと移行済みコンポーネントを並行して実行することで、チームは動作を比較し、正確性を検証できます。短期的には効果的ですが、長期的には並列化によって運用上の複雑さが生じ、そのメリットが上回ってしまう可能性があります。
並列環境を維持するには、データフローの複製、状態の同期、システム間の差異の調整が必要です。時間の経過とともに、これらの作業は多大な運用リソースを消費し、新たな障害モードを引き起こします。並列システムは整合性が崩れ、比較の信頼性が低下し、インシデント発生時の復旧の複雑さが増す可能性があります。
増分移行は、確実な移行を可能にすることで、長期的な並列処理への依存を最小限に抑えることを目的としています。この確実性は、変更を導入する前に実行動作と影響を把握することで得られます。チームが移行後のシステムの動作を把握していれば、並列実行は長期的な共存ではなく、対象を絞った検証に限定できます。
課題は、並列処理が本当に必要な場合と、安全に削除できる場合を判断することです。明確な基準がなければ、組織は拡張並列処理に頼ることになり、移行が遅れ、コストが増加します。
安定性を維持するロールバック境界の設計
ロールバック機能は、フリーズのない段階的な移行に不可欠です。本番環境に変更が導入された場合、予期しない動作が発生した場合、チームは迅速に元に戻すことができなければなりません。効果的なロールバック境界を設計するには、バージョン管理以上のものが必要です。状態、データ、実行フローに関するアーキテクチャ的な考慮が必要です。
メインフレーム環境では、ロールバックは多くの場合、よく理解されているジョブの再起動とリカバリのメカニズムに依存しています。コンポーネントの移行に伴い、これらのメカニズムは直接適用できなくなる可能性があります。分散システムでは、ロールバックの処理方法が異なり、確定的な再起動ではなく、補償アクションに依存する場合があります。
増分移行では、これらのアプローチを調和させる必要があります。移行したコンポーネントを元に戻してもシステムが不整合な状態にならないように、ロールバックの境界を定義する必要があります。これには、多くの場合、データの変更を分離するか、境界を越えた冪等な動作を保証することが必要になります。
堅牢なロールバック境界を設計しないと、慎重な導入手順が採用され、移行が遅れることになります。チームは徹底的なテストを実施せずに変更を導入することをためらい、価値実現までの時間が長くなります。明確なロールバック戦略があれば、より頻繁かつ確実な移行手順を実現できます。
移行による変化下での継続的な運用
移行中に継続的な運用を維持するには、システムが継続的な変化に対応できる必要があります。コンポーネントがプラットフォーム間を移動すると、負荷パターン、実行タイミング、リソース使用率が変化する可能性があります。こうした変化によって、潜在的なパフォーマンスや競合の問題が顕在化する可能性があります。
したがって、段階的な移行では、機能の正確性だけでなく、運用のダイナミクスも考慮する必要があります。通常負荷では安全な変更でも、ピーク時にはパフォーマンスの低下を引き起こす可能性があります。綿密な監視と分析がなければ、こうした問題は移行手順が完了した後に初めて表面化し、修復が複雑になる可能性があります。
この課題は、 継続的インテグレーション メインフレーム リファクタリング頻繁な変更には規律ある統合プラクティスが求められる。移行環境においても、安定性を確保するために同様の規律が求められる。
変化下における継続的な運用には、移行手順が観測可能で、可逆性があり、かつ分離されていることが求められます。これらの条件が満たされている場合、段階的な移行は、フリーズや長時間の並列処理なしに進めることができます。これらの条件が満たされていない場合、組織は保守的な戦略を余儀なくされ、段階的な変革によるアジリティのメリットが損なわれます。
システム停止を伴わない段階的な移行は実現可能ですが、運用上の現実を第一の制約として扱うことが条件となります。安全な増分を定義し、並列処理を制限し、ロールバック境界を設計し、継続的な運用を考慮することで、組織は安定性を犠牲にすることなく着実に近代化を進めることができます。
メインフレームの段階的移行のための Smart TS XL と決定論的洞察
COBOL、JCL、分散サービスにわたるメインフレームの段階的移行は、変更導入前のシステム理解の質によって成否が分かれます。実行動作、依存関係、データフローが部分的にしか理解されていない環境では、移行の意思決定は大きな前提に依存します。こうした前提はフェーズをまたいでリスクを蓄積させ、チームは作業の進捗を遅らせたり、段階的モデルを阻害する補償制御を導入せざるを得なくなります。
Smart TS XLは、実行時観察ではなく、静的および影響分析から得られる決定論的なシステムインサイトを提供することで、この課題に対処します。段階的な移行におけるSmart TS XLの役割は、変換を自動化することではなく、実行パス、依存関係、およびクロスプラットフォームの相互作用を明示的にすることで不確実性を軽減することです。この明確化により、移行チームは、複雑に絡み合ったレガシー資産であっても、段階的な抽出と統合を自信を持って計画できます。
COBOL と JCL にわたる事前計算実行インテリジェンス
Smart TS XLが増分移行にもたらす主なメリットの一つは、COBOLプログラムとその周囲のJCLワークフロー全体にわたる実行インテリジェンスを可視化する機能です。Smart TS XLは、プログラムとジョブストリームを別々の成果物として扱うのではなく、それらがどのように相互作用して実際の実行動作を生み出すかを分析します。
この事前計算されたインテリジェンスは、どのプログラムがどのような条件下で実行されるか、ジョブステップがどのように分岐するか、そして再起動と回復のロジックが制御フローにどこで影響を与えるかを明らかにします。移行チームにとって、この情報は抽出境界を定義する際に非常に重要です。これにより、プログラムが、その動作を形作る実行コンテキストから切り離されて移行されることがなくなります。
実行構造を事前に理解することで、チームは安全な移行候補を特定し、複雑なジョブロジックと密接に連携した動作を持つコンポーネントを回避できます。これにより、動作のドリフトの可能性が低減し、移行手順完了後の安定化作業を最小限に抑えることができます。
実行インテリジェンスは、より正確なテスト戦略をサポートします。機能テストだけに頼るのではなく、移行したコンポーネントがレガシー環境で観測された実行パスを維持していることを検証できます。この検証により、稀な状況でのみ発生する微妙な逸脱のリスクを軽減できます。
メインフレームと分散サービス間の依存関係の透明性
増分移行では、メインフレームと分散コンポーネントが長期間共存するハイブリッド実行環境が生まれます。このような環境では、依存関係の透明性が不可欠になります。プラットフォーム間でコンポーネントがどのように相互作用するかを明確に把握できなければ、移行の意思決定は不確実性によって制約を受けます。
Smart TS XLは、言語、ランタイム、実行モデルにまたがる依存関係の洞察を提供します。共有データの使用、間接的な呼び出しパス、条件付き依存関係など、インターフェース定義だけでは把握できない関係を明らかにします。この透明性により、チームはコンポーネントの移行が直接のスコープを超えて及ぼす影響について推論することが可能になります。
例えば、COBOLプログラムの移行は、依存関係分析によって特定のデータ状態やタイミングに依存する分散サービスの下流の利用者が明らかになるまでは、リスクが低いように見えるかもしれません。この洞察を得ることで、チームは移行のシーケンスを調整したり、安定性を維持するための安全策を導入したりすることができます。
依存関係の透明性により、長時間にわたる並列実行の必要性も軽減されます。チームが依存関係の構造を理解することで、変更がどのように伝播するかを予測し、それに応じてカットオーバーを計画できます。この機能により、過度の運用オーバーヘッドなしに段階的な移行が可能になります。
このアプローチは、 静的および衝撃解析関係性を理解することで、より安全な変化が可能になります。移行の文脈においても、同じ原則により、より安全な段階的な変革が可能になります。
行動推測なしで段階的な抽出をサポート
段階的な移行における最も根強い課題の一つは、行動に関する推測です。チームはしばしば不完全な知識に基づいて作業を進め、移行後のモニタリングに頼って問題を検出します。このような事後対応的なアプローチはリスクを増大させ、進捗を遅らせます。
Smart TS XLは、移行シナリオを事前にモデル化することで、推測作業を削減します。実行パスと依存関係を理解することで、コンポーネントの移行時に動作がどのように変化するかを予測できます。この予測により、事後的な修正ではなく、事前の緩和策が可能になります。
段階的な抽出は、実験ではなく、管理されたプロセスになります。チームは、どの動作を維持すべきか、どの動作を安全に変更できるか、どの動作を再設計する必要があるかを特定できます。この明確さにより、ロールバックサイクルを繰り返すことなく、着実な進歩が可能になります。
行動洞察はチーム間のコミュニケーションも改善します。移行に関する意思決定が共通の理解に基づいている場合、メインフレームチームと分散チーム間の連携がより効果的になります。この連携により、摩擦が軽減され、移行スケジュールが加速されます。
エンジニアリング分野として段階的な移行を可能にする
最終的に、Smart TS XLは、メインフレームの段階的な移行を、アドホックな作業からエンジニアリングの専門分野へと変革することをサポートします。システムの動作に関する一貫性のある決定論的な洞察を提供することで、チームは移行フェーズ全体にわたって繰り返し可能なプラクティスを適用できるようになります。
この規律は、移行計画の明確化、成果の予測可能性の向上、そして安定化作業におけるばらつきの低減に繋がります。移行ステップはより小規模で安全になり、評価も容易になります。組織は時間の経過とともに、本番環境の安定性を損なうことなくモダナイズできるという自信を深めていきます。
Smart TS XLは、アーキテクチャ上の判断やドメイン専門知識に取って代わるものではありません。むしろ、直感ではなく証拠に基づいて意思決定を行うことで、それらの有効性を高めます。複雑なハイブリッド環境において、この根拠は長期にわたる移行プログラム全体を通して推進力を維持するために不可欠です。
Smart TS XL は、不確実性を低減し、システム構造を公開することで、信頼性、制御性、継続性を保ちながら、段階的なメインフレーム移行を可能にします。
漸進的な実験から予測可能なメインフレーム変革へ
メインフレームの段階的な移行プロジェクトの多くは、管理された実験から始まります。プログラムの小さなサブセットを移行したり、限定的な統合を導入したり、特定のワークロードをモダナイズして実現可能性を検証したりします。こうした実験は技術的には成功することが多いものの、スケールアウトには失敗することが多々あります。個別のコンポーネントで有効な方法が、そのまま資産全体にわたる反復可能な変革アプローチに繋がるとは限りません。
段階的な移行が実験段階から規律あるエンジニアリングプラクティスへと進化することで、予測可能なメインフレーム変革が実現します。この変化には、移行に関する意思決定方法、成果の評価方法、そしてフェーズ全体にわたる教訓の適用方法における一貫性が求められます。この規律がなければ、組織はパイロットモードにとどまり、リスクを増大させることなく進捗を加速することができません。
異機種システム間の移行決定の標準化
段階的な移行をスケールさせる上での重要な課題の一つは、標準化された意思決定基準の欠如です。各移行ステップは、多くの場合、ローカルな知識や差し迫った制約に基づいて個別に評価されます。この柔軟性は初期段階の実験には役立ちますが、移行範囲が拡大するにつれて一貫性が失われます。
異機種混在環境では、COBOLプログラム、JCLワークフロー、分散サービスは、複雑さと重要度が大きく異なります。移行準備状況を評価するための共通のフレームワークがなければ、チームは比較や再現が困難な意思決定を下すことになります。あるチームは積極的に移行を進める一方で、別のチームは保守的なアプローチを採用し、進捗にばらつきが生じる可能性があります。
標準化とは、厳格なルールを定めることを意味するものではありません。むしろ、依存関係の密度、実行パスの複雑さ、障害の影響といった共通の評価基準を定義することを意味します。これらの基準が一貫して適用されることで、移行に関する意思決定はシステム間で比較可能になります。
この一貫性により、社内の摩擦が軽減され、計画の精度が向上します。関係者は移行のリスクと労力をより明確に把握できるため、より現実的なタイムラインを設定できます。標準化された意思決定により、段階的な移行は、時間の経過とともに、一連の個別の賭けから、調整された変革プログラムへと変化します。
安定化の取り組みを実行可能なフィードバックに変える
移行の初期段階では、多くの場合、大幅な安定化作業が必要になります。問題が発見され、回避策が適用され、許容可能な動作を回復するためにシステムを調整します。多くの組織では、この作業は洞察の源ではなく、一時的なコストとして扱われています。
安定化の成果が体系的に把握されていない場合、チームは後続のフェーズで同じミスを繰り返します。同様の問題が再発し、時間がかかり、信頼が損なわれます。段階的な移行は、各ステップが最初のステップと同じくらいリスクが高いと感じられるため、停滞してしまいます。
予測可能な変革には、安定化に向けた取り組みを実用的なフィードバックに変換する必要があります。チームは、問題が発生した理由、どの前提が不適切であったか、そして将来の移行で同様の問題を回避できる方法を分析する必要があります。このフィードバックループにより、運用上の苦労がエンジニアリングの知識へと変わります。
このプロセスにより、時間の経過とともに移行ステップごとの安定化作業が削減されます。パターンが特定され、積極的に対処されるにつれて、移行はよりスムーズで予測可能になります。初期段階からの学習に投資する組織は、リスクを増大させることなく、後期段階の移行を加速させることができます。
実行に関する理解を共有し、チームを連携させる
段階的な移行は組織の境界を越えます。メインフレームの専門家、分散システムエンジニア、運用チーム、そしてビジネス関係者全員が成功に貢献します。これらのグループ間の連携の不一致は、摩擦や遅延の一般的な原因となります。
実行に関する共通の理解は、連携の基盤となります。チームがシステムの現在の動作と移行後の期待される動作について合意すれば、連携が向上します。意思決定は、矛盾する心象ではなく、共有されたモデルに基づいて行われます。
この連携により、引き継ぎの遅延が短縮され、手戻り作業が最小限に抑えられます。依存関係と実行フローについて共通の理解に基づいて作業を進めるため、チームはより効果的に連携できます。その結果、移行手順はよりスムーズに進行します。
整合性の確保は、技術系以外のステークホルダーとのコミュニケーションにも役立ちます。移行の成果が実行の継続性とリスク軽減の観点から説明されることで、期待がより明確になります。この明確化は、長期的な変革プログラムへの継続的な投資とコミットメントを支えます。
繰り返しと予測可能性を通じて自信を築く
大規模な移行には、自信が不可欠です。初期の成功は熱意を生み出すかもしれませんが、自信が持続するのは、結果が長期にわたって予測可能である場合のみです。過去の経験に関わらず、移行の各ステップが不確実であると感じた場合、組織は勢いを失います。
予測可能性は、予期せぬ事態を減らし、自信を育みます。チームが課題を予測し、一貫して対処できれば、移行に伴うストレスは軽減され、より日常的なものになります。この変化は組織の行動を変化させます。チームは複雑なコンポーネントに取り組む意欲を高め、難しい意思決定を無期限に先延ばしにする傾向が減ります。
繰り返しの積み重ねによって、この自信は強化されます。移行手順が慣れ親しんだパターンに沿って進むにつれて、チームはアプローチを洗練させ、効率性を向上させます。変革は加速し、実験段階から実行段階へと進んでいきます。
この進化は、 段階的な近代化戦略予測可能性によって拡張性を実現します。段階的なメインフレーム移行は、一連の個別の実験ではなく、反復可能なエンジニアリング手法になったときに、その真価を発揮します。
意思決定の標準化、安定化からの学習、チームの連携、そして反復による信頼の構築により、組織は段階的な移行を予測可能な前進へと変革します。この変革により、ミッションクリティカルなシステムに求められる安定性を犠牲にすることなく、持続的なモダナイゼーションが可能になります。
COBOL および JCL の増分移行中のデータフローの断片化
データフローの断片化は、メインフレームの段階的な移行において、目に見えにくいながらも最も大きな混乱を引き起こす課題の一つです。COBOLプログラムとJCLワークフローは段階的に移行されるため、データの所有権と処理責任はプラットフォーム間で分割されることがよくあります。この断片化は構造レベルでは管理可能に見えるかもしれませんが、放置すると動作の複雑さを招き、安定性を損なうことになります。
レガシー環境では、データフローは実行ロジックと並行して進化してきました。バッチサイクル、データセットのライフサイクル、そしてプログラムのシーケンス処理が一体となって、データが予測可能なパターンで生成、変換、そして消費されることを保証していました。しかし、増分移行は、新たな実行コンテキストと部分的な所有権モデルを導入することで、これらのパターンを崩してしまいます。明確な制御がなければ、断片化されたデータフローは不整合の原因となり、移行を遅らせ、運用リスクを増大させます。
プラットフォーム間での部分的なデータ所有権
増分移行では、データ所有権が部分的に発生することがよくあります。つまり、一部のレコードは移行されたコンポーネントによって作成または更新される一方で、他のレコードは従来の管理下に置かれます。この所有権の分割により、以前は暗黙的に想定されていた前提が複雑化します。COBOLプログラムやJCLワークフローでは、特定の時間帯におけるデータセットへの排他アクセスが前提とされることがよくありますが、分散サービスが導入されると、この前提はもはや成り立ちません。
部分的な所有権は、特定のデータ要素についてどのシステムがどの時点で権限を持っているかという曖昧さを生み出します。通常の運用では、この曖昧さは隠されたままになる場合があります。しかし、障害発生時や照合サイクル中には、不整合が表面化し、手動での介入による解決が必要になります。
この課題は、所有権の境界がビジネスセマンティクスと一致していない場合にさらに深刻化します。関連するデータドメインを移行せずに技術コンポーネントを移行すると、ロジックとデータの責任が不整合になる状況が発生します。その結果、チームはプラットフォーム間で連携して一貫性を確保する必要があり、運用上のオーバーヘッドが増加します。
効果的な増分移行には、データの所有権を明確にし、移行フェーズと整合させる必要があります。この整合がなければ、データフローの断片化によって微妙なエラーが発生し、移行結果の信頼性が損なわれます。
バッチ駆動型データパイプラインにおける時間的断片化
バッチ駆動型データパイプラインは、時間的な調整に大きく依存しています。データは特定の時点で完全かつ一貫性があり、利用可能であることが期待されます。増分移行は、実行タイミングの変更や新たな処理ステージの導入によって、この調整を阻害します。
バッチパイプラインの一部を移行すると、実行時間が変化する可能性があります。分散処理フレームワークはメインフレームのジョブよりも速くまたは遅く完了することがあり、データの可用性ウィンドウがシフトします。特定のタイミングの仮定に依存する下流のプロセスでは、不完全なデータや古いデータが発生する可能性があります。
時間的断片化は断続的に発生することが多いため、診断が特に困難です。通常の状況では、タイミングの差は無視できる程度です。しかし、ピーク負荷時や障害復旧時には、遅延が蓄積され、隠れた依存関係が顕在化します。
時間的な断片化に対処するには、データの依存関係だけでなく、タイミングの依存関係も理解する必要があります。移行チームは、タイミングに関する前提がどこに存在するかを特定し、それらが明示的に維持または調整されていることを確認する必要があります。この努力がなければ、増分移行によって競合状態が発生し、データの整合性が損なわれます。
データの重複と相違のリスク
リスクを軽減するため、組織は増分移行中にデータを複製することがあります。レガシーシステムはデータセットを生成し続けますが、移行されたコンポーネントは並列コピーを維持します。複製は短期的な安全性を確保できますが、長期的にはデータの相違リスクをもたらします。
重複したデータセット間の整合性を維持するには、複雑で脆弱な同期メカニズムが必要です。わずかな遅延や障害によってデータセットがばらばらになり、整合性の確保が困難になり、データの正確性に対する信頼が失われる可能性があります。
移行フェーズが積み重なるにつれて、相違リスクは増大します。ハイブリッド環境に新しいコンポーネントが追加されるたびに、同期ポイントの数が増加します。時間の経過とともに、これらのポイントの管理は運用上の大きな負担となります。
この問題は、 増分データ移行計画部分的なデータ移動は慎重に制御する必要があります。データの重複が最小限に抑えられ、所有権の移行が明確に定義されている場合、増分移行はメリットをもたらします。
エンドツーエンドのデータフローの可視性の回復
断片化されたデータフローは、システムがデータをどのように移動するかの可視性を損ないます。レガシー環境では、経験豊富なチームはジョブスケジュールやプログラムシーケンスに基づいてデータ系統を推測できました。しかし、増分移行では、処理を複数のプラットフォームに分散させることで、この系統が不明瞭になります。
エンドツーエンドの可視性がなければ、データの問題の診断には時間がかかり、エラーが発生しやすくなります。チームはシステム間でデータを手動で追跡する必要があり、インシデント発生時のMTTRが増加し、移行の進行が遅れます。
可視性を回復するには、レガシーコンポーネントと移行済みコンポーネントの両方にわたるデータフローをマッピングする必要があります。このマッピングにより、チームはデータがどこから発生し、どのように変換され、どこで消費されるかを理解できます。これにより、不整合をより効率的に特定し、解決できるようになります。
データフローの可視性は、移行計画の精度向上にも役立ちます。チームがデータフローがフェーズ間でどのように変化するかを理解することで、断片化を最小限に抑える移行手順を設計できます。このアプローチは、時間の経過とともに複雑さを軽減し、運用を安定させます。
データフローの断片化は、段階的な移行に伴う必然的な結果ではありませんが、一般的には発生します。COBOLおよびJCLワークロードがプラットフォーム間で進化していく中で、一貫性、信頼性、そして推進力を維持するためには、この問題に積極的に対処することが不可欠です。
段階的な移行フェーズ全体にわたって障害セマンティクスを保持する
障害セマンティクスは、何か問題が発生した場合のシステムの動作を定義します。従来のメインフレーム環境では、これらのセマンティクスは実行フロー、ジョブ制御、運用手順に深く組み込まれています。リスタートポイント、エラーコード、条件分岐、そしてリカバリロジックは、障害の検出、封じ込め、そして解決方法を総合的に決定します。これらのセマンティクスが意図せず変更された場合、段階的な移行においてリスクが生じます。
移行フェーズ全体にわたって障害のセマンティクスを維持することは、運用の安定性にとって不可欠です。機能的な動作に変化が見られない場合でも、障害の伝播や処理方法の違いによって予期せぬ結果が生じる可能性があります。したがって、段階的な移行では、障害の挙動を最優先事項として扱い、成功パスだけでなくエラーシナリオにおいても継続性を確保する必要があります。
アプリケーションコードの外部に埋め込まれた再起動および回復ロジック
メインフレーム環境では、再起動およびリカバリロジックは、アプリケーションコード内に集中化されるのではなく、JCL、スケジューラ構成、および運用規則に分散されることがよくあります。COBOLプログラムは、部分実行、チェックポイント、および再実行の管理に外部メカニズムを利用する場合があります。これらのメカニズムは、システムが手動介入なしに障害から回復する方法を定義します。
増分移行では、アプリケーションロジックに重点が置かれ、こうした外部リカバリ構造が軽視されることがよくあります。コンポーネントを移行した場合、ターゲット環境に同等の再起動動作が存在しない可能性があります。分散システムでは、ステートレス再試行や補償トランザクションなど、異なるリカバリパラダイムが採用されることがよくあります。
この不一致はリスクをもたらします。以前は単純な再実行で復旧できた障害が、今では複雑な手動介入が必要になる場合があります。運用チームは、確立された手順がもはや適用できないことに気づき、インシデント発生時のダウンタイムが増加する可能性があります。
再起動セマンティクスを維持するには、リカバリロジックが現在どこに存在するかを特定し、それが明示的に複製または適応されていることを確認する必要があります。リカバリ動作が包括的に文書化されることは稀であるため、この作業は容易ではありません。これは、コード、ジョブ設計、そして運用慣行の相互作用から生じます。
プラットフォーム間のエラー伝播の違い
エラーの伝播挙動は、メインフレーム環境と分散環境とで大きく異なります。従来のメインフレームシステムでは、エラーは明確に定義された実行コンテキスト内に限定されることが多く、戻りコード、条件コード、そして異常終了処理によって、下流の動作を導く構造化されたシグナルが提供されます。
分散システムでは、エラーの伝播の仕方が異なります。例外がサービス層を越えて伝播したり、再試行によって本来の原因が不明瞭になったり、部分的な障害が明確なシグナルなしに継続したりすることがあります。段階的な移行により、これらの異なるセマンティクスが共存するハイブリッドな実行パスが生まれます。
慎重な管理を行わないと、コンポーネントの移動時にエラー信号が失われたり、誤って解釈されたりする可能性があります。かつてバッチジョブを停止させた障害が、今度は再試行を引き起こし、問題が隠蔽される可能性があります。逆に、一時的な分散エラーが、レガシーコンポーネントにおいて重大な障害として表面化してしまうこともあります。
エラーの伝播を理解し、整合させることは、期待される動作を維持するために不可欠です。チームは、現在実行パスにおけるエラーの流れをマッピングし、移行後も同等のシグナルが存在することを確認する必要があります。この課題は、 例外処理のパフォーマンスへの影響エラー処理の選択がシステムの動作に影響を与えます。
サイレント障害モードの変化を回避する
段階的な移行における最も危険な結果の一つは、サイレントな障害モードの変化の導入です。これは、システムは正常に動作しているように見えても、障害への対処方法が以前とは異なる場合に発生します。このような変化は、すぐに警告を発することはないかもしれませんが、時間の経過とともに信頼性を低下させる可能性があります。
例えば、移行されたコンポーネントが以前に伝播したエラーを捕捉してログに記録し、下流の安全対策が作動しないようにする可能性があります。あるいは、障害が自動的に再試行され、リソースが枯渇するまで検出が遅れる場合があります。
サイレントチェンジは、特定の条件下でのみ発生することが多いため、テストでは検出が困難です。運用チームは、本番環境でインシデントが発生するまで気づかない可能性があり、その時点では動作の変化によって診断が複雑になります。
サイレントな障害モードの変化を防ぐには、移行前後の障害挙動を明示的に比較する必要があります。チームは、障害が想定通りに発生するだけでなく、それらが同等の方法で処理されることも検証する必要があります。この検証には、従来の障害セマンティクスと、ターゲット環境におけるそれらのセマンティクスを深く理解することが求められます。
移行中の運用ランブックの有効性の維持
運用ランブックは、チームが障害にどのように対応するかを体系化したものです。想定される障害のセマンティクス、復旧手順、そしてシステムの動作に基づいて構築されています。段階的な移行では、対応する更新が行われずに障害の挙動が変化すると、ランブックの有効性が脅かされます。
コンポーネントの移行に伴い、ランブックの一部が時代遅れになる可能性があります。かつては問題を迅速に解決していた手順が、もはや適用できなくなり、混乱や対応の遅れにつながる可能性があります。プレッシャーの大きい状況では、古いランブックに依存することはリスクを増大させます。
ランブックの妥当性を維持するには、運用ドキュメントを移行フェーズと整合させる必要があります。チームは、障害のセマンティクスの変化に応じて手順を更新し、運用スタッフが新しい行動に対応できるようにする必要があります。この取り組みは、技術的な移行計画において見落とされがちです。
効果的な段階的移行では、運用準備が成功の不可欠な要素となります。障害セマンティクスを維持することで運用の継続性が確保され、システム変更があってもチームが効果的に対応できるようになります。
段階的な移行フェーズ全体にわたって障害セマンティクスを維持することで、モダナイゼーションによる信頼性の低下を防ぎます。再起動ロジック、エラー伝播、サイレント障害モード、運用準備状況に対処することで、組織はミッションクリティカルなシステムに求められる安定性を維持しながら、自信を持って移行を行うことができます。
段階的な移行は、技術ではなく行動が主導権を握ったときに成功する
COBOL、JCL、分散サービスにわたるメインフレームの段階的な移行は、しばしば技術的な旅路と表現されますが、その成功は、システムの動作がどれだけ適切に理解され、変更を通じて維持されるかによって決まります。最も重大なリスクは、馴染みのないプラットフォームや最新のツールから生じるのではなく、隠れた実行パス、断片化されたデータフロー、そして移行が進行した後に初めて明らかになる、変更された障害セマンティクスから生じます。これらの動作の側面が見落とされると、段階的な取り組みは予測可能性と勢いを失います。
ハイブリッド環境において、レガシーシステムが価値を提供し続けるのは、その動作が本番環境で安定し、十分に理解されているからです。段階的な移行は、深く結合された実行モデルに部分的な変更を加えることで、この安定性を脅かします。移行の各ステップは、タイミング、依存関係、またはエラー処理を微妙に変化させます。これらの変化に注意深く対応しなければ、組織はモダナイゼーションの目標達成ではなく、運用上の回避策で対応せざるを得なくなります。
段階的な移行を、個々の取り組みの連続ではなく、エンジニアリングの規律として扱うことで、予測可能な変革が実現します。この規律では、迅速な抽出よりも、実行の継続性、依存関係の明確化、そして障害時の挙動の等価性を優先します。移行ステップはより小さく、より安全になり、より容易に理解できるようになります。得られた教訓が体系的に適用されることで、安定化のための労力は軽減され、中断を繰り返すことなく着実に前進することができます。
長年運用されてきたメインフレーム資産を近代化する企業にとって、段階的な移行は依然として最も現実的な進路です。そのメリットは、複雑さを回避することではなく、それを意図的に管理することにあります。動作理解がアーキテクチャの変更につながると、段階的な移行はリスク管理戦略から、運用上の信頼性を維持しながら長期的なシステム進化を可能にする持続可能な近代化モデルへと進化します。