

JavaScript has evolved from a simple scripting language into one of the most critical pillars of modern software development. It powers dynamic web applications, backend services via Node.js, mobile apps through frameworks like React Native, and even cloud-native functions. As JavaScript projects grow in size and complexity, maintaining code quality, consistency, and security becomes increasingly difficult especially given the language’s dynamic and loosely typed nature.
Static code analysis tools offer a powerful solution to this challenge. By examining source code without executing it, these tools can detect a wide range of issues early in the development cycle. From catching unused variables and unreachable code to enforcing coding standards and identifying potential security flaws, static analysis helps developers write cleaner, more reliable JavaScript. More importantly, it integrates seamlessly into CI/CD pipelines, enabling teams to automate quality checks, reduce manual code review effort, and enforce governance at scale.
We explore the top static code analysis tools available for JavaScript in 2025. Whether you’re a solo developer aiming for best practices or part of a large engineering team managing enterprise-scale projects, the right tool can significantly improve your development workflow, codebase health, and software maintainability. Let’s break down the best options and how to choose the right one for your use case.
SMART TS XL: Enterprise-Grade Insight Beyond the Surface
While traditionally known for its COBOL and mainframe analysis capabilities, SMART TS XL has expanded to meet the needs of modern, multi-language enterprise environments including JavaScript. With more organizations embracing full-stack development and hybrid systems, SMART TS XL offers a powerful advantage by providing cross-platform static code analysis under a single, unified interface.
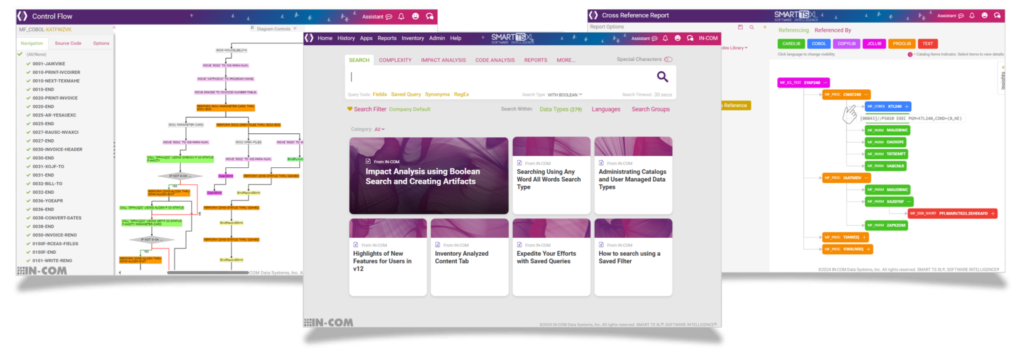
For JavaScript applications, SMART TS XL delivers rich metadata modeling, control and data flow visualization, and impact analysis, helping teams better understand how functions, modules, and data interact across a codebase. It goes beyond simple linting or syntax checks by providing deep insight into architectural dependencies, logic complexity, and runtime risks without requiring code execution.
Its advanced graph-based navigation tools allow developers and architects to trace API usage, module imports, and function calls across sprawling codebases. This is especially valuable in large JavaScript projects that use dynamic loading, third-party libraries, or asynchronous operations where understanding true execution paths can be difficult.
Advantages of SMART TS XL:
- Provides deep static analysis beyond syntax, including control flow and data flow modeling
- Visualizes module relationships, API usage, and function call hierarchies
- Supports hybrid environments with legacy and modern codebases in a unified interface
- Enables full-system impact analysis and logic tracing without executing code
- Offers customizable, metadata-rich search and semantic tagging features
- Integrates well into enterprise governance, audit, and documentation workflows
- Enhances onboarding, maintenance, and modernization efforts for large JavaScript applications
While it may not replace ESLint for day-to-day linting or Prettier for formatting, SMART TS XL complements these tools by offering system-level visibility making it an excellent choice for organizations that require enterprise-grade code intelligence, security awareness, and architectural clarity across both legacy and modern platforms, including JavaScript.
ESLint: The Industry Standard
ESLint is one of the most widely adopted static analysis tools for JavaScript and TypeScript, used by individual developers and large organizations alike. It functions primarily as a linter, enforcing code quality rules and stylistic consistency. ESLint is highly configurable, supports a large ecosystem of plugins, and integrates seamlessly into most modern IDEs and CI/CD pipelines.

Main features include:
- Rule-based linting for syntax errors, code smells, and best practices
- Extensibility through plugins (e.g., React, Vue, TypeScript, Node)
- Automatic code fixing for many issues
- Compatibility with formatters like Prettier
- IDE integration for real-time feedback
- Enforcement of coding standards through customizable
.eslintrcfiles - Smooth integration with GitHub Actions, Jenkins, GitLab CI, and other DevOps tools
While ESLint is an indispensable tool for front-end and full-stack teams, it has limitations when it comes to deep static analysis and enterprise-scale insights.
Shortcomings of ESLint:
- No architectural or data flow analysis
ESLint checks code on a per-file or per-function basis but does not model how data flows through the application. It cannot trace variables across files or identify potential runtime issues that span modules. - Limited visibility into code dependencies and impact
ESLint does not provide impact analysis, dependency maps, or visualizations of how components or functions interact. This makes it less helpful for onboarding, auditing, or system-wide change planning. - Not built for security auditing
While plugins exist (e.g., eslint-plugin-security), ESLint is not designed as a security scanner. It lacks the capability to detect complex vulnerabilities like insecure deserialization or authentication flaws without third-party tools. - Hard to scale in complex monorepos
In large codebases, especially monorepos or hybrid applications, managing ESLint configurations across multiple packages and frameworks can become unwieldy and lead to configuration drift. - Not suitable for legacy code modernization
ESLint does not provide metadata models, business logic extraction, or transformation guidance. It is a linting tool, not a modernization platform.
ESLint is a fast, powerful, and essential tool for enforcing JavaScript code standards and catching small issues early. However, it should be viewed as part of a broader code quality strategy, especially in enterprise settings where architectural visibility, impact analysis, and security assurance are equally important.
TypeScript: Static Safety Starts with the Compiler
TypeScript enhances JavaScript by introducing a powerful static type system, enabling developers to catch a wide range of errors at compile time. The TypeScript Compiler (TSC) itself serves as a robust static analysis engine, flagging everything from type mismatches and unreachable code to missing imports and incorrect function signatures—all before the code runs.
When properly configured using the tsconfig.json file, TypeScript becomes even more rigorous. Developers can enable strict type checking, enforce no-implicit-any rules, limit codebase reachability, and more. TSC performs semantic analysis across modules, making it possible to detect API misuse, incorrect property access, and type violations across files and packages.
Main features include:
- Compile-time type checking and structural typing enforcement
- Cross-file analysis of imports, exports, and function signatures
- Enforcement of strict code policies via
tsconfig.json(e.g.,strict,noUnusedLocals) - IDE and editor integration for live feedback and autocompletion
- Early detection of logic errors in complex asynchronous or functional flows
- Automatic generation of type declarations for safer module usage
Shortcomings of TSC and tsconfig-based analysis:
- Focuses only on type safety, not on code quality or style
TypeScript checks types and syntactic correctness, but it doesn’t warn about code smells, formatting issues, or anti-patterns. You’ll still need tools like ESLint or Prettier to manage those. - No security analysis
TSC does not detect security vulnerabilities such as injection risks, insecure API usage, or potential data leaks. It cannot validate safe coding practices or sanitize logic paths. - Lacks architectural or control flow insight
TypeScript provides no control/data flow visualization or architectural mapping. It cannot tell you how deeply a function is nested, what its impact radius is, or whether business logic is duplicated. - Limited support for rule customization and extensibility
Unlike linters or enterprise-grade analyzers, TSC has a fixed set of checks. While it is configurable, it is not extensible through plugins to support new types of analysis beyond what TypeScript inherently supports. - Blind to dead code and unused logic in certain edge cases
TSC can miss dead code in dynamically loaded modules or situations involving conditional imports and runtime feature toggling. - No integration with quality dashboards or DevOps policies
TypeScript does not offer reporting, historical tracking, or policy enforcement across pipelines. It provides instant compiler feedback, but lacks visibility at the team or system level.
TypeScript is a strong foundation for building safe, type-validated JavaScript applications, and the TypeScript compiler performs essential static analysis. However, it is not a complete quality or security solution. To fully govern a TypeScript codebase especially in enterprise environments teams should pair TSC with linters, SAST tools, and architectural analyzers to achieve broad code visibility and compliance.
SonarQube (with SonarJS): Code Quality Governance
SonarQube is a widely used static code analysis platform designed to assess code quality, maintainability, and security across a wide variety of programming languages. With the SonarJS plugin, it offers strong support for JavaScript and TypeScript, providing automated insights into code smells, bugs, vulnerabilities, and duplications.
SonarQube integrates seamlessly with CI/CD pipelines and DevOps workflows, making it easy for teams to enforce quality gates and track technical debt over time. It’s particularly popular in enterprise environments for its centralized dashboards, historical reporting, and policy enforcement mechanisms that align with code review and compliance standards.
Main features include:
- Detection of bugs, code smells, and security vulnerabilities in JavaScript and TypeScript
- Enforcement of customizable quality gates and coding rules
- Rich dashboards with historical metrics and trend graphs
- Seamless integration with Jenkins, GitHub Actions, GitLab, Azure DevOps, and others
- In-depth support for code duplication and cyclomatic complexity analysis
- Compliance tracking aligned with OWASP Top 10, CWE, and SANS guidelines
Shortcomings of SonarQube (with SonarJS):
- Lacks deep control and data flow modeling
While SonarQube flags many issues, it does not build a deep semantic model of how data flows through functions or services. It cannot trace values across asynchronous operations or determine runtime side effects in complex callback chains. - Limited context awareness
SonarJS operates primarily on pattern-based rules. It may miss nuanced issues like improper use of APIs, misuse of Promises, or logic errors that depend on broader application context. - False positives and noise in large codebases
In enterprise-scale JavaScript monorepos, SonarQube can generate excessive alerts, many of which are not critical. This often leads to alert fatigue or teams ignoring warnings altogether. - Static rule set limitations
Although rules can be customized or toggled, SonarJS is not as flexible as tools like Semgrep or CodeQL in defining highly specific patterns or project-specific security conditions. - Limited support for modern JavaScript ecosystems
Support for newer features like ECMAScript modules, decorators, or advanced TypeScript constructs may lag, especially in self-hosted instances that are not regularly updated. - No real-time developer feedback unless paired with SonarLint
SonarQube itself does not provide in-editor diagnostics unless integrated with SonarLint. Without this, feedback loops are delayed to pipeline stages, reducing immediacy for developers.
SonarQube with SonarJS is a powerful solution for teams looking to enforce consistent quality and security standards in JavaScript projects, particularly at scale. Its dashboards, rule enforcement, and integration with CI pipelines make it ideal for governance and compliance. However, to achieve deeper semantic analysis, runtime behavior insight, or precise rule control, SonarQube should be paired with more context-aware or developer-first tools such as CodeQL or Semgrep.
JSHint: Lightweight Linting for JS Fundamentals
JSHint is a fast, lightweight static code analysis tool designed to catch common errors and potential problems in JavaScript code. Originally created as a more flexible alternative to JSLint, it has been a popular choice for developers working on small to medium JavaScript projects, especially in environments where simplicity, speed, and custom rule configuration are prioritized.
Unlike ESLint, which focuses on modular extensibility and ecosystem plugins, JSHint offers a minimalist, opinionated approach to linting, suitable for teams that want quick feedback on obvious coding issues without configuring a complex rule engine. It is easy to integrate into build processes and works well for legacy JavaScript codebases, including older ECMAScript versions.
Main features include:
- Detects common syntax errors, undeclared variables, and type coercion pitfalls
- Supports configuration via
.jshintrcor inline comments - Fast execution with minimal dependencies
- Simple integration with build tools like Grunt, Gulp, and npm scripts
- Works well in older JavaScript environments (ES5 and earlier)
- Runs in browsers, terminals, or as part of CI/CD pipelines
Shortcomings of JSHint:
- Limited support for modern JavaScript (ES6+)
While JSHint has some support for newer syntax, it lags behind in handling features like modules, destructuring, arrow functions, async/await, optional chaining, and TypeScript. It’s not designed with modern JS ecosystems in mind. - No plugin architecture
Unlike ESLint, JSHint does not support third-party plugins. This makes it inflexible for projects that need custom rule definitions, framework-specific validation (e.g., React, Vue), or dynamic linting rules. - Lack of security or semantic analysis
JSHint cannot detect vulnerabilities, insecure patterns, or misuse of APIs. It focuses purely on syntax and basic logic issues, not on application safety or maintainability. - No type-awareness or flow control analysis
JSHint operates at a superficial syntactic level. It does not understand variable lifetimes, cross-function dependencies, or asynchronous logic chains, which are common in modern JavaScript. - Limited configurability and poor IDE integration
Configuration options are basic, and modern editor support is largely overshadowed by ESLint and TypeScript tooling, both of which offer in-editor diagnostics, autocompletion, and refactoring support. - Declining community activity
As ESLint has become the de facto standard, JSHint’s updates and community contributions have slowed. This can result in gaps in support and fewer improvements over time.
JSHint remains a fast, reliable tool for basic JavaScript error detection, especially in legacy or resource-constrained projects. However, it is not built for modern frameworks, large codebases, or developer productivity workflows. Most teams today will find more long-term value in using ESLint or pairing TypeScript with complementary tooling to achieve comprehensive, future-ready static analysis.
Prettier (with ESLint Integration): Automated Code Formatting for Consistency at Scale
Prettier is a widely adopted opinionated code formatter that ensures consistent code style across JavaScript (and many other languages) by automatically reformatting source files based on a defined set of rules. Unlike linters, which detect stylistic or logical issues, Prettier reformats your code automatically, eliminating debates over formatting and enforcing clean, readable code across teams.
When paired with ESLint, Prettier helps create a streamlined developer experience: ESLint enforces code quality and logic rules, while Prettier ensures consistent style and layout. Many projects use both tools in tandem, often through the eslint-config-prettier and eslint-plugin-prettier packages to ensure the tools do not conflict.
Main features include:
- Automatic formatting for JavaScript, TypeScript, JSX, JSON, HTML, CSS, and more
- Enforces consistent indentation, spacing, line width, and quote styles
- Removes stylistic inconsistencies across files and contributors
- Integrates with most editors (VSCode, WebStorm, Sublime, etc.)
- Easy to run via CLI, pre-commit hooks (e.g., with Husky), or CI scripts
- Plays well with ESLint when properly configured
Shortcomings of Prettier (even with ESLint integration):
- Not a static code analyzer
Prettier does not analyze code logic, detect bugs, or enforce quality standards. It does not care whether your code is correct—only that it looks consistent. It will happily format buggy or insecure code without raising any warning. - Limited configurability by design
Prettier is intentionally opinionated. While this reduces team debates, it also limits customization. Projects with highly specific style guidelines may find Prettier too rigid. - Cannot enforce architectural or semantic consistency
Prettier does not understand your code’s business logic, data flow, or module structure. It can’t help you detect duplicated logic, deeply nested functions, or misplaced concerns—issues that impact maintainability but aren’t about formatting. - No insight into performance, security, or best practices
Prettier won’t warn you about slow loops, unsafe async calls, unused variables, or deprecated APIs. Those responsibilities fall entirely to linters and static analysis tools. - Redundant if used without a linter
On its own, Prettier improves appearance but offers no guardrails for correctness. Without ESLint or another linter, developers can still introduce problematic patterns or errors despite perfectly formatted code.
Prettier is an essential tool for maintaining consistent code formatting across JavaScript projects, reducing style friction and making code more readable. However, it is not a substitute for static code analysis. Its power is maximized when integrated with ESLint, where it handles the visual side of code while ESLint enforces structural and logical integrity.
Flow: Static Type Checking for Safer JS
Flow, developed by Meta (Facebook), is a static type checker for JavaScript that analyzes code without executing it, helping developers catch type-related bugs early in the development cycle. Similar to TypeScript in intent but different in design, Flow allows developers to gradually add type annotations to JavaScript files, enabling early error detection while maintaining compatibility with vanilla JS.
Flow parses code to check for inconsistencies in function arguments, variable assignments, return types, and object property usage. It integrates with Babel, many popular editors, and build tools, offering fast feedback on type safety issues. Flow is especially effective in large, dynamic JavaScript projects that evolve quickly and demand robust correctness guarantees.
Main features include:
- Static type inference with optional or explicit annotations
- Detects type mismatches, undefined variables, and logic errors
- Supports gradual typing—no need to fully convert a codebase
- Fast incremental checking for performance at scale
- Integrates with IDEs like VSCode and Atom for live diagnostics
- Works well with React and common frontend tooling
Shortcomings of Flow:
- Narrow focus on type safety only
Flow only analyzes type correctness. It does not enforce stylistic rules, detect code smells, or identify security vulnerabilities. For logic validation, linting, and code quality enforcement, other tools are still necessary. - Shrinking community and industry support
While once a popular alternative to TypeScript, Flow has seen declining adoption. Many open-source projects, including those from Meta itself, have migrated to TypeScript. This affects ecosystem health, plugin maintenance, and community resources. - Compatibility friction with modern JS tooling
Flow requires setup with Babel and custom presets to strip types, which can complicate build pipelines. Compared to TypeScript’s integrated compiler and ecosystem, Flow often feels harder to configure and maintain. - Limited IDE and plugin support compared to TypeScript
Although Flow offers editor integration, it is less polished and widely supported than TypeScript’s developer tooling. This leads to slower or less accurate diagnostics in many environments. - Less flexibility for cross-platform projects
Flow’s ecosystem is primarily centered around JavaScript and React. It lacks TypeScript’s broader platform support (e.g., for Node, Angular, backend services, etc.), making it harder to standardize across a full-stack codebase. - No enterprise-level governance features
Flow does not offer dashboards, policy enforcement, or CI-oriented analysis the way tools like SonarQube or CodeQL do. It is primarily a development-time tool, not a governance solution.
Flow provides solid static type checking for JavaScript developers who want early error detection without leaving the language entirely. However, with decreasing momentum, weaker tooling support, and no insight into quality, architecture, or security, Flow is best used in smaller teams or legacy projects that have already adopted it. For most new projects, TypeScript is the more future-proof choice, especially when paired with complementary static analysis tools.
Tern: Lightweight JS Code Intelligence
Tern is a JavaScript code analyzer and inference engine that provides intelligent code analysis primarily for editor autocompletion and navigation. It was originally developed to improve the developer experience by enabling smarter code hinting, type inference, and documentation lookup within editors like Vim, Emacs, Sublime Text, and early Visual Studio Code setups.
Tern parses JavaScript code to understand variable types, object structures, function signatures, and scopes. It operates without the need for explicit type annotations, instead relying on dynamic analysis and type inference to generate accurate suggestions and insights. While not a full-featured static analysis tool in the sense of linting or vulnerability detection, it serves as a code intelligence engine that enhances code navigation and editing.
Main features include:
- Real-time autocompletion and intelligent code suggestions in editors
- Dynamic type inference for functions, objects, and variables
- Context-aware navigation and jump-to-definition support
- Lightweight and fast with minimal configuration
- Plugin support for popular libraries (e.g., jQuery, AngularJS, Node.js)
- Works offline and integrates with various editors
Shortcomings of Tern:
- Not a static analyzer in the traditional sense
Tern does not detect bugs, code smells, logic errors, or security vulnerabilities. It provides code navigation and inference only, not enforcement of code correctness or quality. - No support for modern JavaScript features
Tern was built during the ES5/early ES6 era and lacks robust support for newer JavaScript syntax like async/await, destructuring, optional chaining, ES modules, and TypeScript. Its parser often breaks or becomes unreliable with modern code. - Limited and outdated ecosystem
Development on Tern has slowed significantly, and many of its plugins are no longer maintained. As IDEs like VSCode and WebStorm have matured, native features have replaced the need for Tern in most workflows. - Not scalable for large codebases
Tern’s performance and accuracy decline in large monorepos or heavily modularized applications. It lacks indexing, caching, and architectural modeling needed for enterprise-scale projects. - No integration with CI/CD or DevOps workflows
Tern is a local developer tool with no support for continuous integration, reporting, or policy enforcement. It cannot be used for pipeline-based quality gates or team-wide code governance. - Superseded by Language Server Protocol (LSP)-based tools
Tools like TypeScript’s language server, built-in IntelliSense in VSCode, and tools powered by LSP have rendered Tern largely obsolete for modern JavaScript development.
Tern was an innovative tool for its time, bringing intelligent code completion and navigation to early JavaScript editors. However, due to outdated syntax support, limited functionality, and lack of modern integration, it has been overtaken by newer, more capable tools like TypeScript, ESLint, and editor-native language servers. Today, Tern is best considered a legacy tool with limited value in current development workflows.
Snyk Code: Developer-First Static Analysis with a Security Focus
Snyk Code is part of the Snyk platform, which focuses on developer-friendly security solutions, including static application security testing (SAST), open-source vulnerability scanning, container security, and more. With Snyk Code, teams can perform real-time static code analysis for JavaScript, TypeScript, Node.js, and other modern languages detecting vulnerabilities and insecure coding patterns directly in the development workflow.
Snyk Code operates through semantic and pattern-based analysis, using a curated and expanding set of rules to identify issues like insecure data handling, injection risks, cross-site scripting (XSS), broken authentication flows, and more. It is designed for fast, IDE-native feedback while also integrating into CI/CD pipelines for automated enforcement.
Main features include:
- Real-time detection of JavaScript and Node.js vulnerabilities during coding
- Semantic code analysis with actionable security recommendations
- IDE integration (VSCode, IntelliJ, WebStorm) for in-editor issue tracking
- CI/CD integration with GitHub, GitLab, Bitbucket, Azure, Jenkins, and others
- Scans proprietary and third-party code for known security risks
- Aligns with OWASP Top 10 and common compliance frameworks
Shortcomings of Snyk Code:
- Security-focused only
Snyk Code is not a general-purpose static analyzer. It does not flag code smells, style violations, maintainability issues, or architectural problems. It complements but does not replace tools like ESLint or SonarQube. - Limited visibility into data and control flow
While Snyk Code performs semantic scanning, its depth is limited when it comes to tracing complex asynchronous logic, deeply nested callbacks, or multi-file data propagation in large JS projects. - No code formatting or code quality rule support
Unlike ESLint or Prettier, Snyk Code offers no support for enforcing stylistic conventions or formatting rules. Teams still need separate tools to maintain consistent code quality and style. - Closed rule engine and limited customization
Unlike tools like Semgrep or CodeQL, Snyk Code does not currently allow developers to define custom rules or logic patterns. You are limited to Snyk’s built-in rule set and its update cadence. - Commercial licensing
While there is a free tier, advanced features such as full project scanning, historical reporting, and policy enforcement are available only under commercial plans. This can be a barrier for smaller teams or open-source projects. - Requires internet access for full functionality
Since Snyk Code is cloud-based by default, organizations with strict air-gapped environments or on-prem security requirements may find integration challenging.
Snyk Code is an excellent tool for catching security vulnerabilities in JavaScript and Node.js code early in development, thanks to its fast feedback, clear recommendations, and smooth developer experience. However, it is not a full static analysis platform it must be used alongside tools that address code quality, architectural analysis, and modernization. For security-focused teams in modern JavaScript ecosystems, Snyk Code fits well as part of a layered DevSecOps toolchain.
Semgrep: Lightweight, Developer-Friendly Static Analysis
Semgrep is an open-source, pattern-based static analysis engine that combines the speed and simplicity of traditional linters with the semantic power of abstract syntax tree (AST) analysis. Designed to be both developer-friendly and security-aware, Semgrep supports JavaScript, TypeScript, Node.js, and many other modern languages.
What makes Semgrep unique is its flexibility and customizability. Teams can write their own rules to search for specific patterns or security issues in code, enabling a high degree of precision and control. It is widely used by both individual developers and security teams to enforce code standards, identify vulnerabilities, and prevent risky coding practices in CI/CD workflows or during code review.
Main features include:
- Supports custom rules written in simple YAML or Semgrep’s domain-specific syntax
- Detects code patterns, insecure logic, hardcoded secrets, and more
- Offers pre-built rule sets for JavaScript (including OWASP Top 10 and best practices)
- Runs fast locally and integrates easily with CI/CD tools
- IDE integration for in-editor feedback (e.g., VSCode)
- Available as both open-source and commercial SaaS (with dashboards, policies, and insights)
- Ideal for both security and code quality use cases
Shortcomings of Semgrep:
- Pattern-based limitations
Semgrep is very powerful for detecting how code looks, but not how it behaves. It does not perform deep control flow, data flow, or taint analysis across modules or through complex asynchronous operations. This can lead to missed issues or false positives when context is required. - Requires rule-writing expertise for customization
While rule writing is simple for experienced users, non-security engineers or junior developers may find custom rule creation difficult without training. Maintaining a large rule set can become burdensome in complex environments. - No built-in formatting or style checking
Unlike ESLint or Prettier, Semgrep does not offer style enforcement, indentation correction, or naming convention validation. It is focused on logic and semantic structure, not code appearance. - No full type system awareness
Although Semgrep can parse TypeScript and other typed languages, it does not perform full type resolution like TypeScript’s compiler or Flow. This limits its ability to catch some type-specific issues. - No architectural visualization or technical debt modeling
Semgrep lacks high-level features like dependency maps, duplication tracking, or technical debt dashboards, which are common in enterprise tools like SonarQube or SMART TS XL. - Limited historical tracking in open-source version
While the open-source CLI is powerful, features like alert management, policy enforcement, historical data tracking, and organizational dashboards require the commercial Semgrep Cloud version.
Semgrep is a highly flexible and fast static analysis tool that’s especially effective in modern JavaScript environments where security, code hygiene, and rule enforcement are priorities. Its ability to define precise patterns gives it a major advantage over more rigid tools, but its reliance on rule-based matching means it must be paired with other tools for full control flow analysis, type checking, or code styling. It’s a strong addition to any DevSecOps toolchain and is particularly well-suited for scaling secure coding practices across teams.
CodeQL: Semantic Code Scanning Powered by Query Logic
CodeQL, developed by GitHub (now part of Microsoft), is a semantic code analysis engine that allows developers and security teams to perform deep static analysis using a query language. Instead of simply pattern-matching, CodeQL transforms source code into a database, allowing complex queries that uncover sophisticated vulnerabilities, logic flaws, and anti-patterns.
It supports multiple languages, including JavaScript, TypeScript, Python, Java, C/C++, C#, and Go, and is the core analysis engine behind GitHub’s code scanning feature. With CodeQL, users can write or reuse queries to explore how data flows across functions, trace taint sources to sinks, or detect vulnerable coding constructs.
Main features include:
- Semantic, query-based analysis using a SQL-like language
- Deep insight into data flow, control flow, and function behavior
- Built-in queries for OWASP Top 10, CWE, and known security anti-patterns
- Seamless integration with GitHub Actions, GitHub Enterprise, and CLI workflows
- Highly customizable with support for user-defined queries and query packs
- Ideal for advanced security research, code auditing, and DevSecOps pipelines
Shortcomings of CodeQL:
- High learning curve
CodeQL’s query language is powerful but complex. Writing custom queries requires knowledge of logic programming, database theory, and CodeQL’s schema. It is not approachable for most developers without training or documentation deep-dives. - Limited utility for code quality or stylistic analysis
CodeQL is designed for security and correctness, not for enforcing formatting, naming conventions, or stylistic rules. For issues like code smells, duplication, or formatting, tools like ESLint or Prettier are still required. - No live or in-editor feedback
CodeQL is not a developer productivity tool. It does not offer real-time diagnostics, autocompletion, or inline fixes in IDEs. Feedback is delayed to scan runs via GitHub Actions or the CLI. - Slow scan times on large codebases
Because CodeQL performs deep semantic analysis, it can be computationally expensive. Full project scans, especially in monorepos, may take several minutes or more, making it less suitable for frequent local use. - No visualization or dashboarding in the open-source version
While GitHub Advanced Security includes CodeQL integration with dashboards and PR alerts, the standalone open-source tools lack comprehensive visualization, historical tracking, or centralized management unless paired with enterprise offerings. - Security-focused, not modernization-focused
CodeQL shines at identifying vulnerabilities, taint propagation, and complex misuse patterns, but it does not assist with architectural refactoring, technical debt assessment, or modernization planning.
CodeQL is one of the most powerful static analysis tools available for JavaScript security, offering precise insights into how code actually behaves. Its semantic model and customizable queries make it ideal for security researchers, auditors, and DevSecOps engineers who need to go beyond surface-level checks. However, it is not intended for everyday development use, and should be paired with more accessible tools like ESLint, Semgrep, or SonarQube for a holistic quality and security strategy.
PMD: Rule-Based Static Code Analysis with Legacy Appeal
PMD is a long-established open-source static code analyzer that supports a variety of languages, including Java, Apex, JavaScript, XML, and others. It uses a rule-based engine to identify common programming flaws, such as unused variables, empty catch blocks, duplicate code, overly complex methods, and other maintainability concerns.
Although PMD is best known in the Java ecosystem, it also includes limited support for JavaScript through a small set of predefined rules. PMD is configurable via XML, supports custom rule definitions, and can be integrated into build tools like Maven, Gradle, Ant, and CI servers such as Jenkins or GitHub Actions.
Main features include:
- Detects issues related to code structure, complexity, and maintainability
- Supports basic JavaScript rules like unused variables, overly long functions, or empty blocks
- Allows creation of custom rules using XPath or Java-based extensions
- Command-line interface and plugin support for various IDEs and build tools
- Useful for catching anti-patterns, enforcing style guides, and reducing technical debt
- Fully open-source with an active (though language-skewed) community
Shortcomings of PMD:
- Limited JavaScript support
PMD’s JavaScript ruleset is minimal and dated. It lacks coverage for modern JavaScript syntax (e.g., ES6+ features like classes, async/await, modules, arrow functions) and does not support TypeScript. - No semantic analysis or deep flow tracking
PMD operates on syntactic patterns. It does not build a semantic understanding of how data flows between functions or across files, which limits its ability to detect context-sensitive bugs or vulnerabilities. - No security-focused capabilities
PMD does not offer vulnerability detection or compliance checks (e.g., OWASP, CWE). It cannot identify injection points, insecure API usage, or data leaks, making it unsuitable as a SAST tool for security assurance. - No integration with modern JavaScript tooling
PMD lacks smooth integration with the modern JavaScript ecosystem—no built-in support for tools like ESLint, Prettier, Babel, Webpack, or modern frameworks like React, Vue, or Angular. - Requires manual rule management and customization
Rules must be configured using verbose XML, and while custom rule writing is possible, it’s non-trivial and requires understanding of abstract syntax trees and XPath or Java rule development. - No real-time IDE feedback for JavaScript
While PMD integrates into IDEs for Java (e.g., Eclipse, IntelliJ), its JavaScript support lacks rich tooling. Developers using VSCode or WebStorm will find little to no native PMD feedback during development.
PMD remains a reliable static analysis tool for Java and legacy JavaScript projects, particularly in organizations already using it for other languages. However, its JavaScript support is limited, outdated, and not well-suited for modern development practices. For contemporary JavaScript and TypeScript codebases, ESLint, Semgrep, or SonarQube offer much broader capabilities, active ecosystem support, and better integration with today’s front-end and full-stack tooling.
DeepScan: Static Analysis Focused on Runtime Issues
DeepScan is a static analysis tool designed specifically for JavaScript and TypeScript, with a strong focus on detecting runtime issues, quality defects, and logic bugs that traditional linters like ESLint may overlook. It goes beyond stylistic enforcement to uncover deep semantic issues, making it particularly useful for spotting problematic code in modern front-end frameworks such as React, Vue, and Angular.
DeepScan performs control flow and data flow analysis, which allows it to flag unreachable code, null reference errors, forgotten await statements, incorrect condition checks, and other runtime-critical problems. It integrates with GitHub and popular CI/CD platforms, and offers both a cloud-based service and a Web IDE extension, making it accessible for individuals and teams alike.
Main features include:
- Deep semantic analysis of JavaScript and TypeScript code
- Detection of runtime issues like null dereferences, incorrect conditions, and forgotten async handling
- Out-of-the-box support for popular frameworks (React, Vue, Angular)
- Web-based dashboard for code quality tracking and metrics
- GitHub integration for inline pull request analysis
- Lightweight setup with CLI support and VSCode plugin
Shortcomings of DeepScan:
- No custom rule support
Unlike tools such as ESLint or Semgrep, DeepScan does not allow users to define custom rules. This makes it harder to enforce project-specific coding guidelines or perform targeted logic enforcement. - Limited scalability for large enterprise projects
While suitable for small and mid-sized projects, DeepScan’s dashboard and policy management are not as robust as platforms like SonarQube or CodeQL when it comes to enterprise-grade reporting, multi-repo governance, or organizational compliance tracking. - Focus on runtime correctness, not security
DeepScan is great at catching logic flaws, but it does not provide security analysis. It will not detect vulnerabilities like XSS, SQL injection, insecure authentication logic, or known vulnerability patterns unless they manifest as code logic issues. - No architectural visualization or technical debt modeling
DeepScan offers metrics and issue categorization, but lacks higher-level visualization features like dependency graphs, duplication detection, or modernization readiness insights. - Web-based, with limitations in on-premises or air-gapped environments
Most of DeepScan’s capabilities rely on cloud integration. While a CLI exists, users working in restricted or offline environments may find adoption more difficult. - Not a full replacement for linters or formatters
DeepScan complements tools like ESLint and Prettier but does not enforce code style or formatting. Teams must still maintain separate tooling for stylistic consistency.
DeepScan is a smart choice for teams looking to go beyond linting and catch runtime defects and hidden logic bugs in JavaScript and TypeScript applications. Its semantic analysis engine is particularly helpful for spotting errors in complex front-end codebases. However, it is not a comprehensive solution for security, compliance, or enterprise-scale analysis, and is best used in conjunction with other tools such as ESLint, Snyk, or SonarQube for full coverage.
Retire.js: Targeted Vulnerability Scanning for Dependencies
Retire.js is a security-focused static analysis tool that helps developers identify known vulnerabilities in JavaScript libraries and dependencies. Rather than analyzing code logic or syntax, Retire.js scans for the use of outdated or insecure versions of third-party components particularly front-end libraries like jQuery, AngularJS, Bootstrap, and others.
It works by comparing dependencies (both in code and package managers) against a curated vulnerability database, flagging libraries with known CVEs or public security advisories. Retire.js can be run via the command line, integrated into CI/CD pipelines, or used as a browser extension to detect vulnerable libraries in running web applications.
Main features include:
- Scans JavaScript source files and Node.js modules for known vulnerabilities
- Maintains a public vulnerability repository (community-curated)
- CLI tool for automation in builds and pipelines
- Browser extension to detect client-side library vulnerabilities in real-time
- Fast execution and lightweight setup
- Compatible with npm, Yarn, and other Node.js ecosystems
Shortcomings of Retire.js:
- Only detects known vulnerabilities
Retire.js cannot detect unknown or novel vulnerabilities, insecure coding patterns, or runtime logic errors. It only flags packages and scripts that match its CVE database. - No code logic or behavior analysis
Retire.js does not analyze your actual application code only the libraries it uses. It won’t detect unsafe API usage, tainted data flows, or misconfigured security controls in your own codebase. - Dependency resolution is basic
Retire.js does not provide full dependency graphs, transitive dependency resolution, or contextual insight into how libraries are used. This can lead to false positives (if a library is present but unused) or false negatives (if vulnerabilities exist deeper in the tree). - Lacks detailed remediation guidance
While it tells you a library is vulnerable, Retire.js offers limited actionable advice on how to fix or upgrade especially compared to tools like Snyk or npm audit that suggest specific fix versions. - No integration with IDEs or inline developer feedback
Unlike tools such as ESLint or Snyk Code, Retire.js offers no real-time feedback inside the editor. Developers must run it manually or rely on build-time automation to see results. - Stagnant development and limited ecosystem support
While still functional, Retire.js is no longer under active, frequent development. Its community is small, and its vulnerability database updates may lag behind more modern tools.
Retire.js remains a helpful utility for detecting outdated or vulnerable JavaScript libraries, especially in front-end applications and legacy projects. However, it is a narrow-purpose tool, not a full static code analysis solution. For broader coverage including vulnerability scanning, code logic analysis, and real-time feedback Retire.js should be supplemented with tools like Snyk, Semgrep, or SonarQube as part of a modern DevSecOps workflow.
OWASP Dependency-Check: Open-Source Dependency Vulnerability Scanner
OWASP Dependency-Check is a popular Software Composition Analysis (SCA) tool developed under the Open Web Application Security Project (OWASP). It is designed to identify known vulnerabilities (CVEs) in project dependencies by scanning software packages and comparing them against public vulnerability databases, such as the NVD (National Vulnerability Database).
While initially geared toward Java ecosystems (via Maven and Gradle), Dependency-Check also supports JavaScript and Node.js projects through analysis of package.json and package-lock.json files. The tool is available as a CLI utility, Maven plugin, Gradle plugin, Ant task, and Jenkins plugin, making it easy to automate in CI/CD pipelines and build systems.
Main features include:
- Scans JavaScript (Node.js) dependencies for known CVEs
- Parses
package.json,npm-shrinkwrap.json, andpackage-lock.jsonfiles - Integrates with CI/CD tools and build systems for automation
- Uses multiple data sources: NVD, Retire.js DB, OSS Index, and more
- Generates detailed HTML, XML, and JSON reports
- Supports suppression files to filter out false positives
- Free and open-source under the OWASP Foundation
Shortcomings of Dependency-Check:
- Focuses only on third-party dependencies
Dependency-Check does not scan your application’s custom JavaScript or TypeScript code. It cannot detect logic flaws, insecure patterns, or unsafe async usage within your own codebase. - No semantic or runtime analysis
Unlike tools like Semgrep or CodeQL, Dependency-Check performs no static code analysis. It doesn’t trace data flows, check API misuse, or model how vulnerable libraries are actually used. - JavaScript support is limited and less mature
Compared to Java, Node.js support is less robust. Dependency resolution, vulnerability mapping, and accuracy can be inconsistent in complex or monorepo structures, especially with deeply nested or transitive dependencies. - Slow and heavy in large projects
Because it uses multiple databases and performs heavyweight CVE mapping, Dependency-Check can become slow in large JavaScript or polyglot codebases. - False positives and negatives are common
Especially for JavaScript, CVE mapping is based on name and version heuristics, which can result in false positives (e.g., vulnerabilities flagged for unused libraries) or missed detections in the case of incomplete metadata. - No fix suggestions or remediation automation
Unlike tools such as Snyk or npm audit, Dependency-Check does not provide fixable upgrade paths, compatibility analysis, or automated remediation recommendations. - Lacks IDE integration or real-time developer feedback
It provides no inline suggestions or developer-first interfaces. Developers must review reports manually unless additional tooling is used to surface the output effectively.
OWASP Dependency-Check is a valuable, free tool for teams seeking to maintain awareness of vulnerabilities in JavaScript and Node.js dependencies, especially in regulated environments. However, it is a vulnerability database scanner, not a full static analysis tool. For effective JavaScript security, it should be paired with code-level analyzers (like Semgrep or CodeQL) and real-time linters (like ESLint or Snyk Code) to cover both dependency and in-code risk.
NodeJsScan: Static Application Security Testing
NodeJsScan is an open-source static application security testing (SAST) tool built specifically to detect security vulnerabilities in Node.js and JavaScript applications. It focuses on analyzing server-side JavaScript code (including Express-based applications) to uncover common security issues such as injection attacks, insecure cookie handling, path traversal, and sensitive data exposure.
NodeJsScan works by scanning source files against a set of predefined security rules tailored to the Node.js ecosystem. It is available as a web application, CLI tool, and Docker image, making it flexible for local scans or integration into DevSecOps pipelines. It also supports GitHub integration for inline security feedback via pull requests.
Main features include:
- Scans JavaScript and Node.js code for known security vulnerabilities
- Detects risks like XSS, SQL/NoSQL injection, unsafe eval, and insecure dependencies
- CLI and Docker support for easy integration into CI/CD workflows
- Predefined rules for Express, HTTP handling, JWT usage, and file system APIs
- GitHub integration for pull request scanning and inline alerts
- Offers a lightweight, developer-friendly alternative to heavyweight SAST tools
Shortcomings of NodeJsScan:
- Limited to security scanning only
NodeJsScan is focused exclusively on security issues. It does not analyze code quality, maintainability, architectural structure, or technical debt. Style issues, logic bugs, and best practice violations are outside its scope. - Lacks semantic and deep data flow analysis
Although it detects insecure patterns, NodeJsScan is pattern-based, not semantic. It cannot trace complex taint flows, asynchronous control paths, or multi-layer vulnerabilities as deeply as tools like CodeQL or Semgrep. - Small rule set and no custom rule framework
The predefined rule set is helpful for common vulnerabilities, but custom rule creation is limited. It doesn’t support a flexible or extensible query language, making it hard to adapt to unique project needs. - Minimal framework support
While Express is supported, other Node.js frameworks (like Hapi, Koa, NestJS) may not be fully covered. This limits the tool’s effectiveness in more diverse backend environments. - No IDE integration or real-time developer feedback
NodeJsScan is designed to be used in pipelines or via CLI, with no direct integration into development environments like VSCode. Developers don’t get live feedback as they write code. - No deep dependency or third-party package analysis
While NodeJsScan may flag insecure patterns, it does not scannode_modulesor compare packages against CVE databases. Tools like Snyk or OWASP Dependency-Check are required for full SCA (Software Composition Analysis). - Basic reporting and dashboarding
The open-source version lacks advanced reporting features or dashboards seen in enterprise tools. Results are provided as plain output or basic web UI, with limited policy enforcement capabilities.
NodeJsScan is a practical, focused solution for detecting security vulnerabilities in Node.js applications, especially for teams looking for open-source alternatives to commercial SAST products. However, it is not a complete static analysis platform and is best used in combination with tools like ESLint for code quality, Snyk for dependency scanning, and CodeQL or Semgrep for more advanced semantic analysis and customization.
JSCS: A Defunct Pioneer in Code Style Enforcement
JSCS, short for JavaScript Code Style, was once a popular static code analysis tool focused entirely on enforcing consistent coding styles in JavaScript. It helped developers catch and correct formatting inconsistencies such as indentation, spacing, brace styles, and quote usage based on customizable or preset rulesets (e.g., Google, Airbnb, jQuery). At its peak, JSCS was widely used to complement tools like JSHint and JSLint, which were focused more on logic and syntax correctness than formatting.
However, in 2016, JSCS was officially deprecated and merged into ESLint, which by then had become the dominant linter for JavaScript. ESLint incorporated JSCS’s style-checking rules and formatting capabilities, eventually rendering JSCS obsolete. Today, JSCS is no longer maintained, and its GitHub repository has been archived.
What JSCS offered:
- Enforced coding style rules like indentation, line spacing, quote usage, and semicolons
- Supported preset configurations (Airbnb, Google, etc.) and custom rule definitions
- CLI tool for command-line execution and integration with build pipelines
- JSON-based configuration for rule management
- Plugin support for popular editors (at the time) like Sublime Text and Atom
Shortcomings of JSCS (then and now):
- Deprecated and unsupported
JSCS has not been maintained since 2016. It receives no updates, bug fixes, or compatibility improvements. Its ecosystem has been entirely absorbed by ESLint, and any new projects should avoid it. - Focused only on style, not code quality or security
JSCS enforced formatting but did not catch bugs, code smells, or security vulnerabilities. It could not detect unused variables, unreachable code, or risky patterns functions that ESLint now handles comprehensively. - No type awareness or semantic analysis
JSCS did not understand code meaning it applied superficial formatting rules only. It lacked the ability to analyze function signatures, type relationships, or control flow logic. - No framework or modern syntax support
Even at its peak, JSCS lagged behind in supporting emerging JavaScript features (e.g., ES6+ syntax, JSX). As JavaScript rapidly evolved, JSCS became harder to maintain and configure for modern workflows. - No IDE-native feedback in modern environments
Today’s editors (e.g., VSCode, WebStorm) rely heavily on ESLint integrations. JSCS has no support for modern plugin systems and does not offer real-time linting or auto-fixing. - Fragmented developer experience
Before merging into ESLint, many projects had to run both JSCS (for style) and JSHint or JSLint (for logic), leading to duplicate configurations, inconsistent rules, and tool fatigue.
JSCS played a significant historical role in popularizing code style enforcement in the JavaScript ecosystem. However, it is now deprecated and obsolete, with all of its key features and use cases fully absorbed by ESLint, which remains the industry standard. Developers and teams should use ESLint (with Prettier or eslint-plugin-prettier) to enforce both style and quality under one unified configuration.
StandardJS: Zero-Config JS Style Guide and Linter
StandardJS is an opinionated, zero-configuration code style checker and formatter for JavaScript. It was created to promote consistent code formatting across projects without requiring developers to spend time configuring linting rules, plugins, or formatting tools. Based on ESLint under the hood, StandardJS bundles a strict and pre-defined ruleset, eliminating the need for .eslintrc files, plugin management, or custom formatting decisions.
Its simplicity and “just works” philosophy make it particularly appealing for small teams, open-source projects, and developers who want to avoid bikeshedding over code style. It enforces a clean, minimalistic style: no semicolons, consistent spacing, single quotes, and other readability-focused practices.
Main features include:
- Predefined strict linting and formatting rules with no configuration required
- Built-in formatting using ESLint + standard rules
- Command-line interface for formatting and linting in one step
- Plugins for editors like VSCode, Atom, Sublime Text, and WebStorm
- Compatible with Prettier-like formatting workflows but enforces additional quality rules
- Optional
standard --fixcommand to automatically correct issues
Shortcomings of StandardJS:
- Opinionated and inflexible
The core philosophy of StandardJS is no configuration. While this appeals to some teams, it’s restrictive for others. You cannot override or customize rules without forking or abandoning the tool in favor of raw ESLint. - Focused only on code style and quality not security or architectural insight
StandardJS does not support security checks, taint analysis, or deep static analysis. It won’t catch runtime vulnerabilities, insecure coding patterns, or data flow issues. - No type-awareness
StandardJS has no understanding of TypeScript’s type system or Flow annotations. While some support exists via community tooling, it’s not robust enough for complex type-driven JavaScript projects. - Does not scale well in enterprise environments
In large, polyglot, or team-diverse organizations, a one-size-fits-all style rule often breaks down. Teams may need custom rule enforcement, layered plugin support, or selective overrides none of which StandardJS supports. - Conflicts with Prettier in larger ecosystems
While StandardJS includes formatting, it may conflict with Prettier in projects that already use it for automated formatting. Teams using both can run into style mismatches unless carefully aligned. - Not suitable for code comprehension or modernization efforts
StandardJS does not provide dependency visualization, code duplication detection, or maintainability metrics. It is not a tool for auditing, technical debt assessment, or system-wide refactoring.
StandardJS is an excellent tool for enforcing consistent JavaScript style with zero configuration, ideal for small projects, fast prototypes, or teams who want to focus on code not config. However, it is not extensible or security-aware, and should not be used as a standalone static analysis solution in enterprise, secure, or highly customized environments. For full control, most mature teams will prefer ESLint with tailored rulesets and plugins to balance style, flexibility, and quality.
CodeClimate: Engineering Insights Through Static Analysis and Quality Metrics
CodeClimate is a static analysis and code quality platform that provides engineering teams with quantitative insights into maintainability, complexity, duplication, and technical debt. It supports JavaScript, TypeScript, and many other languages, and is built to serve both developers and engineering leaders by tying code quality directly to development workflow metrics and organizational KPIs.
The platform combines static analysis with team performance metrics, making it well-suited for companies that want to integrate quality standards, code review enforcement, and visibility into velocity, throughput, and churn. It offers integrations with GitHub, GitLab, and Bitbucket, enabling inline code review feedback, maintainability scores, and historical trends.
Main features include:
- Static code analysis for JavaScript, TypeScript, and other languages
- Maintainability scoring based on complexity, duplication, and linting rules
- Quality gates and inline feedback for pull requests
- Customizable engines and rule configurations (built on ESLint, PMD, etc.)
- Integration with GitHub Actions, Travis CI, and other CI/CD pipelines
- Engineering analytics on team productivity and code health trends
- Cloud-based and self-hosted options for enterprises
Shortcomings of CodeClimate:
- Not specialized in JavaScript
While it supports JavaScript and TypeScript, CodeClimate is a general-purpose platform. It lacks JavaScript-specific depth found in tools like ESLint, Semgrep, or SonarQube, especially for framework-specific issues (e.g., React, Vue, Node.js APIs). - Static analysis engine customization is limited or complex
Although it allows custom configuration via YAML and open-source engines, managing and tuning engines (e.g., eslint, duplication, complexity) can be cumbersome and unintuitive for developers unfamiliar with its architecture. - No semantic or taint analysis
CodeClimate does not trace data flow, tainted input, or asynchronous logic in depth. It is not a security tool and cannot detect injection risks, broken auth, or insecure deserialization without third-party integration. - Limited support for TypeScript-specific features
CodeClimate’s handling of TypeScript is limited compared to tools like TSC or TypeScript-aware ESLint setups. It may not fully interpret types, interfaces, or strict mode configuration nuances. - Requires configuration for accurate results
Although marketed as “plug and play,” many projects require extensive tuning to reduce noise and false positives—especially in monorepos or non-standard directory structures. - Commercial focus with limited free usage
CodeClimate offers limited functionality in its free plan. For most advanced features (dashboards, metrics, historical insights, team comparisons), a paid plan is required. - No real-time IDE feedback
Developers won’t receive live feedback in their editors. CodeClimate surfaces insights at the pull request and CI stages, which can delay error discovery and slow feedback loops.
CodeClimate is an effective platform for organizations that want to connect static analysis to code quality metrics, team performance, and engineering goals. It offers solid high-level insights and integrates well into PR workflows. However, for teams that need deeper JavaScript-specific security, semantic, or architectural analysis, CodeClimate works best as part of a broader toolchain paired with tools like ESLint, Semgrep, or Snyk Code for comprehensive coverage.
Coverity (Synopsys): Enterprise-Grade Static Analysis with a Security Focus
Coverity, developed by Synopsys, is an enterprise-grade static application security testing (SAST) tool designed to detect code quality issues, logic defects, and security vulnerabilities across a broad range of language including JavaScript and TypeScript. It is a key part of Synopsys’s application security suite, often used in regulated industries like finance, healthcare, and defense to support secure SDLC practices.
Coverity performs deep semantic analysis of code to uncover issues such as null dereferencing, resource leaks, unvalidated input, and insecure API usage. For JavaScript, it supports both server-side (Node.js) and front-end applications. Coverity integrates with CI/CD pipelines and provides detailed dashboards, compliance tracking, and role-based access for larger teams.
Main features include:
- Deep static analysis of JavaScript, TypeScript, and other major languages
- Detection of security vulnerabilities, logic bugs, and coding anti-patterns
- OWASP, CWE, and CERT compliance reporting
- Integration with GitHub, GitLab, Azure DevOps, Jenkins, and more
- Policy enforcement and issue tracking in pull requests and pipelines
- Enterprise dashboards with risk scoring, remediation guidance, and audit trails
- Supports monorepos and large-scale codebases
Shortcomings of Coverity:
- Primarily designed for enterprise use
Coverity is built for large, regulated organizations. It may be overkill for smaller teams or open-source projects looking for lightweight linting or real-time feedback. - High cost and complex licensing
Coverity’s commercial model is expensive and tailored for enterprise buyers. Pricing is not transparent, and deploying it may require dedicated budget and legal approvals. - Steep learning curve and setup complexity
Configuration, environment setup, and integration require significant effort, particularly for non-Java or C/C++ ecosystems. JavaScript projects may need custom tuning for optimal results. - Slow scan times in large projects
Due to the depth of analysis, Coverity can be computationally heavy, making scans slow for large JavaScript/TypeScript applications, especially those using modern frameworks like React or Next.js. - Limited modern JavaScript ecosystem awareness
While Coverity supports JavaScript, it may lag in understanding newer ES features (like decorators, optional chaining, dynamic imports) or nuanced patterns common in frameworks like Vue, Svelte, or Angular. - No formatting, stylistic, or best-practice linting
Unlike tools such as ESLint or Prettier, Coverity does not enforce stylistic rules. It cannot replace day-to-day developer tools for code consistency or readability enforcement. - No IDE-native feedback
Developers won’t see results directly in editors like VSCode or WebStorm. Issue discovery is delayed to scan runs, which impacts fast iteration and developer experience unless paired with other tools.
Coverity offers powerful static analysis capabilities for enterprise JavaScript security and defect prevention, especially in contexts where regulatory compliance and risk management are critical. However, it is not a substitute for developer-first tools like ESLint, Semgrep, or Snyk Code, and it requires considerable investment in terms of resources, training, and infrastructure. Coverity works best as a backstop in a layered AppSec strategy, complementing more agile tools in a modern JavaScript pipeline.
Veracode Static Analysis: Cloud-Based SAST for Enterprise-Grade Application Security
Veracode Static Analysis is a cloud-native static application security testing (SAST) solution designed to help organizations identify and remediate vulnerabilities in source code, binaries, and bytecode without requiring access to the full build environment. It supports a wide range of programming languages, including JavaScript and TypeScript, and is widely adopted in large enterprises for secure SDLC integration, governance, and compliance.
Veracode performs automated scans on applications to detect vulnerabilities like injection flaws, unsafe data handling, broken authentication, and other high-risk security issues. It integrates with CI/CD pipelines, version control systems, and DevOps tools, and provides developers with remediation guidance directly linked to each vulnerability. JavaScript support extends to both frontend and backend frameworks (e.g., Node.js).
Main features include:
- Static analysis for JavaScript, TypeScript, and over 20 other languages
- Detection of OWASP Top 10 and CWE vulnerabilities in code and frameworks
- Cloud-based scanning for rapid onboarding and centralized management
- Policy enforcement dashboards and compliance tracking (e.g., PCI-DSS, HIPAA, ISO)
- Detailed remediation guidance, risk ratings, and issue triaging
- Seamless integration with GitHub, Azure DevOps, Jenkins, GitLab, Bitbucket, and Jira
- Application security posture reporting for executive and audit stakeholders
Shortcomings of Veracode Static Analysis:
- Primarily focused on security, not code quality
Veracode does not enforce stylistic consistency, best practices, or architectural patterns. It will not catch code smells, formatting issues, or non-security-related technical debt. - No IDE-native scanning experience
Veracode Static Analysis is cloud-based and does not provide real-time editor feedback (e.g., in VSCode or WebStorm). Developers must wait for scan results from CI or manual uploads. - Limited JavaScript-specific customization
While Veracode supports JavaScript, it lacks deep customization for JS-specific frameworks (e.g., React, Vue, Svelte). Custom rule tuning is less granular than tools like Semgrep or CodeQL. - Requires full builds or packaged code for scanning
To scan effectively, Veracode typically requires bundled, built, or zipped code. This can slow down feedback loops, especially in frontend-heavy workflows where incremental changes are frequent. - Not designed for modern JavaScript developer workflows
Veracode lacks support for linting, formatting, or test-driven rules. It is not a substitute for ESLint or Prettier and doesn’t integrate easily into fast-paced, feedback-driven development practices. - False positives and limited transparency
While effective at identifying known vulnerabilities, Veracode can produce false positives, particularly in loosely typed or asynchronous code. Developers have limited visibility into how issues are detected, making triage harder. - Requires commercial licensing and vendor lock-in
Veracode is a premium, enterprise product. It is not suitable for small teams or open-source projects due to cost, licensing structure, and lack of a self-hosted open-source equivalent.
Veracode Static Analysis is a robust, enterprise-focused security scanner that excels at identifying high-risk vulnerabilities in JavaScript codebases, particularly where compliance, risk reporting, and centralized policy enforcement are required. However, it is not designed for developer productivity, real-time iteration, or comprehensive code health. For full-spectrum analysis, Veracode should be paired with tools like ESLint (for quality), Prettier (for style), and Semgrep or CodeQL (for context-aware security rules and DevSecOps integration).
Navigating the JS Static Analysis Tool Landscape
The modern JavaScript ecosystem is rich with tooling, offering developers everything from quick formatting fixes to enterprise-level vulnerability detection. But no single tool can address every dimension of code quality, security, and maintainability. The real power lies in using the right combination and in selecting tools that align with your organization’s complexity, team structure, and long-term goals.
Foundational tools like ESLint, Prettier, and TypeScript help ensure correctness, consistency, and clarity at the developer level. For security, a mix of Semgrep, Snyk Code, and CodeQL offers real-time feedback and deep vulnerability detection. And for style and simplicity, options like StandardJS still thrive in lean, fast-paced projects.
But as codebases and businesses scale, especially in regulated or high-stakes environments, the need for comprehensive insight into code architecture, dependencies, and behavior becomes critical. That’s where tools like SMART TS XL step in.
Why SMART TS XL Deserves Attention in Enterprise JS Environments
While many tools focus on individual files or small modules, SMART TS XL is uniquely positioned to give enterprise engineering teams a holistic view of their entire application landscape. Originally designed to analyze complex legacy systems like COBOL, SMART TS XL has evolved to support modern JavaScript and multi-language ecosystems, delivering value in areas where most linters or security scanners stop short.
Key reasons enterprise teams are adopting SMART TS XL:
- System-wide control and data flow visibility, across modular JS codebases
- Cross-platform insight (legacy + modern), ideal for hybrid stacks and digital transformation
- Enterprise-ready metadata modeling, impact analysis, and logic comprehension
- Scalable to large monorepos and distributed teams, with collaborative analysis environments
- Complements developer tools, filling the visibility and architecture gap left by ESLint, Prettier, and others
For organizations aiming to go beyond linting and vulnerability checks, SMART TS XL offers the clarity and control needed to govern complexity, modernize legacy code, and make architectural decisions with confidence.
Choosing the right JavaScript static analysis stack is no longer just about code correctness it’s about governance, risk reduction, maintainability, and team velocity. Smaller teams will benefit from lightweight, developer-centric tools. But for enterprises managing critical, high-volume, or multi-generational code, tools like SMART TS XL offer the strategic depth to guide transformation, ensure long-term sustainability, and scale secure, high-quality software across the entire engineering lifecycle.