

Aplikacje stają się coraz większe i bardziej złożone, dlatego programiści szukają sposobów na poprawę wydajności i optymalizację doświadczenia użytkownika. Podział kodu rozwiązuje te problemy, zarządzając sposobem i czasem ładowania różnych części kodu aplikacji. Przyjrzyjmy się podziałowi kodu, jego zaletom, metodom implementacji, najlepszym praktykom i narzędziom takim jak SMART TS XL może ułatwić jego przyjęcie, zwłaszcza w kontekście modernizacji starszych aplikacji.
Czym jest dzielenie kodu?
Podział kodu to technika służąca do dzielenia dużych baz kodu na mniejsze, łatwiejsze do zarządzania fragmenty lub pakiety. To podejście pozwala aplikacji załadować tylko niezbędne fragmenty kodu w określonym momencie, zamiast ładować całą bazę kodu od razu. Pomaga to skrócić początkowy czas ładowania, zmniejszyć zużycie pamięci i zapewnić płynniejsze działanie.
Na przykład w aplikacjach jednostronicowych (SPA) cały kod mógłby być tradycyjnie zgrupowany w jednym dużym pliku JavaScript. Wraz z rozwojem aplikacji plik ten staje się większy, co prowadzi do wolniejszego ładowania. Podział kodu rozwiązuje ten problem, dzieląc go na mniejsze fragmenty, umożliwiając aplikacji załadowanie tylko tych, które są wymagane dla bieżącej strony lub funkcjonalności.
Dlaczego podział kodu ma znaczenie
Znaczenie podziału kodu leży w jego możliwości optymalizacji wydajności aplikacji i doświadczenia użytkownika. Duże pakiety kodu mogą znacząco wpływać na czas ładowania, szczególnie w wolniejszych sieciach lub na urządzeniach mobilnych. Zmniejszając ilość kodu, który należy pobrać i wykonać, podział kodu skutkuje szybszymi interakcjami i bardziej responsywną aplikacją. W dzisiejszym środowisku cyfrowym nawet niewielkie opóźnienie w czasie ładowania może spowodować, że użytkownicy porzucą aplikację, co z kolei przełoży się na utratę zaangażowania i potencjalnych przychodów.
Podział kodu pomaga również zminimalizować zużycie pamięci przez aplikację, zapewniając, że w danym momencie do pamięci ładowane są tylko niezbędne moduły. Jest to korzystne w przypadku aplikacji z bogatymi interfejsami o dużej liczbie funkcji, w których nie wszystkie funkcje są potrzebne jednocześnie.
Jak działa dzielenie kodu
Statyczny podział kodu (podział kodu na podstawie tras)
Statyczny podział kodu, znany również jako „podział kodu oparty na trasach”, polega na dzieleniu kodu na fragmenty w trakcie kompilacji, zgodnie z ustalonymi regułami. To podejście jest powszechnie stosowane w aplikacjach internetowych z odrębnymi trasami lub widokami, takich jak aplikacje SPA.
W tej metodzie każda trasa lub główny komponent jest pakowany do osobnego pliku podczas procesu kompilacji. Gdy użytkownik przechodzi do konkretnej trasy, aplikacja ładuje tylko odpowiadający jej pakiet. Statyczny podział kodu jest często implementowany za pomocą programów do pakowania modułów, które automatycznie dzielą kod na osobne pakiety zgodnie ze wskazaniami programisty.
Na przykład w aplikacji React statyczny podział kodu można uzyskać za pomocą składni import(). Poniższy kod pokazuje, jak różne trasy można podzielić na osobne pakiety:
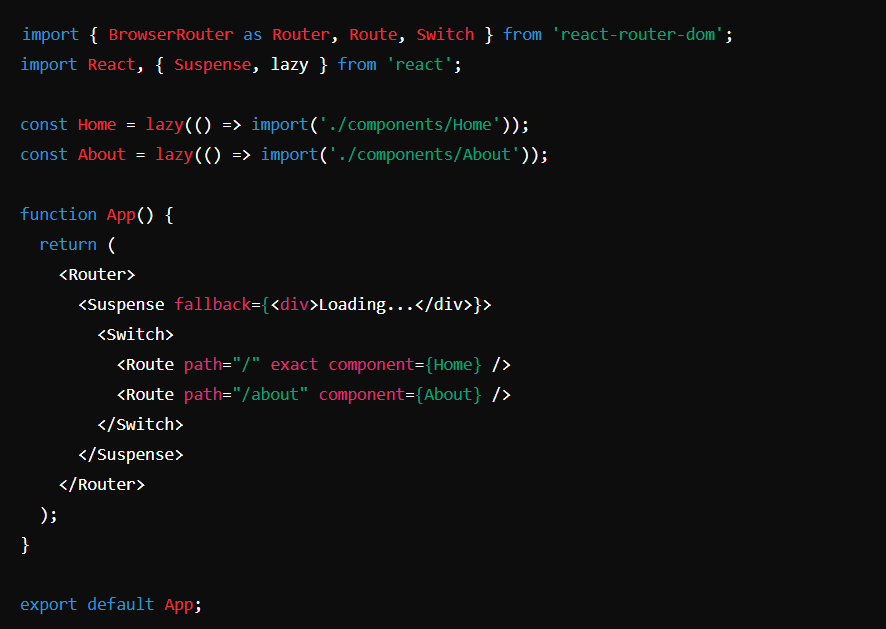
W tym przykładzie komponenty Home i About są podzielone na osobne pakiety. Pakiety te są ładowane dynamicznie, gdy użytkownik przechodzi do odpowiednich tras, co zmniejsza ilość kodu, który trzeba początkowo załadować.
Dynamiczny podział kodu (podział kodu na żądanie)
Dynamiczny podział kodu, znany również jako „na żądanie” lub „leniwe ładowanie”, polega na rozbijaniu kodu w czasie wykonywania na podstawie interakcji użytkownika. Strategia ta wykorzystuje dynamiczne importy (import()) do ładowania określonych fragmentów kodu tylko wtedy, gdy są potrzebne. W przeciwieństwie do statycznego podziału kodu, podział dynamiczny pozwala na bardziej szczegółową kontrolę, umożliwiając programistom dzielenie kodu w obrębie komponentów, a nawet na poziomie funkcji.
Dynamiczny podział kodu jest szczególnie przydatny do ładowania rzadko używanych komponentów, takich jak okna modalne, widżety czy biblioteki innych firm, zmniejszając w ten sposób początkowy rozmiar pakietu. Oto przykład dynamicznego podziału kodu w komponencie React:

W tym przykładzie komponent LazyComponent jest ładowany dopiero po kliknięciu przycisku przez użytkownika. Skraca to początkowy czas ładowania i gwarantuje, że zbędny kod nie zostanie wykonany, dopóki nie będzie to konieczne. Komponent Suspense obsługuje stan ładowania, dostarczając użytkownikowi informacji zwrotnej podczas ładowania komponentu.
Korzyści z podziału kodu
Skrócony początkowy czas ładowania
Jedną z głównych zalet dzielenia kodu jest skrócenie początkowego czasu ładowania aplikacji. Dzieląc bazę kodu na mniejsze fragmenty, przeglądarka pobiera tylko niezbędny kod potrzebny do wyświetlenia pierwszego ekranu lub interakcji z użytkownikiem. Skutkuje to szybszym początkowym ładowaniem, ponieważ przeglądarka nie musi przetwarzać dużych, monolitycznych plików przed renderowaniem aplikacji.
W aplikacjach jednostronicowych (SPA), gdzie wszystkie komponenty są tradycyjnie połączone, podział kodu pozwala aplikacji załadować tylko te komponenty, które są niezbędne dla bieżącego widoku. To znacznie skraca czas do pierwszego sensownego wyświetlenia, poprawiając postrzeganą wydajność i responsywność aplikacji.
Zwiększona wydajność aplikacji
Podział kodu optymalizuje wydajność aplikacji poprzez zmniejszenie zużycia pamięci i ilości kodu JavaScript, który należy wykonać. Dzięki ładowaniu kodu w mniejszych segmentach, aplikacja minimalizuje obciążenie zasobów systemowych, co przekłada się na płynniejszą interakcję, szczególnie na urządzeniach o ograniczonej mocy obliczeniowej.
Podczas gdy użytkownicy poruszają się po różnych częściach aplikacji, podział kodu gwarantuje, że ładowane są tylko niezbędne fragmenty, gdy jest to potrzebne. Ten mechanizm ładowania na żądanie zapobiega niepotrzebnemu wykonywaniu kodu, co może poprawić ogólną wydajność i prowadzić do bardziej responsywnego działania użytkownika.
Efektywne zarządzanie zasobami
Dzięki rozdzielaniu kodu, w danym momencie do pamięci ładowane są tylko niezbędne moduły lub funkcje. To selektywne ładowanie zapewnia bardziej efektywne wykorzystanie zasobów systemowych, a w szczególności pamięci. Jeśli aplikacja nie załaduje całego kodu z góry, system może przydzielić zasoby do działających komponentów, unikając potencjalnych spowolnień spowodowanych nadmiernym wykorzystaniem pamięci.
Ten aspekt jest szczególnie cenny w przypadku aplikacji bogatych w funkcje i posiadających złożone interfejsy użytkownika. Dzięki efektywnemu zarządzaniu zasobami aplikacja może obsługiwać więcej funkcji bez spadku wydajności.
Szybsze kolejne ładowania dzięki buforowaniu
Kolejną kluczową zaletą dzielenia kodu jest usprawnione buforowanie. Gdy aplikacja jest podzielona na wiele mniejszych pakietów, przeglądarka może buforować poszczególne fragmenty. Podczas kolejnych wizyt wystarczy pobrać tylko nowe lub zaktualizowane fragmenty. Oznacza to, że niezmienione części aplikacji będą już w pamięci podręcznej przeglądarki, co skróci czas ładowania dla powracających użytkowników.
W tradycyjnych aplikacjach monolitycznych każda drobna zmiana wymagałaby od użytkowników ponownego pobrania całego pakietu. Podział kodu rozwiązuje ten problem, zapewniając ponowne pobranie tylko zmienionych fragmentów, co zmniejsza zużycie danych i przyspiesza kolejne interakcje.
Poprawiona skalowalność i łatwość utrzymania
Podzielenie aplikacji na mniejsze, łatwe w zarządzaniu moduły z natury ułatwia jej utrzymanie i skalowanie. Podział kodu sprzyja modułowemu projektowaniu, w którym programiści koncentrują się na budowaniu i aktualizowaniu poszczególnych fragmentów kodu. Taka modułowość upraszcza proces debugowania, ponieważ problemy można ograniczyć do konkretnych części aplikacji.
W miarę rozwoju aplikacji i wprowadzania nowych funkcji, programiści mogą dzielić dodatkowe moduły na nowe fragmenty, bez wpływu na wydajność istniejącego kodu. Takie podejście umożliwia ciągły rozwój i wdrażanie, umożliwiając bardziej efektywne skalowanie aplikacji.
Płynniejsze wrażenia użytkownika
Podczas interakcji z aplikacją użytkownicy oczekują płynnego działania i minimalnych opóźnień. Podział kodu przyczynia się do płynniejszego działania poprzez asynchroniczne ładowanie nowych modułów w tle, podczas gdy użytkownicy poruszają się po różnych częściach aplikacji. Dzięki wstępnemu ładowaniu lub wstępnemu pobieraniu kodu na potrzeby kolejnych możliwych interakcji, aplikacja może zapewniać niemal natychmiastowe odpowiedzi, redukując odczuwalne opóźnienia.
Na przykład w aplikacji internetowej podział kodu pozwala na szybkie załadowanie strony początkowej, podczas gdy wstępne pobieranie w tle ładuje dodatkowe zasoby. Ta strategia zapewnia, że kolejne nawigacje wydają się szybkie i płynne, ponieważ niezbędny kod został już załadowany, zanim użytkownik o to poprosi.
Lepsze zarządzanie złożonymi aplikacjami
W aplikacjach na dużą skalę zarządzanie złożonymi funkcjonalnościami może prowadzić do przytłaczającego, dużego pakietu kodu, który obniża wydajność. Podział kodu rozwiązuje ten problem, umożliwiając programistom podzielenie tych złożonych funkcjonalności na mniejsze, niezależne moduły, które można załadować w razie potrzeby.
Taka modularność gwarantuje, że podczas interakcji z użytkownikiem przetwarzane są tylko istotne fragmenty kodu, co zapobiega powstawaniu wąskich gardeł wydajnościowych. Dzięki takiemu zarządzaniu złożonością, podział kodu umożliwia programistom tworzenie rozbudowanych aplikacji z dużą liczbą funkcji bez obniżania wydajności.
Większa elastyczność aktualizacji funkcji
Podział kodu zapewnia elastyczność podczas aktualizacji lub dodawania funkcji do aplikacji. Ponieważ różne funkcje są izolowane w osobnych fragmentach, programiści mogą modyfikować lub wprowadzać nowe funkcjonalności bez wpływu na cały kod. To rozdzielone podejście minimalizuje ryzyko wprowadzenia błędów i gwarantuje, że zmiany mają ograniczony wpływ na inne części aplikacji.
Po dodaniu nowej funkcji można ją umieścić w osobnym fragmencie, który można dynamicznie załadować w razie potrzeby. To nie tylko przyspiesza proces wdrażania, ale także zmniejsza prawdopodobieństwo wystąpienia problemów z regresją w istniejących funkcjach.
Zoptymalizowane wykorzystanie sieci
Ograniczając początkowy rozmiar pakietu, podział kodu optymalizuje wykorzystanie sieci. Jest to szczególnie korzystne dla użytkowników wolniejszych połączeń lub urządzeń mobilnych, gdzie duże pakiety mogą prowadzić do wydłużenia czasu ładowania. Ponieważ pobierany jest tylko kod niezbędny do bieżącej interakcji użytkownika, zasoby sieciowe są wykorzystywane bardziej efektywnie.
Ponadto, dzięki wstępnemu ładowaniu lub pobieraniu zasobów na podstawie przewidywanego zachowania użytkownika, podział kodu gwarantuje, że aplikacja pobiera tylko to, co jest niezbędne, unikając w ten sposób marnowania przepustowości, które wiąże się z pobieraniem nieużywanych modułów.
Ułatwia wdrażanie progresywnych aplikacji internetowych (PWA)
Dla programistów tworzących progresywne aplikacje internetowe (PWA) podział kodu jest niezbędny. Celem PWA jest zapewnienie wrażeń zbliżonych do aplikacji internetowych, z krótkim czasem ładowania i możliwością pracy w trybie offline. Podział kodu wspiera ten cel, zmniejszając rozmiar początkowego pliku do pobrania i umożliwiając dynamiczne ładowanie treści w oparciu o interakcję użytkownika. Działa on również bezproblemowo z mechanizmami Service Worker, które mogą buforować poszczególne fragmenty, ułatwiając dostęp offline i szybkie ładowanie, co dodatkowo usprawnia działanie aplikacji PWA.
Najlepsze praktyki dotyczące dzielenia kodu
Chociaż dzielenie kodu może znacząco poprawić wydajność aplikacji, stosowanie się do najlepszych praktyk maksymalizuje jego korzyści:
Unikaj nadmiernego dzielenia
Podzielenie kodu na zbyt wiele małych fragmentów może prowadzić do nadmiernej liczby żądań sieciowych, co potencjalnie może przynieść więcej szkody niż pożytku. Kluczowe jest znalezienie równowagi między zmniejszeniem rozmiaru pakietu a minimalizacją liczby żądań HTTP.
Grupuj podobne moduły
Dzieląc kod, grupuj podobne moduły, które często są używane razem, w jeden fragment. Zmniejsza to zbędny ładunek i zapewnia dostępność powiązanych funkcji w razie potrzeby.
Zoptymalizuj priorytet obciążenia
Stosuj techniki takie jak preload i prefetch, aby zoptymalizować priorytet ładowania fragmentów kodu. Pomaga to szybciej ładować krytyczne fragmenty, a jednocześnie wstępnie ładować te mniej pilne, co dodatkowo poprawia komfort użytkowania.
Testowanie i profilowanie
Regularnie testuj i profiluj aplikację, aby monitorować wpływ podziału kodu na wydajność. Narzędzia testowe mogą identyfikować wąskie gardła i pomagać optymalizować strategię podziału.
Wyzwania i rozważania
Chociaż dzielenie kodu jest skuteczną techniką zwiększania wydajności aplikacji internetowych, wiąże się z pewnymi wyzwaniami i zagadnieniami. Prawidłowa implementacja dzielenia kodu wymaga starannego planowania i dogłębnego zrozumienia architektury aplikacji, zachowań użytkowników i potencjalnych pułapek. Oto niektóre z głównych wyzwań i zagadnień, z którymi borykają się programiści podczas implementacji dzielenia kodu:
Zwiększona złożoność w zarządzaniu bazą kodu
Jednym z największych wyzwań związanych z dzieleniem kodu jest dodatkowa złożoność, jaką wprowadza on do bazy kodu. Gdy aplikacja jest dzielona na mniejsze, niezależnie ładowane fragmenty, programiści muszą zarządzać czasem i sposobem ładowania tych fragmentów. Wiąże się to z obsługą asynchronicznego ładowania modułów, zapewnieniem płynnej współpracy dynamicznie importowanych komponentów z resztą aplikacji oraz obsługą potencjalnych błędów podczas ładowania.
Ta złożoność może wydłużyć krzywą uczenia się dla nowych programistów dołączających do projektu i utrudnić debugowanie. Błędy w zarządzaniu podzielonym kodem mogą prowadzić do błędów w czasie wykonywania lub nieoczekiwanego zachowania, wpływając na stabilność aplikacji.
Zarządzanie zależnościami i duplikacja kodu
Podczas dzielenia kodu na mniejsze pakiety, kluczowe jest monitorowanie zależności zawartych w każdym fragmencie. Jeśli dwa lub więcej fragmentów ma wspólne zależności, może to doprowadzić do ich oddzielnego uwzględnienia, co doprowadzi do duplikacji kodu w pakietach. Ta redundancja zwiększa całkowity rozmiar plików do pobrania, co może zniweczyć korzyści wydajnościowe wynikające z podziału kodu.
Aby temu zaradzić, deweloperzy muszą zachować czujność analizując ich drzewo zależności i stosując strategie optymalizacji, takie jak wyodrębnianie współdzielonych zależności do osobnych pakietów. Dodaje to jednak dodatkowy poziom złożoności do procesu kompilacji i wymaga regularnego monitorowania w miarę rozwoju aplikacji.
Obsługa stanu ładowania
W przypadku importów dynamicznych komponenty lub moduły są ładowane asynchronicznie. Oznacza to, że może wystąpić opóźnienie między momentem wykonania akcji przez użytkownika (np. przejścia do nowej trasy) a momentem pobrania i wykonania odpowiadającego mu fragmentu kodu. Podczas tego opóźnienia interfejs użytkownika musi płynnie obsłużyć stan ładowania, zazwyczaj wyświetlając symbol ładowania lub symbol zastępczy.
Prawidłowe zarządzanie tym stanem ładowania ma kluczowe znaczenie dla zapewnienia płynnego działania aplikacji. Niewłaściwe zarządzanie może skutkować powolnym, niereagującym interfejsem, co może frustrować użytkowników i skłaniać ich do porzucenia aplikacji. Ponadto programiści muszą radzić sobie z potencjalnymi błędami ładowania (np. awariami sieci) i przekazywać użytkownikom istotne informacje zwrotne w przypadku wystąpienia takich sytuacji.
Równoważenie liczby fragmentów
Podzielenie kodu na zbyt wiele małych fragmentów może prowadzić do nadmiernej liczby żądań sieciowych. Gdy przeglądarka wysyła wiele żądań pobrania każdego fragmentu, może to powodować opóźnienia z powodu opóźnień sieciowych, szczególnie w przypadku wolnych połączeń. Z drugiej strony, tworzenie mniejszej liczby większych fragmentów może poprawić wydajność sieci, ale nadal może skutkować dużymi rozmiarami plików, których pobieranie i analizowanie zajmuje więcej czasu.
Znalezienie właściwej równowagi między liczbą fragmentów a ich rozmiarami jest kluczowe. Często wymaga to od programistów profilowania aplikacji, eksperymentowania z różnymi strategiami fragmentacji i precyzyjnego dostrojenia konfiguracji do konkretnego przypadku użycia. Proces ten jest ciągły, ponieważ zmiany w kodzie aplikacji lub w zachowaniu użytkownika mogą wymagać modyfikacji w sposobie podziału kodu.
Wpływ na wydajność obciążenia początkowego
Chociaż podział kodu może poprawić wydajność ładowania poprzez opóźnienie ładowania określonych fragmentów bazy kodu, czasami, jeśli nie zostanie wdrożony w sposób przemyślany, może przynieść odwrotny skutek. Na przykład, jeśli początkowy fragment ładujący podstawową funkcjonalność aplikacji stanie się zbyt duży, może to spowolnić początkowy czas renderowania. Ponadto, jeśli zbyt wiele krytycznych komponentów zostanie podzielonych na osobne fragmenty, które wymagają natychmiastowego załadowania, może to skutkować wieloma jednoczesnymi żądaniami sieciowymi, potencjalnie opóźniając początkowe renderowanie.
Aby zoptymalizować wydajność początkowego ładowania, programiści muszą starannie dobrać, które części bazy kodu uwzględnić w pakiecie początkowym, a które podzielić na osobne fragmenty. Wymaga to zrozumienia, które komponenty i moduły są niezbędne do pierwszej interakcji z użytkownikiem, a które należy odłożyć na później, aż zaczną być potrzebne.
Buforowanie i wersjonowanie
Buforowanie jest kluczowym czynnikiem wpływającym na poprawę wydajności aplikacji. Dzięki podziałowi kodu, każdy fragment może być buforowany niezależnie, co zmniejsza ilość danych, które trzeba pobrać podczas kolejnych wizyt. Wiąże się to jednak ze złożonością zarządzania pamięcią podręczną i wersjonowaniem. Jak zapewnić, że w przypadku zmian w kodzie ładowane są poprawne, zaktualizowane fragmenty, bez narażania użytkownika na błędy spowodowane przez nieaktualne pliki w pamięci podręcznej?
Prawidłowe strategie omijania buforowania, takie jak stosowanie haszowania treści w nazwach plików, są niezbędne, aby zapewnić użytkownikom zawsze najnowszą wersję każdego fragmentu. Jednak prawidłowe wdrożenie tych strategii wymaga starannego planowania i zrozumienia, w jaki sposób przeglądarki i sieci dostarczania treści (CDN) obsługują buforowanie.
Monitorowanie i analityka
Podział kodu może wpływać na sposób śledzenia i analizowania interakcji użytkowników. Dynamiczne ładowanie fragmentów kodu może utrudniać efektywne monitorowanie zachowań użytkowników, na przykład śledzenie czasu potrzebnego na interakcję określonych funkcji lub mierzenie wpływu poszczególnych fragmentów kodu na wydajność.
Aby temu zaradzić, programiści muszą zintegrować narzędzia do monitorowania i analizy obsługujące dynamiczne ładowanie. Narzędzia te mogą dostarczyć informacji o tym, jak podział kodu wpływa na doświadczenie użytkownika, pomagając programistom w dopracowaniu strategii podziału.
Testowanie i profilowanie
Testowanie aplikacji wykorzystującej podział kodu wymaga dodatkowych rozważań. Programiści muszą upewnić się, że podzielone komponenty bezproblemowo ze sobą współpracują i poprawnie obsługują asynchroniczne stany ładowania. Testy automatyczne powinny obejmować takie scenariusze, jak leniwe ładowanie komponentów, obsługa błędów podczas dynamicznych importów oraz interakcje użytkownika podczas pobierania fragmentów kodu.
Narzędzia profilowania stają się niezbędne do optymalizacji strategii podziału. Programiści muszą regularnie profilować aplikację, aby identyfikować wąskie gardła, monitorować rozmiary fragmentów i analizować żądania sieciowe, aby upewnić się, że podział kodu przynosi pożądane korzyści wydajnościowe.
Wpływ na doświadczenie użytkownika
Ostatecznie celem podziału kodu jest poprawa doświadczenia użytkownika. Jednak niewłaściwe użycie może prowadzić do negatywnych doświadczeń, takich jak opóźnione interakcje, zbyt częste pojawianie się spinnerów ładowania lub nieoczekiwane zachowania podczas nawigacji. Programiści muszą brać pod uwagę ścieżkę użytkownika podczas projektowania strategii podziału kodu, aby zapewnić szybkość, responsywność i płynność działania aplikacji.
W jaki sposób SMART TS XL Może być przydatny do dzielenia kodu
SMART TS XL to zaawansowane narzędzie zaprojektowane do dogłębnej analizy dużych baz kodu, wykrywania wzorców i wskazywania obszarów, które mogą wymagać optymalizacji, modernizacji i restrukturyzacji. Jeśli chodzi o dzielenie kodu, SMART TS XL może określić, które części aplikacji nadają się do podziału i pomóc programistom podejmować świadome decyzje w celu optymalizacji wydajności.
SMART TS XL Identyfikuje również małe, ale często odwoływane pliki. Deweloperzy mogą wykorzystać te informacje, aby określić, czy pliki te można przekształcić w mniejsze, niezależne moduły, które można dynamicznie ładować w razie potrzeby.
Analiza zależności plików i interakcji między programami
Podział kodu może okazać się skomplikowany, gdy występują współzależności między różnymi modułami. SMART TS XLMożliwość mapowania odniesień i interakcji między plikami jest tutaj nieoceniona. Pozwala programistom zrozumieć, które pliki są ściśle powiązane, a które mają szersze zależności w całej aplikacji. Ta wiedza jest niezbędna przy podejmowaniu decyzji o tym, gdzie podzielić kod, aby uniknąć zbędnego ładowania i niepotrzebnej złożoności.
Ujawniając interakcje i zależności, SMART TS XL umożliwia programistom stworzyć przejrzysty kod strategia podziału minimalizująca duplikację kodu w różnych fragmentach, zapewniająca zoptymalizowaną obsługę wspólnych narzędzi i współdzielonych modułów.
Odkrywanie ukrytych złożoności w małych plikach o dużym natężeniu użytkowania
SMART TS XL Potrafią identyfikować małe pliki o zaskakująco dużej liczbie odniesień. Pliki te często reprezentują funkcje narzędziowe używane w całym systemie. Zrozumienie ich roli i rozmieszczenia w bazie kodu pozwala programistom decydować, jak włączyć te narzędzia do strategii podziału kodu.
SMART TS XLMożliwość wykrywania tych wzorców gwarantuje, że podczas podziału kodu brane są pod uwagę nawet często pomijane funkcje użytkowe.
Wsparcie modernizacji starszych wersji dzięki analizie podziału kodu
Starsze aplikacje często zawierają monolityczne struktury z ściśle powiązanymi komponentami. SMART TS XL Doskonale sprawdza się w skanowaniu starszych baz kodu i identyfikowaniu potencjalnych obszarów do modularyzacji. Wskazując obecność dużych plików i mapując ich rozbudowane odwołania, narzędzie pomaga programistom określić priorytety podziału starszych systemów na mniejsze moduły.
Podczas procesu unowocześnianie dziedzictwa bazy kodów, SMART TS XL może pomóc zidentyfikować, które segmenty kodu są najważniejsze dla przepływu danych w systemie, takie jak kluczowe programy oparte na języku Natural lub złożone procedury COBOL. Pozwala to programistom na implementację podziału kodu w sposób, który nie tylko poprawia wydajność, ale także zachowuje integralność starszej logiki.
Monitorowanie potencjalnych redundancji w celu umożliwienia czyszczenia i podziału kodu
SMART TS XL może wykrywać pliki z małą liczbą odniesień i minimalnymi rozmiarami. Mogą one wskaż zbędny lub nieaktualny kod które mogą zaśmiecać system. Czyszcząc takie pliki, programiści mogą usprawnić bazę kodu, ułatwiając tym samym implementację podziału kodu.
Co więcej, SMART TS XLSzczegółowa analiza może pomóc programistom zidentyfikować moduły o nakładających się funkcjonalnościach lub takie, które można skonsolidować. Po skonsolidowaniu lub usunięciu zbędnych plików, pozostała baza kodu staje się bardziej modułowa i nadaje się do podziału.
Strategiczne planowanie podziału kodu
SMART TS XLDane, w tym rozkład rozmiarów plików, liczba referencji i wzorce interakcji, umożliwiają strategiczne planowanie podziału kodu. Programiści mogą wykorzystać te informacje, aby zdecydować, które części aplikacji powinny zostać uwzględnione w pakiecie początkowym, a które mogą być ładowane asynchronicznie. Poprzez korelację liczby referencji z rozmiarami plików, SMART TS XL pomaga zlokalizować „gorące punkty” w aplikacji — moduły, które są duże i intensywnie używane, a które doskonale nadają się do podziału w celu zwiększenia wydajności.
Wniosek
Podział kodu nie jest rozwiązaniem uniwersalnym, lecz dynamicznym narzędziem w zestawie narzędzi programisty. Prawidłowo wdrożony, może przekształcić powolną, monolityczną aplikację w szybki, responsywny i skalowalny system. Poprawia komfort użytkowania, ładując tylko niezbędne fragmenty kodu, zmniejszając zużycie pamięci i optymalizując zarządzanie zasobami. Jednak jego wdrożenie wymaga starannego rozważenia potencjalnych wyzwań, takich jak zwiększona złożoność, obsługa stanów ładowania, zarządzanie zależnościami i równoważenie rozmiarów bloków. Zrozumienie tych wyzwań i przeprowadzenie dogłębnych analiz analiza wpływu, statyczna analiza koduDzięki ciągłym testom i dzieleniu kodu, programiści mogą opanować dzielenie kodu, aby tworzyć wydajne, zorientowane na użytkownika aplikacje. W erze, w której wydajność jest kluczowym czynnikiem różnicującym w cyfrowych doświadczeniach, dzielenie kodu oferuje zaawansowaną metodę, która pozwala utrzymać aplikacje zwięzłe, responsywne i elastyczne w stosunku do zmieniających się wymagań.
SMART TS XL Zapewnia dogłębny wgląd w strukturę i wykorzystanie kodu w systemie oprogramowania, co czyni go niezbędnym narzędziem do podejmowania decyzji dotyczących podziału kodu. Jego zdolność do analizowania rozmiarów plików, liczby odwołań, zależności i interakcji pomaga programistom zidentyfikować krytyczne części aplikacji, które najbardziej skorzystałyby na podziale kodu. Ujawniając ukryte złożoności, monitorując potencjalne redundancje i wspierając modernizację starszych wersji, SMART TS XL Dostarcza programistom wiedzy niezbędnej do optymalizacji aplikacji, redukcji rozmiarów pakietów i skrócenia czasu ładowania. Ostatecznie prowadzi to do bardziej modułowego, skalowalnego i wydajnego systemu, dopasowanego do unikalnych wymagań każdej aplikacji.