

Anwendungen werden immer größer und komplexer, daher suchen Entwickler nach Möglichkeiten, die Leistung zu verbessern und das Benutzererlebnis zu optimieren. Code-Splitting begegnet diesen Herausforderungen, indem es steuert, wie und wann verschiedene Teile des Codes einer Anwendung geladen werden. Erkunden Sie Code-Splitting, seine Vorteile, Implementierungsmethoden, Best Practices und wie Tools wie SMART TS XL kann deren Einführung erleichtern, insbesondere im Zusammenhang mit der Modernisierung älterer Anwendungen.
Was ist Code-Splitting?
Code-Splitting ist eine Technik, mit der große Codebasen in kleinere, handhabbare Teile oder Pakete aufgeteilt werden. Mit diesem Ansatz kann eine Anwendung zu einem bestimmten Zeitpunkt nur die erforderlichen Teile ihres Codes laden, anstatt die gesamte Codebasis im Voraus zu laden. Dies trägt zur Verbesserung der anfänglichen Ladezeit bei, reduziert den Speicherverbrauch und sorgt für ein reibungsloseres Benutzererlebnis.
Beispielsweise wird in Single-Page-Anwendungen (SPAs) der gesamte Code üblicherweise in einer großen JavaScript-Datei gebündelt. Mit zunehmendem Umfang der Anwendung wird diese Datei größer, was zu längeren Ladezeiten führt. Durch Code-Splitting wird dieses Problem gelöst, indem der Code in kleinere Teile aufgeteilt wird. Dadurch lädt die Anwendung nur das, was für die aktuelle Seite oder Funktionalität erforderlich ist.
Warum Code-Splitting wichtig ist
Die Bedeutung der Codeaufteilung liegt in ihrer Fähigkeit, die Anwendungsleistung und das Benutzererlebnis zu optimieren. Große Codepakete können die Ladezeiten erheblich beeinträchtigen, insbesondere bei langsameren Netzwerken oder Mobilgeräten. Durch die Reduzierung der Codemenge, die heruntergeladen und ausgeführt werden muss, führt die Codeaufteilung zu schnelleren Interaktionen und einer reaktionsschnelleren Anwendung. In der heutigen digitalen Umgebung kann selbst eine kurze Verzögerung der Ladezeit dazu führen, dass Benutzer eine Anwendung abbrechen, was zu verlorenem Engagement und potenziellen Einnahmen führt.
Durch die Codeaufteilung wird außerdem der Speicherbedarf einer Anwendung minimiert, indem sichergestellt wird, dass zu einem bestimmten Zeitpunkt nur die erforderlichen Module in den Speicher geladen werden. Dies ist für Anwendungen mit umfangreichen, funktionsreichen Schnittstellen von Vorteil, bei denen nicht alle Funktionen gleichzeitig benötigt werden.
So funktioniert die Codeaufteilung
Statisches Code-Splitting (routenbasiertes Code-Splitting)
Bei der statischen Codeaufteilung, auch „routenbasierte Codeaufteilung“ genannt, wird der Code zur Build-Zeit basierend auf vorgegebenen Regeln in Blöcke aufgeteilt. Dieser Ansatz wird häufig in Webanwendungen verwendet, die unterschiedliche Routen oder Ansichten haben, wie z. B. SPAs.
Bei dieser Methode wird jede Route oder Hauptkomponente während des Build-Prozesses in einer eigenen Datei gebündelt. Wenn der Benutzer zu einer bestimmten Route navigiert, lädt die Anwendung nur das entsprechende Paket. Statisches Code-Splitting wird häufig mithilfe von Modul-Bündeln implementiert, die den Code automatisch in separate Pakete aufteilen, wie vom Entwickler angegeben.
In einer React-Anwendung kann beispielsweise die statische Codeaufteilung mithilfe der import()-Syntax erreicht werden. Der folgende Code zeigt, wie verschiedene Routen in separate Pakete aufgeteilt werden können:
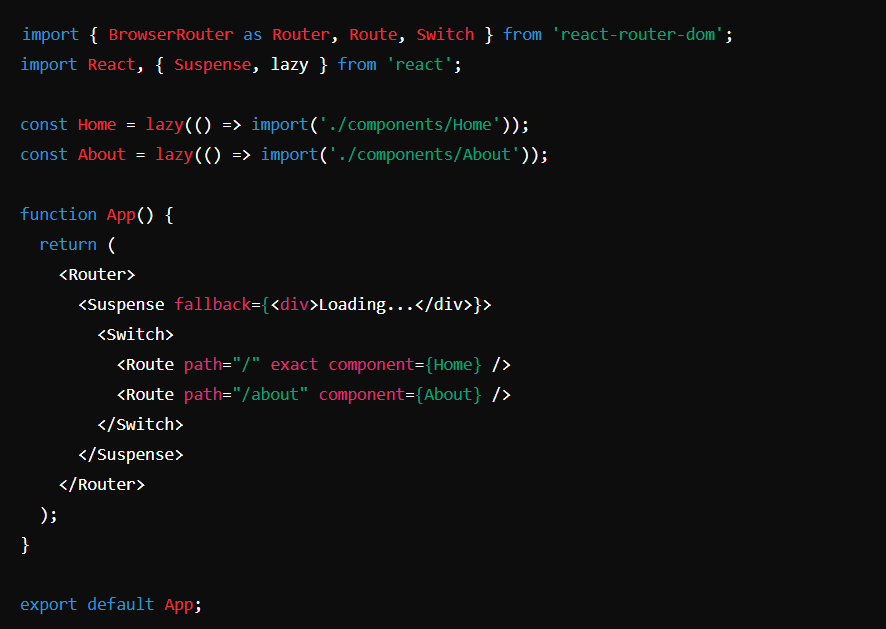
In diesem Beispiel werden die Komponenten „Home“ und „About“ in separate Pakete aufgeteilt. Diese Pakete werden dynamisch geladen, wenn der Benutzer zu den jeweiligen Routen navigiert. Dadurch wird die Menge an Code reduziert, die anfänglich geladen werden muss.
Dynamisches Code-Splitting (On-Demand-Code-Splitting)
Beim dynamischen Code-Splitting, auch bekannt als „On-Demand“ oder „Lazy Loading“, wird der Code zur Laufzeit basierend auf Benutzerinteraktionen aufgeteilt. Diese Strategie verwendet dynamische Importe (import()), um bestimmte Codeblöcke nur dann zu laden, wenn sie benötigt werden. Im Gegensatz zum statischen Code-Splitting ermöglicht das dynamische Splitting eine genauere Kontrolle, sodass Entwickler Code innerhalb von Komponenten oder sogar auf Funktionsebene aufteilen können.
Dynamisches Code-Splitting ist besonders nützlich, um selten verwendete Komponenten wie Modals, Widgets oder Drittanbieterbibliotheken zu laden und so die anfängliche Bundle-Größe zu reduzieren. Hier ist ein Beispiel für dynamisches Code-Splitting in einer React-Komponente:

In diesem Beispiel wird LazyComponent nur geladen, wenn der Benutzer auf die Schaltfläche klickt. Dies reduziert die anfängliche Ladezeit und stellt sicher, dass unnötiger Code erst ausgeführt wird, wenn er benötigt wird. Die Suspense-Komponente wird verwendet, um den Ladezustand zu handhaben und dem Benutzer Feedback zu geben, während die Komponente geladen wird.
Vorteile der Codeaufteilung
Verbesserte anfängliche Ladezeit
Einer der Hauptvorteile der Codeaufteilung ist die Verbesserung der anfänglichen Ladezeit einer Anwendung. Durch die Aufteilung der Codebasis in kleinere Blöcke lädt der Browser nur den wesentlichen Code herunter, der für den ersten Bildschirm oder die erste Benutzerinteraktion erforderlich ist. Dies führt zu einer schnelleren anfänglichen Ladezeit, da der Browser keine großen, monolithischen Dateien verarbeiten muss, bevor er die Anwendung rendert.
In Single-Page-Anwendungen (SPAs), in denen alle Komponenten traditionell gebündelt sind, ermöglicht die Codeaufteilung der Anwendung, nur die Komponenten zu laden, die für die aktuelle Ansicht erforderlich sind. Dadurch wird die Zeit bis zum ersten sinnvollen Paint erheblich verkürzt und die wahrgenommene Leistung und Reaktionsfähigkeit der Anwendung verbessert.
Verbesserte Anwendungsleistung
Durch die Codeaufteilung wird die Anwendungsleistung optimiert, indem der Speicherbedarf und die Menge an auszuführendem JavaScript reduziert werden. Durch das Laden des Codes in kleineren Segmenten minimiert die Anwendung die Belastung der Systemressourcen, was zu reibungsloseren Interaktionen führt, insbesondere auf Geräten mit begrenzter Verarbeitungsleistung.
Während Benutzer durch verschiedene Teile der Anwendung navigieren, stellt die Codeaufteilung sicher, dass nur die erforderlichen Teile bei Bedarf geladen werden. Dieser On-Demand-Lademechanismus verhindert die unnötige Ausführung von Code, was die Gesamtleistung verbessern und zu einem reaktionsschnelleren Benutzererlebnis führen kann.
Effizientes Ressourcenmanagement
Beim Code-Splitting werden zu einem bestimmten Zeitpunkt nur die erforderlichen Module oder Funktionen in den Speicher geladen. Dieses selektive Laden sorgt für eine effizientere Nutzung der Systemressourcen, insbesondere des Speichers. Wenn die Anwendung nicht den gesamten Code im Voraus lädt, kann das System Ressourcen für die Ausführung wichtiger Komponenten zuweisen und so potenzielle Verlangsamungen durch übermäßige Speichernutzung vermeiden.
Dieser Aspekt ist besonders wertvoll für Anwendungen mit vielen Funktionen und komplexen Benutzeroberflächen. Durch die effiziente Verwaltung der Ressourcen kann die Anwendung mehr Funktionen verarbeiten, ohne dass die Leistung entsprechend abnimmt.
Schnellere nachfolgende Ladevorgänge durch Caching
Ein weiterer wichtiger Vorteil der Codeaufteilung ist das verbesserte Caching. Wenn eine Anwendung in mehrere kleinere Pakete aufgeteilt wird, kann der Browser einzelne Blöcke zwischenspeichern. Bei nachfolgenden Besuchen müssen nur die neuen oder aktualisierten Blöcke heruntergeladen werden. Dies bedeutet, dass die Teile der Anwendung, die sich nicht geändert haben, bereits im Cache des Browsers liegen, was zu schnelleren Ladezeiten für wiederkehrende Benutzer führt.
Bei herkömmlichen monolithischen Anwendungen müssten Benutzer bei jeder kleinen Änderung das gesamte Paket erneut herunterladen. Durch die Codeaufteilung wird dieses Problem gemildert, da sichergestellt wird, dass nur die geänderten Teile erneut abgerufen werden. Dadurch wird der Datenverbrauch reduziert und nachfolgende Interaktionen beschleunigt.
Verbesserte Skalierbarkeit und Wartbarkeit
Das Aufteilen einer Anwendung in kleinere, überschaubare Module erleichtert automatisch deren Wartung und Skalierung. Die Codeaufteilung fördert ein modulares Design, bei dem sich Entwickler auf das Erstellen und Aktualisieren einzelner Codeblöcke konzentrieren. Diese Modularität vereinfacht den Debugging-Prozess, da Probleme auf bestimmte Teile der Anwendung beschränkt werden können.
Wenn die Anwendung wächst und neue Funktionen eingeführt werden, können Entwickler zusätzliche Module in neue Blöcke aufteilen, ohne die Leistung des vorhandenen Codes zu beeinträchtigen. Dieser Ansatz ermöglicht kontinuierliche Entwicklung und Bereitstellung, sodass die Anwendung effizienter skaliert werden kann.
Reibungsloseres Benutzererlebnis
Wenn Benutzer mit einer Anwendung interagieren, erwarten sie ein nahtloses Erlebnis mit minimalen Verzögerungen. Code-Splitting trägt zu einem reibungsloseren Benutzererlebnis bei, indem neue Module asynchron im Hintergrund geladen werden, während Benutzer durch verschiedene Teile der Anwendung navigieren. Durch das Vorladen oder Vorabrufen von Code für die nächsten möglichen Interaktionen kann die Anwendung nahezu sofortige Antworten liefern und so die wahrgenommene Latenz reduzieren.
In einer Webanwendung beispielsweise ermöglicht die Codeaufteilung das schnelle Laden der ersten Seite, während durch das Vorabrufen im Hintergrund zusätzliche Ressourcen geladen werden. Diese Strategie stellt sicher, dass nachfolgende Navigationen schnell und flüssig ablaufen, da der erforderliche Code bereits geladen wurde, bevor der Benutzer ihn anfordert.
Bessere Handhabung komplexer Anwendungen
Bei umfangreichen Anwendungen kann die Verwaltung komplexer Funktionen zu einem überwältigend großen Codepaket führen, das die Leistung beeinträchtigt. Die Codeaufteilung behebt dieses Problem, indem sie es Entwicklern ermöglicht, diese komplexen Funktionen in kleinere, unabhängige Module aufzuteilen, die bei Bedarf geladen werden können.
Diese Modularisierung stellt sicher, dass bei Benutzerinteraktionen nur relevante Teile der Codebasis verarbeitet werden, wodurch Leistungsengpässe vermieden werden. Durch die Verwaltung der Komplexität auf diese Weise ermöglicht die Codeaufteilung Entwicklern die Erstellung umfangreicher, funktionsreicher Anwendungen ohne Leistungseinbußen.
Verbesserte Flexibilität für Funktionsupdates
Die Codeaufteilung bietet Flexibilität beim Aktualisieren oder Hinzufügen von Funktionen zu einer Anwendung. Da verschiedene Funktionen in separate Blöcke isoliert sind, können Entwickler neue Funktionen ändern oder einführen, ohne die gesamte Codebasis zu beeinträchtigen. Dieser entkoppelte Ansatz minimiert das Risiko der Einführung von Fehlern und stellt sicher, dass Änderungen nur begrenzte Auswirkungen auf andere Teile der Anwendung haben.
Wenn eine neue Funktion hinzugefügt wird, kann sie in einem eigenen Block gebündelt werden, der bei Bedarf dynamisch geladen werden kann. Dies beschleunigt nicht nur den Bereitstellungsprozess, sondern verringert auch die Wahrscheinlichkeit von Regressionsproblemen bei vorhandenen Funktionen.
Optimierte Netzwerknutzung
Durch die Begrenzung der anfänglichen Bundle-Größe optimiert die Code-Aufteilung die Netzwerknutzung. Dies ist insbesondere für Benutzer mit langsameren Verbindungen oder mobilen Geräten von Vorteil, bei denen große Bundles zu längeren Ladezeiten führen können. Da nur der für die aktuelle Benutzerinteraktion erforderliche Code abgerufen wird, werden die Netzwerkressourcen effizienter genutzt.
Darüber hinaus sorgt die Code-Aufteilung durch Vorladen oder Vorabrufen von Ressourcen auf der Grundlage des erwarteten Benutzerverhaltens dafür, dass die Anwendung nur das abruft, was notwendig ist. Dadurch wird die Bandbreitenverschwendung vermieden, die durch das Herunterladen nicht verwendeter Module entsteht.
Erleichtert die Implementierung progressiver Webanwendungen (PWA)
Für Entwickler, die Progressive Web Applications (PWAs) erstellen, ist die Codeaufteilung unerlässlich. PWAs zielen darauf ab, ein App-ähnliches Erlebnis im Web mit schnellen Ladezeiten und Offline-Funktionen zu bieten. Die Codeaufteilung unterstützt dieses Ziel, indem sie die Größe des anfänglichen Downloads reduziert und das dynamische Laden von Inhalten basierend auf der Benutzerinteraktion ermöglicht. Sie arbeitet auch nahtlos mit Service Workern zusammen, die einzelne Blöcke zwischenspeichern können, um den Offline-Zugriff und schnelles Laden zu erleichtern und so das PWA-Erlebnis weiter zu verbessern.
Best Practices für die Codeaufteilung
Durch Code-Splitting lässt sich die Leistung einer Anwendung zwar erheblich steigern, der größtmögliche Nutzen lässt sich jedoch erzielen, wenn man Best Practices befolgt:
Vermeiden Sie übermäßiges Spalten
Das Aufteilen des Codes in zu viele kleine Teile kann zu einer übermäßigen Anzahl von Netzwerkanforderungen führen, was möglicherweise mehr Schaden als Nutzen anrichtet. Es ist wichtig, ein Gleichgewicht zwischen der Reduzierung der Paketgröße und der Minimierung der Anzahl von HTTP-Anforderungen zu finden.
Gruppieren ähnlicher Module
Gruppieren Sie beim Aufteilen von Code ähnliche Module, die häufig zusammen verwendet werden, in einem einzigen Block. Dadurch wird redundantes Laden reduziert und sichergestellt, dass die zugehörige Funktionalität bei Bedarf verfügbar ist.
Optimieren Sie die Ladepriorität
Verwenden Sie Techniken wie Preload und Prefetch, um die Ladepriorität von Codeblöcken zu optimieren. Dadurch werden kritische Blöcke schneller geladen, während weniger dringende Blöcke vorgeladen werden, was das Benutzererlebnis weiter verbessert.
Testen und Profilieren
Testen und profilieren Sie die Anwendung regelmäßig, um die Auswirkungen der Codeaufteilung auf die Leistung zu überwachen. Testtools können Engpässe identifizieren und bei der Optimierung der Aufteilungsstrategie helfen.
Herausforderungen und Überlegungen
Obwohl Code-Splitting eine leistungsstarke Technik zur Verbesserung der Leistung von Webanwendungen ist, bringt es auch seine eigenen Herausforderungen und Überlegungen mit sich. Die ordnungsgemäße Implementierung von Code-Splitting erfordert sorgfältige Planung und ein tiefes Verständnis der Architektur der Anwendung, des Benutzerverhaltens und potenzieller Fallstricke. Hier sind einige der wichtigsten Herausforderungen und Überlegungen, denen Entwickler bei der Implementierung von Code-Splitting gegenüberstehen:
Erhöhte Komplexität im Codebase-Management
Eine der größten Herausforderungen bei der Codeaufteilung ist die zusätzliche Komplexität, die sie der Codebasis verleiht. Wenn eine Anwendung in kleinere, unabhängig voneinander geladene Blöcke aufgeteilt wird, müssen Entwickler verwalten, wann und wie diese Blöcke geladen werden. Dazu gehört das asynchrone Laden von Modulen, das Sicherstellen, dass dynamisch importierte Komponenten nahtlos mit dem Rest der Anwendung zusammenarbeiten, und das Behandeln potenzieller Fehler während des Ladens.
Diese Komplexität kann den Lernaufwand für neue Entwickler, die dem Projekt beitreten, erhöhen und das Debuggen schwieriger machen. Fehler bei der Verwaltung von geteiltem Code können zu Laufzeitfehlern oder unerwartetem Verhalten führen und die Stabilität der Anwendung beeinträchtigen.
Abhängigkeitsverwaltung und Codeduplizierung
Beim Aufteilen von Code in kleinere Pakete ist es wichtig, die in jedem Block enthaltenen Abhängigkeiten zu überwachen. Wenn zwei oder mehr Blöcke gemeinsame Abhängigkeiten aufweisen, kann es passieren, dass diese Abhängigkeiten separat enthalten sind, was zu einer Code-Duplikation in mehreren Paketen führt. Diese Redundanz erhöht die Gesamtgröße der herunterzuladenden Dateien, was die Leistungsvorteile der Codeaufteilung zunichte machen kann.
Um dies zu mildern, müssen Entwickler sorgfältig vorgehen bei Analyse ihres Abhängigkeitsbaums und die Verwendung von Optimierungsstrategien wie das Extrahieren gemeinsamer Abhängigkeiten in separate Pakete. Dies fügt dem Build-Prozess jedoch eine zusätzliche Komplexitätsebene hinzu und erfordert eine regelmäßige Überwachung während der Weiterentwicklung der Anwendung.
Behandeln des Ladezustands
Bei Verwendung dynamischer Importe werden Komponenten oder Module asynchron geladen. Dies bedeutet, dass zwischen dem Zeitpunkt, an dem ein Benutzer eine Aktion auslöst (z. B. Navigieren zu einer neuen Route), und dem Zeitpunkt, an dem der entsprechende Codeblock heruntergeladen und ausgeführt wird, eine Verzögerung auftreten kann. Während dieser Verzögerung muss die Benutzeroberfläche den Ladezustand ordnungsgemäß verarbeiten, normalerweise durch die Anzeige eines Ladekreisels oder Platzhalterinhalts.
Die ordnungsgemäße Verwaltung dieses Ladezustands ist für die Aufrechterhaltung eines reibungslosen Benutzererlebnisses von entscheidender Bedeutung. Eine schlechte Handhabung kann zu einer trägen, nicht reagierenden Benutzeroberfläche führen, was Benutzer frustrieren und dazu führen kann, dass sie die Anwendung verlassen. Darüber hinaus müssen Entwickler potenzielle Ladefehler (z. B. Netzwerkausfälle) behandeln und den Benutzern in solchen Situationen aussagekräftiges Feedback geben.
Ausgleichen der Anzahl der Chunks
Das Aufteilen von Code in zu viele kleine Blöcke kann zu einer übermäßigen Anzahl von Netzwerkanforderungen führen. Wenn der Browser mehrere Anforderungen zum Abrufen jedes Blocks stellt, kann dies aufgrund der Netzwerklatenz zu Verzögerungen führen, insbesondere bei langsamen Verbindungen. Andererseits kann das Erstellen weniger, größerer Blöcke zwar die Netzwerkeffizienz verbessern, kann aber dennoch zu großen Dateien führen, deren Herunterladen und Analysieren länger dauert.
Es ist entscheidend, das richtige Gleichgewicht zwischen der Anzahl der Chunks und ihrer Größe zu finden. Dies erfordert häufig, dass Entwickler die Anwendung profilieren, mit verschiedenen Chunking-Strategien experimentieren und die Konfiguration an den jeweiligen Anwendungsfall anpassen. Dieser Prozess ist fortlaufend, da Änderungen an der Codebasis der Anwendung oder am Benutzerverhalten Anpassungen bei der Aufteilung des Codes erforderlich machen können.
Auswirkungen auf die anfängliche Ladeleistung
Obwohl die Codeaufteilung die Ladeleistung verbessern kann, indem sie das Laden bestimmter Teile der Codebasis verzögert, kann sie manchmal den gegenteiligen Effekt haben, wenn sie nicht sorgfältig implementiert wird. Wenn beispielsweise der anfängliche Block, der die Kernfunktionalität der Anwendung lädt, zu groß wird, kann dies die anfängliche Renderzeit verlangsamen. Wenn außerdem zu viele kritische Komponenten in separate Blöcke aufgeteilt werden, die sofort geladen werden müssen, kann dies zu mehreren gleichzeitigen Netzwerkanforderungen führen, was möglicherweise das anfängliche Rendering verzögert.
Um die Leistung beim ersten Laden zu optimieren, müssen Entwickler sorgfältig auswählen, welche Teile der Codebasis in das erste Paket aufgenommen und welche in separate Blöcke aufgeteilt werden sollen. Dazu gehört, zu verstehen, welche Komponenten und Module für die erste Interaktion mit dem Benutzer wichtig sind, und das Laden weniger kritischer Funktionen zu verschieben, bis sie benötigt werden.
Caching und Versionierung
Caching ist ein wichtiger Aspekt bei der Verbesserung der Anwendungsleistung. Durch Code-Splitting kann jeder Block unabhängig zwischengespeichert werden, wodurch die Datenmenge reduziert wird, die bei nachfolgenden Besuchen heruntergeladen werden muss. Dies führt jedoch auch zu einer höheren Komplexität der Cache-Verwaltung und Versionierung. Wie stellen Sie bei Codeänderungen sicher, dass die richtigen, aktualisierten Blöcke geladen werden, ohne dass der Benutzer auf Fehler aufgrund veralteter zwischengespeicherter Dateien stößt?
Um sicherzustellen, dass Benutzer immer die neueste Version jedes Blocks erhalten, sind geeignete Cache-Busting-Strategien, wie z. B. die Verwendung von Inhalts-Hashing in Dateinamen, unerlässlich. Die korrekte Implementierung dieser Strategien erfordert jedoch sorgfältige Planung und ein Verständnis dafür, wie Browser und Content Delivery Networks (CDNs) mit dem Caching umgehen.
Überwachung und Analytik
Die Codeaufteilung kann sich darauf auswirken, wie Benutzerinteraktionen verfolgt und analysiert werden. Wenn Chunks dynamisch geladen werden, kann es schwieriger werden, das Benutzerverhalten effektiv zu überwachen, z. B. zu verfolgen, wie lange es dauert, bis bestimmte Funktionen interaktiv werden, oder die Auswirkungen bestimmter Chunks auf die Leistung zu messen.
Um dieses Problem zu lösen, müssen Entwickler Überwachungs- und Analysetools integrieren, die dynamisches Laden unterstützen. Diese Tools können Einblicke in die Auswirkungen der Codeaufteilung auf die Benutzererfahrung geben und Entwicklern dabei helfen, ihre Aufteilungsstrategie zu optimieren.
Testen und Profilieren
Beim Testen einer Anwendung, die Code-Splitting verwendet, sind zusätzliche Überlegungen erforderlich. Entwickler müssen sicherstellen, dass die aufgeteilten Komponenten nahtlos zusammenarbeiten und asynchrone Ladezustände ordnungsgemäß verarbeiten. Automatisierte Tests sollten Szenarien wie verzögertes Laden von Komponenten, Fehlerbehandlung bei dynamischen Importen und Benutzerinteraktionen beim Abrufen von Chunks abdecken.
Profilierungstools sind für die Optimierung der Aufteilungsstrategie unverzichtbar. Entwickler müssen die Anwendung regelmäßig profilieren, um Engpässe zu identifizieren, Blockgrößen zu überwachen und Netzwerkanforderungen zu analysieren, um sicherzustellen, dass die Codeaufteilung die gewünschten Leistungsvorteile bringt.
Auswirkungen auf die Benutzererfahrung
Das Ziel der Codeaufteilung besteht letztlich darin, die Benutzererfahrung zu verbessern. Eine unsachgemäße Verwendung kann jedoch zu negativen Erfahrungen führen, wie z. B. verzögerten Interaktionen, zu häufig erscheinenden Ladesymbolen oder unerwartetem Verhalten während der Navigation. Entwickler müssen beim Entwurf ihrer Codeaufteilungsstrategie die Benutzerreise im Auge behalten und sicherstellen, dass die Anwendung schnell, reaktionsfähig und reibungslos bleibt.
Wie SMART TS XL Kann für Code-Splitting-Zwecke nützlich sein
SMART TS XL ist ein ausgereiftes Tool, das eine eingehende Analyse großer Codebasen ermöglicht, Muster aufdeckt und Bereiche hervorhebt, die von Optimierung, Modernisierung und Umstrukturierung profitieren können. Wenn es um Code-Splitting geht, SMART TS XL kann erkennen, welche Teile einer Anwendung sich für eine Aufteilung eignen und Entwicklern helfen, fundierte Entscheidungen zur Leistungsoptimierung zu treffen.
SMART TS XL identifiziert auch kleine, aber stark referenzierte Dateien. Entwickler können diese Informationen verwenden, um zu bestimmen, ob diese Dateien in kleinere, unabhängige Module umgestaltet werden können, die bei Bedarf dynamisch geladen werden können.
Analysieren von Dateiabhängigkeiten und programmübergreifenden Interaktionen
Die Codeaufteilung kann komplex werden, wenn es Abhängigkeiten zwischen verschiedenen Modulen gibt. SMART TS XLDie Fähigkeit von , Dateiverweise und Interaktionen abzubilden, ist hier von unschätzbarem Wert. Dadurch können Entwickler erkennen, welche Dateien eng miteinander verknüpft sind und welche innerhalb der Anwendung umfassendere Abhängigkeiten aufweisen. Diese Einsicht ist wichtig, wenn entschieden werden soll, wo Code aufgeteilt werden soll, um redundantes Laden und unnötige Komplexität zu vermeiden.
Durch die Offenlegung der Wechselwirkungen und Abhängigkeiten, SMART TS XL ermöglicht Entwicklern einen klaren Code zu erstellen Aufteilungsstrategie, die doppelten Code über mehrere Blöcke hinweg minimiert und sicherstellt, dass allgemeine Dienstprogramme und gemeinsam genutzte Module optimiert behandelt werden.
Aufdecken versteckter Komplexitäten in kleinen, häufig genutzten Dateien
SMART TS XL kann kleine Dateien identifizieren, die eine überraschend hohe Referenzanzahl aufweisen. Diese Dateien stellen häufig Dienstprogrammfunktionen dar, die im gesamten System verwendet werden. Wenn Entwickler ihre Rolle und Verteilung im Code verstehen, können sie entscheiden, wie diese Dienstprogramme in eine Codeaufteilungsstrategie integriert werden können.
SMART TS XLDie Fähigkeit von, diese Muster zu erkennen, stellt sicher, dass bei der Code-Aufteilung auch häufig übersehene Hilfsfunktionen berücksichtigt werden.
Unterstützung der Legacy-Modernisierung mit Code-Splitting-Erkenntnissen
Legacy-Anwendungen enthalten oft monolithische Strukturen mit eng gekoppelten Komponenten. SMART TS XL zeichnet sich durch das Durchsuchen von Legacy-Codebasen und das Identifizieren potenzieller Bereiche für die Modularisierung aus. Indem das Tool das Vorhandensein großer Dateien hervorhebt und ihre umfangreichen Referenzen zuordnet, hilft es Entwicklern dabei, Prioritäten zu setzen, welche Teile des Legacy-Systems in kleinere Module aufgeteilt werden sollten.
Während des Prozesses von Modernisierung des Erbes Codebasen, SMART TS XL kann dabei helfen, zu identifizieren, welche Codesegmente für den Datenfluss des Systems am kritischsten sind, wie etwa wichtige Natural-basierte Programme oder komplexe COBOL-Routinen. Dadurch können Entwickler die Codeaufteilung auf eine Weise implementieren, die nicht nur die Leistung verbessert, sondern auch die Integrität der Legacy-Logik bewahrt.
Überwachung potenzieller Redundanzen auf Bereinigungs- und Code-Aufteilungsmöglichkeiten
SMART TS XL kann Dateien mit niedrigen Referenzzahlen und minimalen Größen erkennen. Diese könnten weisen auf redundanten oder veralteten Code hin das kann das System überladen. Durch das Bereinigen solcher Dateien können Entwickler die Codebasis rationalisieren, was die Implementierung der Codeaufteilung erleichtert.
Außerdem, SMART TS XLMithilfe der detaillierten Analyse von können Entwickler Module identifizieren, deren Funktionalitäten sich überschneiden oder die konsolidiert werden könnten. Sobald redundante Dateien konsolidiert oder entfernt wurden, wird die verbleibende Codebasis modularer und eignet sich für die Codeaufteilung.
Strategische Planung für Code-Splitting
SMART TS XLDie Daten von , einschließlich Dateigrößenverteilung, Referenzzählungen und Interaktionsmustern, ermöglichen eine strategische Planung der Codeaufteilung. Entwickler können diese Informationen verwenden, um zu entscheiden, welche Teile der Anwendung im anfänglichen Paket enthalten sein sollen und welche Teile asynchron geladen werden können. Durch die Korrelation von Referenzzählungen mit Dateigrößen SMART TS XL hilft dabei, „Hotspots“ innerhalb der Anwendung zu identifizieren – Module, die sowohl groß als auch stark genutzt sind und sich hervorragend für eine Aufteilung zur Leistungssteigerung eignen.
Fazit
Code-Splitting ist keine Universallösung, sondern ein dynamisches Tool im Toolkit des Entwicklers. Bei korrekter Implementierung kann es eine träge, monolithische Anwendung in ein schnelles, reaktionsfähiges und skalierbares System verwandeln. Es verbessert die Benutzererfahrung, indem nur die erforderlichen Teile des Codes geladen werden, der Speicherverbrauch reduziert und die Ressourcenverwaltung optimiert wird. Die Implementierung erfordert jedoch eine sorgfältige Berücksichtigung potenzieller Herausforderungen, einschließlich erhöhter Komplexität, Handhabung von Ladezuständen, Verwaltung von Abhängigkeiten und Ausgleich von Blockgrößen. Durch das Verständnis dieser Herausforderungen und die Durchführung gründlicher Wirkungsanalyse , statische Code-Analyse, und fortlaufende Tests können Entwickler die Codeaufteilung meistern, um leistungsstarke, benutzerzentrierte Anwendungen zu erstellen. In einer Zeit, in der Leistung ein entscheidendes Unterscheidungsmerkmal bei digitalen Erlebnissen ist, bietet die Codeaufteilung eine ausgereifte Methode, um Anwendungen schlank, reaktionsschnell und an sich ändernde Anforderungen anpassbar zu halten.
SMART TS XL bietet einen detaillierten Einblick in die Struktur und Verwendung von Code innerhalb eines Softwaresystems und ist damit ein unverzichtbares Tool für Entscheidungen zur Codeaufteilung. Die Fähigkeit, Dateigrößen, Referenzzähler, Abhängigkeiten und Interaktionen zu analysieren, hilft Entwicklern, kritische Teile der Anwendung zu identifizieren, die am meisten von der Codeaufteilung profitieren würden. Indem es versteckte Komplexitäten aufdeckt, potenzielle Redundanzen überwacht und die Modernisierung von Altsystemen unterstützt, SMART TS XL gibt Entwicklern die nötigen Einblicke, um ihre Anwendungen zu optimieren, Paketgrößen zu reduzieren und Ladezeiten zu verbessern. Das Ergebnis ist letztendlich ein modulareres, skalierbareres und leistungsstärkeres System, das auf die individuellen Anforderungen jeder Anwendung zugeschnitten ist.