

Enterprise software landscapes entering 2026 continue to grow in structural complexity rather than simplicity. Decades of accumulated logic, mixed programming languages, hybrid deployment models, and tightly coupled dependencies increasingly constrain how change can be introduced without unintended consequences. In this environment, static code analysis tools are no longer viewed as optional quality checks, but as foundational instruments for understanding how systems actually behave before any modernization, refactoring, or security initiative begins.
What differentiates enterprise-scale static code analysis from developer-oriented tooling is not the ability to flag isolated defects, but the capacity to reason across entire application estates. Large organizations rarely operate within a single runtime or architectural pattern. Mainframe batch workloads coexist with distributed services, legacy interfaces intersect with cloud-native APIs, and regulatory requirements impose additional constraints on how risk can be measured and mitigated. Static analysis must therefore operate across boundaries, exposing execution paths, hidden dependencies, and structural risks that are otherwise invisible through testing alone.
SMART TS XL
Ideal Static Code Analyses Solution for Companies with Large Distibuted Systems and Assets
Explore nowThe growing emphasis on continuous delivery and accelerated modernization has further elevated the role of analysis-driven insight. As enterprises pursue broader application modernization initiatives, the cost of incomplete understanding becomes increasingly apparent. Refactoring decisions made without full visibility into control flow, data propagation, or cross-system coupling often introduce instability, performance regressions, or compliance exposure that only surface after deployment. Static code analysis tools are now expected to reduce this uncertainty by providing architectural clarity before change is executed.
Against this backdrop, the criteria used to evaluate static code analysis tools in 2026 are shifting. Accuracy alone is insufficient. Enterprises require depth of analysis, scalability across millions of lines of code, support for heterogeneous environments, and the ability to translate technical findings into actionable insight for architects, platform leaders, and risk owners. The following comparison examines how leading enterprise static code analysis tools perform against these evolving demands, and how their capabilities align with the realities of large-scale, mission-critical systems.
Enterprise Static Code Analysis Tools Comparison and Ranking for 2026
The comparison below evaluates leading static code analysis tools against criteria that matter in large-scale enterprise environments rather than individual development teams. Each tool is assessed based on analysis depth, scalability across heterogeneous systems, support for legacy and modern platforms, and its ability to surface meaningful insight from complex dependency structures. The ranking reflects how effectively these tools enable architectural understanding, risk identification, and informed decision-making in environments where change carries significant operational and regulatory consequences.
SMART TS XL
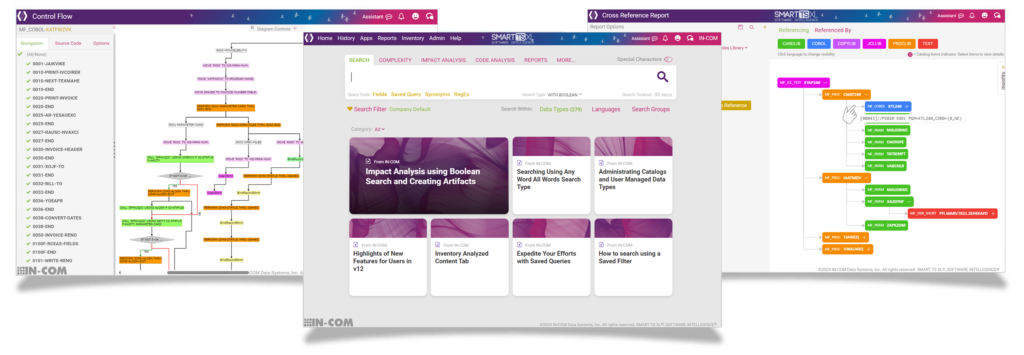
SMART TS XL is an enterprise static code analysis, impact assessment, and application intelligence platform designed for large-scale, heterogeneous software estates. It is built to support organizations operating across mainframe, midrange, and distributed environments where decades of accumulated logic, batch processing, and cross-platform dependencies make change inherently risky. Rather than focusing on isolated code quality findings, SMART TS XL is designed to expose how applications actually behave by making execution paths, data relationships, and dependency structures visible across entire portfolios.
The platform operates as a high-performance, web-based system capable of indexing and analyzing billions of lines of code and associated artifacts in seconds. By offloading analysis workloads from production systems and centralizing insight in a shared environment, SMART TS XL supports thousands of concurrent users without performance degradation. This scale makes it suitable not only for development teams, but also for architects, modernization leads, production support, audit, and compliance stakeholders who require consistent, evidence-based visibility into complex systems. Request a Demo.
Enterprise-Scale Static Analysis and Discovery
At its core, SMART TS XL provides deep static analysis across a broad set of programming languages, job control constructs, databases, and supporting artifacts. It supports legacy and modern technologies including COBOL, PL/I, Natural, RPG, Assembler, Java, C#, Python, VB6, UNIX scripts, JCL, PROCs, CICS artifacts, MQ definitions, database schemas, and structured documents. Source code, batch logic, configuration files, and even non-code artifacts such as documentation and diagrams can be indexed and analyzed together, allowing relationships to be discovered across traditionally siloed repositories.
This unified discovery capability allows organizations to move beyond file-level inspection and toward system-level understanding. Programs, jobs, fields, files, tables, and messages can be traced across platforms, revealing how business logic flows through batch chains, online transactions, and downstream reporting processes. These relationships are surfaced through interactive cross-reference reports, dependency maps, and navigable execution views rather than static lists.
Cross-Platform Impact Analysis and Dependency Mapping
SMART TS XL places particular emphasis on cross-platform impact analysis. Changes introduced in one part of an application rarely remain isolated in enterprise environments, especially where mainframe workloads interact with distributed services and shared data stores. SMART TS XL analyzes call relationships, data usage, job execution paths, and control flow to identify upstream and downstream impact zones across languages and systems.
Dependency mapping capabilities present these relationships visually using interactive, color-coded diagrams that highlight callers, callees, data producers, and consumers. Impact analysis can be initiated from a program, a field, a database element, a job step, or even from search results, allowing teams to scope changes precisely before development begins. This approach reduces missed dependencies, limits over-testing, and provides a defensible basis for change planning and risk assessment.
Execution-Oriented Views of Batch and Program Logic
For environments with complex batch processing, SMART TS XL provides runtime-style understanding without executing code. COBOL and JCL expansion capabilities resolve copybooks, PROCs, symbolics, and overrides to present logic as it effectively runs in production. Batch chains can be traced end to end, exposing which programs execute, in what order, and with which parameters.
Control flow diagrams and flowcharts translate deeply nested logic into navigable visual representations. These views make it possible to understand execution behavior, identify dead or unreachable code paths, and analyze branching complexity without relying on tribal knowledge or manual walkthroughs. Field tracking diagrams further extend this capability by tracing how data elements are created, transformed, and propagated across programs, jobs, and databases, supporting safe structural changes and regulatory reviews.
Advanced Search, Pattern Detection, and Precision Analysis
SMART TS XL includes a high-performance enterprise search engine optimized for large, mixed-technology codebases. It supports complex Boolean logic, proximity searches, block searches, regular expressions, synonym handling, and fine-grained filters that restrict analysis to specific languages, data types, or code sections. Layered search techniques allow users to progressively narrow large result sets into precise scopes suitable for impact analysis, audits, or modernization assessments.
These search capabilities are tightly integrated with cross-reference, impact, complexity, and visualization functions. Results can be pivoted directly into dependency views, reports, or further analysis workflows, reducing the friction between discovery and decision-making. Saved and parameterized queries allow organizations to standardize risk checks and repeatable analysis patterns across teams and projects.
Complexity Analysis and Risk Quantification
SMART TS XL provides portfolio-level complexity analysis that extends beyond individual programs. Complexity metrics such as lines of code, cyclomatic complexity, and Halstead measures can be calculated across targeted subsets of applications defined by search results or impact zones. This enables teams to quantify technical risk within specific business functions or modernization candidates rather than relying on coarse, application-wide averages.
By combining complexity metrics with dependency and impact analysis, SMART TS XL supports more realistic effort estimation and prioritization. Areas with high coupling and high complexity can be identified early, allowing modernization and remediation initiatives to be sequenced based on actual structural risk rather than assumptions.
Knowledge Transfer, Audit Readiness, and Governance Support
A recurring challenge in large enterprises is the loss of institutional knowledge as systems age and experienced staff retire or rotate. SMART TS XL addresses this by centralizing application knowledge in a searchable, explorable platform that captures how systems are structured and how they behave. Documentation, reports, diagrams, and evidence artifacts can be generated and shared to support onboarding, audits, and regulatory requests.
Export capabilities allow analysis results to be packaged as timestamped, evidence-ready artifacts suitable for compliance reviews, change approvals, and external audits. Access controls and usage tracking support governance requirements, particularly in environments with offshore development or outsourced maintenance models.
Deployment, Integration, and Operational Fit
SMART TS XL is designed for rapid deployment and minimal operational disruption. Installations can be completed within hours, with connectors available to ingest data from mainframe environments, distributed source control systems, databases, and shared repositories. Both full and incremental data loads are supported, enabling environments to remain current without requiring constant manual intervention.
Automation capabilities allow analysis processes to run unattended, supporting continuous insight generation aligned with enterprise change cycles. By centralizing analysis on cost-effective infrastructure, organizations can reduce reliance on expensive production resources while increasing analytical depth and availability across teams.
SonarQube Enterprise Edition

SonarQube Enterprise Edition is a static code analysis platform designed to support large development organizations seeking consistent enforcement of code quality, maintainability, and security standards across modern software portfolios. Its primary role within enterprise environments is to act as a continuous inspection layer embedded within development workflows, providing early feedback on code issues before changes reach production. In portfolios where review throughput becomes a bottleneck, it is often positioned alongside broader code review tools to formalize quality gating and reduce variation across teams.
Unlike portfolio-level analysis platforms, SonarQube’s strength lies in its ability to operate close to the developer workflow. Analysis is typically triggered as part of build pipelines or pull request validation, enabling teams to detect code smells, bugs, and security issues incrementally as code evolves. This aligns with organizations that standardize automated checks across delivery pipelines, including approaches described in CI/CD pipelines, where static analysis becomes a repeatable control rather than an ad hoc review step.
Rule-Based Static Analysis and Quality Gates
At the core of SonarQube Enterprise Edition is a rule-based static analysis engine that evaluates source code against a large and configurable ruleset. These rules cover common categories such as maintainability issues, reliability defects, and security vulnerabilities. Findings are classified by severity and mapped to quality gates that determine whether code can progress through the delivery pipeline.
Quality gates are a central mechanism for enforcing organizational standards at scale. Enterprises can define thresholds for new code coverage, defect density, and vulnerability exposure, ensuring that changes meet predefined criteria before integration. This capability is particularly valuable in environments with distributed teams, outsourced development, or high developer turnover, where consistent enforcement reduces reliance on manual reviews.
Language Coverage and Development Ecosystem Integration
SonarQube supports a broad set of modern programming languages, including Java, C#, JavaScript, TypeScript, Python, and others commonly used in enterprise application development. Its ecosystem of plugins and integrations allows it to connect with popular CI/CD platforms, source control systems, and issue trackers. This tight integration makes it well suited for organizations that prioritize automated quality control as part of their delivery pipelines.
However, SonarQube’s analysis model is primarily source-centric and repository-scoped. While it can analyze multiple projects in parallel, its understanding of relationships across repositories, platforms, and execution contexts is limited. Analysis is typically confined to individual applications or services rather than spanning entire enterprise estates with shared data, batch workflows, or cross-platform dependencies.
Security Analysis and Compliance Support
In its enterprise editions, SonarQube includes enhanced security analysis capabilities aligned with common vulnerability categories. It can identify patterns associated with injection flaws, insecure configurations, and misuse of APIs. Findings are presented in a format accessible to both developers and security teams, supporting remediation workflows within existing tooling.
From a compliance perspective, SonarQube provides traceability and reporting that help demonstrate adherence to internal coding standards and security policies. Reports can be generated to show issue trends, remediation progress, and quality gate compliance over time. While these features support audit readiness within development teams, they are less focused on producing system-level evidence of execution behavior or cross-system impact.
Scalability Characteristics and Operational Considerations
SonarQube Enterprise Edition is designed to scale across large numbers of repositories and development teams, particularly when deployed in distributed or containerized environments. Its performance scales with available infrastructure, making it suitable for organizations with high commit volumes and frequent analysis cycles. Centralized dashboards provide aggregated visibility across projects, helping leadership monitor quality trends at a high level.
That said, SonarQube’s scalability is primarily horizontal across projects rather than vertical across system complexity. It does not resolve runtime execution paths, batch orchestration logic, or deep data lineage across heterogeneous platforms. In environments dominated by mainframe workloads, batch scheduling, or tightly coupled legacy systems, SonarQube is often used as a complementary tool rather than a standalone source of architectural insight.
Typical Enterprise Use Cases and Limitations
SonarQube Enterprise Edition is most effective in enterprises with strong DevOps maturity, standardized development stacks, and a focus on preventing quality degradation in actively developed code. It excels at enforcing consistency, reducing code smells, and integrating quality checks into fast-moving delivery pipelines.
Its limitations become more apparent in modernization scenarios that require understanding how changes ripple across large, interconnected systems. SonarQube does not attempt to model execution order, data propagation across jobs and platforms, or system-wide dependency chains. As a result, it is often paired with deeper analysis platforms when enterprises need to assess modernization risk, batch impact, or cross-portfolio change effects.
Checkmarx One

Checkmarx One is an enterprise-focused application security platform centered on static application security testing within modern development and delivery pipelines. Its primary role in large organizations is to identify security vulnerabilities early in the software lifecycle, particularly in environments where frequent releases, distributed teams, and cloud-native architectures increase exposure to exploitable flaws. Rather than attempting to model system-wide execution behavior, Checkmarx One concentrates on detecting insecure coding patterns and configuration weaknesses that align with recognized security taxonomies.
The platform is typically adopted by enterprises with mature DevSecOps practices, where security analysis is expected to operate continuously alongside development rather than as a post-release control. In such environments, Checkmarx One functions as a preventative mechanism, aiming to reduce the likelihood that vulnerable code paths are introduced into production systems.
Static Application Security Testing Focus
At the core of Checkmarx One is a static application security testing engine optimized to detect vulnerabilities at the source code level. Analysis is performed without executing applications, allowing issues to be identified early, often during code commit or build stages. The platform maps findings to well-known vulnerability categories, supporting security teams that rely on standardized risk classification frameworks such as OWASP vulnerabilities to prioritize remediation efforts.
The emphasis on security-specific findings differentiates Checkmarx One from general-purpose static analysis tools. Rather than highlighting maintainability or architectural concerns, the platform focuses on weaknesses that could lead to data exposure, unauthorized access, or privilege escalation. This specialization makes it particularly relevant in regulated industries where vulnerability disclosure and remediation timelines are closely monitored.
Integration into Enterprise DevSecOps Pipelines
Checkmarx One is designed to integrate tightly with CI/CD pipelines and developer workflows. Scans can be triggered automatically as part of build processes, pull requests, or release gates, ensuring that security analysis occurs consistently and without manual intervention. Results are surfaced through dashboards and integrations with issue tracking systems, enabling findings to be routed directly to development teams for remediation.
This pipeline-centric operating model supports high development velocity while maintaining a baseline level of security assurance. However, the focus on individual repositories and services means analysis is generally scoped to discrete codebases. While this aligns well with microservices and modular architectures, it limits visibility into cross-application dependencies or multi-platform execution chains common in long-lived enterprise systems.
Language Coverage and Cloud-Native Orientation
Checkmarx One supports a wide range of modern programming languages and frameworks commonly used in enterprise and cloud-native development. This breadth enables consistent security scanning across heterogeneous development teams without requiring multiple specialized tools. The platform’s cloud-native delivery model further simplifies deployment and scaling, reducing operational overhead for organizations managing large numbers of applications.
That said, support for legacy technologies and batch-oriented environments is more limited. Mainframe languages, job control constructs, and tightly coupled legacy workflows are typically outside the platform’s primary scope. As a result, Checkmarx One is often deployed alongside other analysis tools when enterprises must secure both modern and legacy components within the same application landscape.
Risk Reporting and Governance Alignment
From a governance perspective, Checkmarx One provides reporting capabilities that support vulnerability tracking, remediation status, and compliance reporting. Security leaders can monitor trends across applications, teams, and time periods, helping to demonstrate adherence to internal policies and external regulatory expectations. Findings can be aggregated to show overall risk posture, enabling prioritization at the portfolio level.
However, these reports are focused on vulnerability presence rather than operational impact. The platform does not attempt to quantify how a vulnerability propagates through execution paths or how it interacts with batch processing, data flows, or downstream systems. This distinction is important in enterprises where understanding blast radius and systemic risk is as critical as identifying individual weaknesses.
Typical Enterprise Use Cases and Constraints
Checkmarx One is most effective in enterprises seeking to embed security controls directly into fast-moving development environments. It excels at identifying code-level security issues early, reducing rework, and supporting consistent vulnerability management across large developer populations. For organizations modernizing toward cloud-native architectures, it provides a scalable mechanism for enforcing security hygiene.
Its limitations emerge in scenarios that require holistic understanding of application behavior, dependency chains, or modernization impact across heterogeneous systems. In such cases, Checkmarx One is typically positioned as a specialized security layer rather than a comprehensive analysis platform, complementing tools that focus on execution insight, dependency mapping, and structural risk assessment.
Fortify Static Code Analyzer

Fortify Static Code Analyzer is an enterprise-grade static application security testing platform designed to identify security vulnerabilities in large, regulated software environments. Its primary role within enterprises is to provide systematic detection of coding patterns that introduce security risk, particularly in organizations where compliance, auditability, and formal risk management processes shape how software changes are governed. Fortify is commonly adopted in sectors where security assurance must be demonstrable, repeatable, and aligned with established enterprise controls.
Rather than emphasizing developer-centric feedback loops, Fortify is often positioned as a centralized security control within broader governance frameworks. It supports organizations that require standardized vulnerability classification, consistent reporting, and traceability across large portfolios of applications developed by distributed or third-party teams.
Security-Centric Static Analysis Engine
At the core of Fortify Static Code Analyzer is a security-focused analysis engine that inspects source code to identify vulnerabilities without executing applications. The engine applies a comprehensive set of security rules designed to detect weaknesses such as injection flaws, insecure data handling, authentication errors, and improper use of cryptographic functions. Findings are categorized by severity and type, enabling security teams to assess risk in a structured and consistent manner.
The emphasis on security correctness differentiates Fortify from general-purpose static analysis tools. Analysis depth is tuned toward identifying exploitable conditions rather than maintainability or architectural concerns. This specialization makes Fortify particularly suitable for environments where vulnerability detection is prioritized over broader system comprehension.
Alignment with Enterprise Risk and Compliance Programs
Fortify is frequently integrated into enterprise security and governance programs where software risk is managed alongside other operational and regulatory risks. Its reporting and evidence-generation capabilities support internal audits, external assessments, and regulatory reviews. Results can be aggregated across applications and business units, providing security leadership with visibility into risk exposure at scale.
This alignment with formal IT risk management processes makes Fortify a common choice in organizations that must demonstrate ongoing control effectiveness. Reports can be used to show vulnerability trends, remediation progress, and compliance with internal security policies, supporting defensible decision-making during audits or incident reviews.
Language Coverage and Deployment Characteristics
Fortify Static Code Analyzer supports a broad range of programming languages commonly found in enterprise environments, including both modern application stacks and selected legacy technologies. This allows organizations to apply a consistent security analysis approach across diverse development teams and technology domains. Deployment models vary, with Fortify often installed on-premises or within controlled enterprise environments to meet data residency and security requirements.
However, analysis is generally performed at the application or project level. While Fortify can scale across many applications, it does not attempt to resolve execution order, batch orchestration, or cross-application data flows. As a result, its perspective on risk remains localized to code artifacts rather than system-wide behavior.
Integration into Secure Development Lifecycles
Fortify is typically integrated into secure development lifecycles as a gating mechanism rather than a continuous exploratory tool. Scans may be triggered at defined stages such as pre-release reviews, major change windows, or compliance checkpoints. This operating model aligns with organizations that favor controlled release processes and formal approvals over continuous deployment.
While integrations with CI/CD tooling are available, Fortify’s usage patterns often reflect a balance between automation and centralized oversight. Security findings are reviewed by specialized teams who assess remediation requirements and risk acceptance decisions, reinforcing governance consistency across the enterprise.
Typical Enterprise Use Cases and Constraints
Fortify Static Code Analyzer is most effective in enterprises where security assurance, audit readiness, and regulatory compliance are dominant drivers. It provides a structured, defensible approach to identifying code-level security vulnerabilities and demonstrating that controls are in place to detect and address them.
Its limitations become evident in scenarios that require understanding how vulnerabilities interact with execution behavior, batch processing, or cross-platform dependencies. Fortify does not model runtime behavior or system-wide impact, and it is often complemented by tools that provide deeper insight into application structure, dependency chains, and modernization risk across heterogeneous environments.
CAST Highlight

CAST Highlight is an enterprise application intelligence and portfolio assessment platform designed to provide high-level visibility into software quality, risk, and modernization readiness across large application estates. Its primary role within enterprise environments is to support strategic decision-making by summarizing structural characteristics, technical debt indicators, and cloud suitability signals rather than performing deep, execution-oriented code analysis. CAST Highlight is often adopted early in modernization programs to establish a baseline understanding of portfolio health.
Unlike developer-centric static analysis tools, CAST Highlight operates at an aggregate level. It is intended to help architects, portfolio managers, and transformation leaders compare applications, identify candidates for modernization, and prioritize remediation efforts across hundreds or thousands of systems.
Portfolio-Level Analysis and Software Intelligence
At the core of CAST Highlight is a lightweight analysis engine that extracts structural metadata from application source code and configuration artifacts. This data is normalized into a common analytical model that allows diverse applications to be assessed using consistent criteria. Metrics related to code quality, maintainability, security exposure, and architectural fitness are calculated and presented through dashboards and comparative views.
These capabilities align with broader software intelligence initiatives, where the goal is to transform raw code artifacts into decision-ready insight for non-developer stakeholders. By abstracting complexity into standardized indicators, CAST Highlight enables leadership teams to reason about large portfolios without needing to engage in detailed code inspection.
Modernization Readiness and Cloud Suitability Assessment
CAST Highlight places particular emphasis on evaluating applications for modernization and cloud migration readiness. It assesses factors such as framework usage, dependency patterns, and technology currency to estimate the effort and risk associated with moving applications to modern platforms. Results are often used to group applications into categories such as rehost, refactor, replace, or retire.
This assessment-driven approach supports early-stage planning and budgeting activities. Enterprises can use CAST Highlight outputs to build modernization roadmaps, estimate transformation scope, and communicate risk profiles to business stakeholders. However, the analysis is intentionally broad and does not attempt to model detailed execution behavior or transformation side effects.
Security and Technical Debt Indicators
In addition to modernization signals, CAST Highlight provides high-level indicators related to security weaknesses and technical debt. These indicators are derived from known patterns associated with increased maintenance cost or elevated vulnerability exposure. The intent is not to replace dedicated security scanning tools, but to highlight areas where deeper investigation may be warranted.
Because findings are aggregated, they are best suited for comparative analysis rather than remediation planning. Security and debt indicators help organizations understand relative risk distribution across portfolios, but they do not identify specific execution paths, data flows, or operational dependencies that would be impacted by code changes.
Scalability and Operational Model
CAST Highlight is designed to scale efficiently across very large application portfolios. Its lightweight analysis approach minimizes processing overhead and enables rapid onboarding of new applications. This makes it particularly suitable for enterprises conducting broad surveys of their software landscapes during mergers, divestitures, or early modernization initiatives.
The tradeoff for this scalability is analytical depth. CAST Highlight does not resolve call graphs, batch execution chains, or cross-platform data propagation. As a result, it is often used in conjunction with deeper analysis tools once specific applications or transformation initiatives move from planning into execution.
Typical Enterprise Use Cases and Constraints
CAST Highlight is most effective in enterprises that need a high-level, comparative view of application portfolios to support strategic planning. It excels at identifying modernization candidates, estimating transformation complexity, and communicating technical risk to non-technical stakeholders.
Its limitations become apparent when organizations require precise understanding of how changes affect execution behavior, dependency chains, or operational stability. CAST Highlight does not provide the execution-level insight needed to safely implement refactoring or modernization activities, and it is typically complemented by tools that focus on detailed impact analysis and behavioral visibility within selected applications.
CAST Imaging
CAST Imaging is an enterprise application intelligence platform focused on architectural analysis and structural dependency visualization across complex software systems. Its primary role within large organizations is to expose how applications are assembled, how components interact, and where structural coupling introduces risk. CAST Imaging is typically used by architects and modernization teams who require a system-level understanding of application structure before planning refactoring, migration, or decomposition initiatives.
Rather than operating as a code inspection or security scanning tool, CAST Imaging emphasizes architectural comprehension. It transforms source code and configuration artifacts into navigable models that illustrate relationships between components, layers, and technologies, enabling stakeholders to reason about complexity at scale.
Architectural Mapping and Dependency Visualization
At the core of CAST Imaging is its ability to generate detailed architectural representations of applications and application portfolios. These representations include component diagrams, interaction maps, and layered views that reveal how modules communicate and depend on one another. By visualizing structural relationships, CAST Imaging enables teams to identify tight coupling, circular dependencies, and architectural violations that are difficult to detect through file-level analysis.
These visual models align closely with practices centered on dependency graphs, where understanding structural interconnections is essential for managing risk in large systems. CAST Imaging allows users to traverse dependencies interactively, moving from high-level architectural views down to more granular representations as needed.
Multi-Technology and Cross-Application Coverage
CAST Imaging supports analysis across a wide range of programming languages, frameworks, and platforms commonly found in enterprise environments. This breadth allows it to model heterogeneous systems composed of legacy components, distributed services, and shared databases. Cross-application analysis capabilities enable teams to understand how individual systems fit within larger portfolios and how changes in one application may influence others.
However, the analysis remains structural rather than behavioral. CAST Imaging models static relationships between components, but it does not simulate execution order, runtime conditions, or batch scheduling logic. As a result, it provides clarity on how systems are connected, but not necessarily on how they behave during execution.
Support for Modernization and Architectural Governance
CAST Imaging is frequently used to support modernization initiatives where architectural clarity is a prerequisite for change. By exposing violations of architectural principles and identifying areas of excessive coupling, it helps teams plan incremental transformation strategies. These insights can inform decisions about service extraction, interface redesign, or phased migration approaches.
In governance contexts, CAST Imaging can also be used to assess architectural compliance against defined standards. Deviations from target architectures can be identified and documented, supporting oversight and remediation planning. This makes it valuable in organizations that enforce architectural controls as part of their change management processes.
Scalability and Portfolio Modeling Considerations
The platform is designed to scale across large applications and portfolios, generating architectural models that can be shared among stakeholders. Its visualization-centric approach supports collaborative analysis and communication, particularly when explaining complex structures to non-developer audiences.
The tradeoff for this scalability is limited insight into operational dynamics. CAST Imaging does not resolve data lineage at the field level, track batch execution flows, or quantify the runtime impact of changes. For initiatives that require precise scoping of change impact or validation of execution behavior, additional analysis tools are typically required.
Typical Enterprise Use Cases and Constraints
CAST Imaging is most effective in enterprises that need to understand and rationalize application architecture before undertaking significant change. It excels at revealing structural complexity, guiding architectural refactoring, and supporting modernization planning across heterogeneous systems.
Its limitations become evident when organizations require execution-level insight, impact assessment, or validation of how changes propagate through runtime behavior. CAST Imaging provides a structural map rather than an operational blueprint, and it is often complemented by tools that offer deeper analysis of execution paths, data flow, and system behavior.
Veracode Static Analysis
Veracode Static Analysis is a cloud-native static application security testing platform designed to embed security controls directly into modern software delivery processes. Its primary role in enterprise environments is to identify security vulnerabilities early and continuously across large volumes of application code, particularly in organizations that prioritize rapid release cycles, distributed development teams, and centralized security oversight. Veracode is commonly adopted where security assurance must scale without introducing friction into development velocity.
The platform emphasizes automation and consistency, positioning static analysis as an always-on security control rather than a periodic review activity. This operating model aligns with enterprises that have standardized on cloud-based development tooling and require centralized visibility into application security posture across diverse teams and projects.
Cloud-Native Static Application Security Testing
At the core of Veracode Static Analysis is a static security scanning engine delivered entirely as a managed cloud service. Source code and binaries are uploaded for analysis, where they are inspected for vulnerabilities such as injection flaws, insecure data handling, and authentication weaknesses. The analysis does not require access to production environments, allowing security assessments to be performed early in the lifecycle without operational risk.
This cloud-native approach enables rapid onboarding and elastic scaling across large portfolios. Enterprises can apply consistent security scanning policies across hundreds of applications without maintaining on-premises infrastructure. Findings are normalized and presented through centralized dashboards, supporting security teams responsible for enterprise-wide risk oversight.
Integration into Continuous Delivery Pipelines
Veracode is designed to integrate tightly with CI/CD pipelines and developer tooling. Scans can be triggered automatically during build or release stages, and results are returned in formats that integrate with issue tracking and remediation workflows. This supports a shift-left security model where vulnerabilities are addressed closer to the point of introduction.
In practice, Veracode’s role within pipelines is often coordinated with broader quality and testing controls, including activities such as performance regression testing, to ensure that security enforcement does not occur in isolation from other non-functional requirements. This alignment helps organizations balance security rigor with delivery performance.
Language Coverage and Portfolio Consistency
Veracode Static Analysis supports a wide range of modern programming languages and frameworks commonly used in enterprise application development. This breadth allows security teams to apply uniform scanning policies across heterogeneous development stacks, reducing gaps that might otherwise emerge between teams or platforms.
However, the platform’s focus remains on application-level security scanning. Analysis is typically scoped to individual applications or services, and relationships between applications, batch workflows, or shared data structures are not modeled. As a result, Veracode provides strong coverage of code-level vulnerabilities but limited insight into how those vulnerabilities might propagate across interconnected systems.
Risk Reporting and Governance Visibility
Veracode provides reporting capabilities that allow security leaders to track vulnerability trends, remediation progress, and policy compliance across the enterprise. Dashboards support portfolio-level views of risk exposure, enabling prioritization based on severity and business impact. These reports are often used to support internal security governance, executive reporting, and third-party assurance activities.
While these capabilities support accountability and oversight, the reporting focus remains vulnerability-centric. Veracode does not attempt to quantify operational impact, execution flow disruption, or modernization risk associated with remediation efforts. This distinction is important in environments where security changes must be evaluated alongside stability and change management considerations.
Typical Enterprise Use Cases and Constraints
Veracode Static Analysis is most effective in enterprises that operate at high delivery velocity and require scalable, centralized security scanning across modern application stacks. It excels at enforcing consistent security standards, reducing time-to-detection for vulnerabilities, and supporting DevSecOps operating models.
Its limitations become apparent in scenarios that require deep understanding of system behavior, cross-application dependencies, or legacy batch processing. Veracode does not provide execution-level insight or architectural dependency mapping, and it is typically positioned as a specialized security layer complemented by tools that focus on impact analysis, dependency visibility, and enterprise-scale system comprehension.
Coverity (Synopsys)
Coverity is an enterprise static code analysis platform recognized for its ability to detect complex defects in large, performance-critical codebases. Its primary role within enterprise environments is to identify deep correctness and reliability issues that are difficult to uncover through testing alone, particularly in systems where failure carries significant operational, safety, or financial consequences. Coverity is frequently adopted in industries such as automotive, aerospace, telecommunications, and infrastructure software, where defect precision and low false-positive rates are essential.
Unlike portfolio-level analysis platforms, Coverity focuses on code-level correctness across extensive codebases. It is designed to analyze large volumes of source code efficiently while maintaining a high level of analytical rigor, making it suitable for organizations managing long-lived systems with stringent reliability requirements.
Deep Defect Detection and Precision Analysis
At the core of Coverity is a static analysis engine optimized to detect defects such as memory corruption, resource leaks, concurrency issues, and logic errors. The engine is known for its ability to reason about complex control paths and execution scenarios that span multiple functions and modules. This depth of analysis enables it to identify defects that may only manifest under specific runtime conditions.
Coverity’s analytical approach incorporates advanced techniques related to symbolic execution, allowing it to explore multiple execution paths without running the code. This capability contributes to its reputation for high accuracy and helps reduce the noise often associated with large-scale static analysis in enterprise environments.
Language Focus and Targeted Coverage
Coverity provides strong support for languages commonly used in system-level and performance-sensitive software, including C, C++, and Java. This focus makes it particularly effective for analyzing core infrastructure components, embedded systems, and backend services where low-level defects can have outsized impact.
While the platform can scale across large codebases, its language coverage is narrower than some general-purpose static analysis tools. It is less oriented toward heterogeneous enterprise estates that include batch processing languages, scripting environments, or mainframe-specific technologies. As a result, Coverity is often deployed selectively within portfolios, targeting components where defect precision is most critical.
Integration into Enterprise Development Workflows
Coverity is designed to integrate into enterprise development processes, including CI/CD pipelines and centralized defect management systems. Scans can be scheduled or triggered automatically, and findings are routed to development teams for remediation. The platform supports incremental analysis, allowing teams to focus on newly introduced issues while maintaining visibility into existing defect backlogs.
In many organizations, Coverity is positioned as a quality assurance control rather than a continuous exploratory tool. Its scans are often run at defined milestones, such as before major releases or during formal quality reviews. This usage pattern reflects its role in enforcing reliability standards rather than supporting rapid iteration.
Scalability and Performance Characteristics
Coverity is engineered to handle very large codebases efficiently, making it suitable for enterprises with millions of lines of critical code. Its performance scales with available infrastructure, allowing organizations to analyze substantial systems without prohibitive analysis times. Centralized dashboards provide visibility into defect trends and remediation progress across projects.
However, Coverity’s scalability is focused on code volume rather than system complexity. It does not attempt to model cross-application dependencies, batch execution order, or data lineage across platforms. Its insights remain centered on defect detection within individual codebases rather than system-wide behavior.
Typical Enterprise Use Cases and Constraints
Coverity is most effective in enterprises that require high-confidence defect detection in critical software components. It excels at identifying subtle issues that could lead to crashes, security vulnerabilities, or unpredictable behavior in production, particularly in low-level or performance-sensitive code.
Its limitations become evident in modernization or transformation initiatives that require understanding how changes affect interconnected systems. Coverity does not provide architectural dependency mapping or execution-level impact analysis, and it is typically complemented by tools that focus on portfolio visibility, dependency analysis, and behavioral insight across heterogeneous enterprise environments.
Parasoft C/C++test and DTP
Parasoft C/C++test and the associated Development Testing Platform (DTP) form an enterprise-grade static analysis and compliance testing solution tailored for safety-critical and highly regulated software environments. Its primary role within large organizations is to support rigorous verification of system-level code where defects can lead to operational failure, regulatory non-compliance, or safety incidents. Parasoft is commonly adopted in industries such as aerospace, automotive, defense, and industrial systems, where software behavior must be provably correct and auditable.
Unlike general-purpose static analysis tools, Parasoft emphasizes conformance to defined standards and verification objectives. The platform is designed to support environments where development is governed by formal processes, certification requirements, and documented assurance cases rather than rapid iteration.
Standards-Driven Static Analysis and Compliance Enforcement
At the core of Parasoft C/C++test is a static analysis engine aligned with industry safety and coding standards such as MISRA, CERT, and ISO-related guidelines. The engine evaluates source code against strict rule sets that define acceptable constructs, usage patterns, and error conditions. Violations are categorized by severity and mapped directly to compliance requirements, enabling organizations to demonstrate adherence to mandated development practices.
This standards-driven approach aligns with environments that rely on formal verification concepts, where correctness is defined not only by functional behavior but also by compliance with prescribed rules. Parasoft’s analysis outputs can be used as evidence within certification and audit processes, reducing manual verification effort.
Focused Language Support and Targeted Analysis Depth
Parasoft C/C++test is specifically optimized for C and C++ codebases, providing deep analysis capabilities for languages commonly used in embedded and system-level software. This specialization allows the platform to identify low-level issues such as memory misuse, pointer errors, and concurrency defects that can be particularly dangerous in safety-critical contexts.
While this depth is valuable within its target domain, it also constrains the platform’s applicability across broader enterprise estates. Parasoft does not aim to provide wide coverage across diverse languages, batch processing environments, or legacy mainframe systems. As a result, it is typically deployed in targeted segments of an enterprise portfolio rather than as a universal analysis solution.
Integration with Regulated Development Lifecycles
Parasoft is designed to integrate into structured development lifecycles that emphasize traceability, documentation, and controlled change. Static analysis results can be linked to requirements, test cases, and defect tracking systems through the DTP component, enabling end-to-end traceability from specification to verification.
This integration supports development models where changes are introduced deliberately and reviewed formally. Analysis is often performed at defined milestones, such as before certification submissions or major releases, rather than continuously on every commit. This operating model reflects the priorities of regulated environments, where predictability and assurance outweigh speed.
Reporting, Traceability, and Audit Readiness
The Development Testing Platform provides centralized reporting and analytics across projects and teams. Metrics related to compliance status, defect trends, and verification coverage can be aggregated and reviewed by quality assurance and compliance stakeholders. Reports are structured to support audit and certification activities, providing documented evidence of analysis execution and results.
However, these reports focus on code-level compliance rather than system-wide behavior. Parasoft does not model execution paths across applications, batch orchestration, or cross-platform dependencies. Its traceability is oriented toward requirements and standards rather than runtime interaction between components.
Typical Enterprise Use Cases and Constraints
Parasoft C/C++test and DTP are most effective in enterprises where safety, reliability, and regulatory compliance are dominant concerns. They provide a disciplined framework for verifying that critical code conforms to strict standards and can withstand formal review.
Their limitations become apparent in environments that require holistic understanding of large, interconnected systems or support for heterogeneous technology stacks. Parasoft is not designed to provide portfolio-level visibility or execution-oriented impact analysis, and it is often complemented by tools that focus on architectural dependencies, modernization risk, and system behavior across complex enterprise landscapes.
Klocwork
Klocwork is an enterprise static code analysis platform focused on identifying security, reliability, and concurrency-related defects in large, complex codebases. Its primary role within enterprise environments is to detect issues that can compromise system stability or security, particularly in software that operates under high load, parallel execution, or constrained runtime conditions. Klocwork is commonly used in industries where performance and correctness are tightly coupled, including telecommunications, embedded systems, financial infrastructure, and large-scale backend services.
The platform emphasizes early defect detection through static analysis, enabling organizations to identify problematic patterns before they manifest as runtime failures. Klocwork is typically positioned as a quality and security assurance tool rather than a portfolio-wide analysis solution.
Concurrency and Reliability-Oriented Static Analysis
At the core of Klocwork is a static analysis engine designed to identify defects that arise from complex execution scenarios. This includes issues related to memory management, resource handling, and synchronization. The engine is particularly effective at detecting defects associated with parallel execution, where subtle interactions between threads can lead to unpredictable behavior.
Its ability to reason about concurrent code paths makes Klocwork relevant in environments where software must operate reliably under load. Analysis results often include findings related to deadlocks, race conditions, and improper synchronization constructs. These capabilities support organizations seeking to reduce instability caused by hard-to-reproduce concurrency defects such as race conditions.
Language Focus and Performance-Sensitive Domains
Klocwork provides strong support for languages commonly used in system-level and performance-critical software, including C, C++, and Java. This focus aligns with its adoption in domains where low-level correctness and runtime efficiency are critical. By concentrating on a narrower set of languages, the platform delivers deeper analysis for those environments compared to broader, more generalized tools.
However, this specialization also limits its applicability across heterogeneous enterprise estates. Klocwork is not designed to analyze batch-oriented workloads, mainframe languages, or high-level scripting environments that are common in long-lived enterprise systems. As a result, it is often deployed selectively rather than as a universal analysis solution.
Integration into Enterprise Quality and Security Workflows
Klocwork integrates with enterprise development workflows, including CI/CD pipelines and defect tracking systems. Scans can be automated and results routed to development teams for remediation. The platform supports incremental analysis, allowing teams to focus on newly introduced issues while maintaining visibility into existing defects.
In many organizations, Klocwork is used as part of formal quality assurance processes. Analysis may be triggered at key stages such as pre-release validation or major refactoring efforts. This usage pattern reflects its role in ensuring reliability and security rather than supporting continuous architectural exploration.
Scalability Characteristics and Operational Scope
Klocwork is engineered to scale across large codebases, enabling analysis of substantial systems without excessive performance overhead. Centralized dashboards provide visibility into defect trends and remediation progress across projects. These views support management oversight and help teams prioritize corrective actions based on severity and impact.
Despite its scalability in terms of code volume, Klocwork’s analytical scope remains localized to individual applications or components. It does not model cross-application dependencies, batch execution order, or data lineage across platforms. Its insights focus on code correctness rather than system-wide behavior.
Typical Enterprise Use Cases and Constraints
Klocwork is most effective in enterprises that require high-confidence detection of concurrency and reliability defects in performance-sensitive software. It excels at uncovering issues that are difficult to reproduce through testing and that can cause intermittent or catastrophic failures in production environments.
Its limitations become apparent in transformation initiatives that require holistic understanding of application portfolios, execution flows, or modernization impact. Klocwork does not provide architectural dependency mapping or execution-level impact analysis, and it is typically complemented by tools that focus on broader system comprehension and change risk assessment across heterogeneous enterprise environments.
OpenText DevOps Cloud Static Analysis
OpenText DevOps Cloud Static Analysis is an enterprise static analysis capability delivered as part of a broader DevOps and application lifecycle management suite. Its primary role within large organizations is to provide standardized code quality and security checks that align with established delivery governance models. Rather than operating as a standalone deep analysis platform, it is typically adopted by enterprises that prioritize toolchain consolidation and centralized oversight across development, testing, and release processes.
The platform is most commonly used in environments where software delivery must adhere to formal controls and where integration with existing ALM, testing, and release management tooling is a key requirement. Its value lies in consistency and governance alignment rather than in-depth behavioral or architectural analysis.
Suite-Oriented Static Analysis Capabilities
At its core, OpenText DevOps Cloud Static Analysis provides rule-based inspection of source code to identify quality issues and security weaknesses. Analysis focuses on common defect categories, coding standard violations, and vulnerability patterns that can be detected without executing the application. Results are normalized and presented through centralized dashboards alongside other DevOps metrics.
This suite-oriented approach supports organizations that want static analysis to function as one component of a larger delivery control framework. By embedding analysis into an integrated platform, enterprises can enforce baseline standards across teams without introducing additional point tools into already complex environments.
Integration with Enterprise Delivery Governance
OpenText’s static analysis capabilities are tightly integrated with broader lifecycle management functions such as requirements tracking, testing, and release orchestration. This integration allows analysis results to be linked to work items, defects, and approvals, supporting traceability across the delivery process. For organizations with formal governance models, this alignment simplifies oversight and reporting.
The platform is often positioned to support structured change management processes, where software modifications must pass through defined review and approval stages. Static analysis findings become part of the evidence used to assess readiness for release rather than a standalone source of technical insight.
Language Coverage and Standardization Focus
OpenText DevOps Cloud Static Analysis supports a range of commonly used enterprise programming languages, enabling consistent enforcement of coding standards across diverse development teams. Its language support is oriented toward mainstream application development stacks rather than niche or legacy environments.
While this breadth supports standardization, the analysis depth remains relatively shallow compared to specialized tools. The platform does not attempt to model execution paths, resolve batch orchestration logic, or analyze cross-application dependencies. Its findings are best suited for identifying localized issues within individual codebases.
Scalability and Operational Characteristics
Designed to operate as part of a cloud-delivered suite, OpenText DevOps Cloud Static Analysis scales across multiple projects and teams with centralized administration. This makes it suitable for enterprises seeking uniform controls across large developer populations. Performance scales with cloud infrastructure, reducing the need for dedicated on-premises resources.
However, scalability in this context refers to organizational coverage rather than analytical depth. The platform provides broad visibility across projects but limited insight into how systems behave at runtime or how changes propagate through complex, interconnected environments.
Typical Enterprise Use Cases and Constraints
OpenText DevOps Cloud Static Analysis is most effective in enterprises that value integrated delivery governance and standardized controls over deep technical exploration. It supports environments where static analysis is one checkpoint among many within a controlled release process, providing consistent enforcement of baseline quality and security requirements.
Its limitations become evident in scenarios that require detailed understanding of execution behavior, dependency chains, or modernization impact across heterogeneous systems. The platform does not provide the behavioral visibility or impact assessment needed to safely execute large-scale refactoring or modernization initiatives, and it is often complemented by tools that specialize in execution insight and cross-platform analysis.
SCA Solutions Capability-Based Comparison Table
| Capability | SMART TS XL | SonarQube Ent | Checkmarx One | Fortify SCA | CAST Highlight | CAST Imaging | Veracode | Coverity | Parasoft | Klocwork | OpenText |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Enterprise portfolio scale | ✅ Excellent | ◐ Moderate | ◐ Moderate | ◐ Moderate | ✅ Excellent | ✅ Excellent | ◐ Moderate | ◐ Moderate | ◐ Moderate | ◐ Moderate | ◐ Moderate |
| Multi-platform (Mainframe + Distributed) | ✅ Full | ❌ No | ❌ No | ❌ Limited | ❌ Limited | ❌ Limited | ❌ No | ❌ No | ❌ No | ❌ No | ❌ Limited |
| Legacy language support (COBOL, JCL, RPG) | ✅ Full | ❌ No | ❌ No | ❌ Limited | ❌ Limited | ❌ Limited | ❌ No | ❌ No | ❌ No | ❌ No | ❌ No |
| Cross-system dependency analysis | ✅ Full | ❌ No | ❌ No | ❌ No | ◐ High-level | ◐ Structural | ❌ No | ❌ No | ❌ No | ❌ No | ❌ No |
| Execution path visibility (static) | ✅ Full | ❌ No | ❌ No | ❌ No | ❌ No | ❌ No | ❌ No | ◐ Partial | ◐ Partial | ◐ Partial | ❌ No |
| Batch and job flow analysis | ✅ Full | ❌ No | ❌ No | ❌ No | ❌ No | ❌ No | ❌ No | ❌ No | ❌ No | ❌ No | ❌ No |
| Impact analysis before change | ✅ Deep | ◐ Shallow | ◐ Security-only | ◐ Security-only | ◐ Portfolio | ◐ Structural | ◐ Security-only | ◐ Code-level | ◐ Code-level | ◐ Code-level | ◐ Governance |
| Security vulnerability detection (SAST) | ◐ Contextual | ◐ Basic | ✅ Strong | ✅ Strong | ◐ Indicative | ❌ No | ✅ Strong | ◐ Limited | ◐ Limited | ◐ Limited | ◐ Basic |
| Performance and complexity insight | ✅ Deep | ◐ Metrics | ❌ No | ❌ No | ◐ Aggregate | ◐ Structural | ❌ No | ◐ Defect-based | ◐ Compliance | ◐ Defect-based | ❌ No |
| Modernization readiness analysis | ✅ Native | ❌ No | ❌ No | ❌ No | ✅ Primary | ◐ Structural | ❌ No | ❌ No | ❌ No | ❌ No | ❌ No |
| Search across all assets | ✅ Advanced | ◐ Repo-only | ◐ Repo-only | ◐ Repo-only | ◐ Metadata | ◐ Metadata | ◐ Repo-only | ◐ Repo-only | ◐ Repo-only | ◐ Repo-only | ◐ Repo-only |
| CI/CD integration | ◐ Optional | ✅ Strong | ✅ Strong | ◐ Moderate | ❌ No | ❌ No | ✅ Strong | ◐ Moderate | ◐ Moderate | ◐ Moderate | ✅ Native |
| Audit-ready evidence generation | ✅ Native | ◐ Limited | ◐ Limited | ✅ Strong | ◐ Aggregate | ◐ Structural | ◐ Limited | ◐ Limited | ✅ Strong | ◐ Limited | ◐ Strong |
Other Static Code Analysis Tools (Limited Enterprise Applicability)
- ESLint
- Advantages: Enforces coding standards in JavaScript and TypeScript with fast developer feedback.
- Limitations: Operates at repository level with no cross-system or enterprise impact visibility.
- PMD
- Advantages: Detects common code quality issues across several programming languages.
- Limitations: Rule-based analysis unsuitable for large, heterogeneous enterprise estates.
- Flake8
- Advantages: Lightweight static analysis for Python syntax and style enforcement.
- Limitations: Does not provide architectural or execution-level insight.
- Bandit
- Advantages: Identifies security issues in Python code using pattern-based analysis.
- Limitations: Narrow scope and no awareness of enterprise system interactions.
- CodeQL
- Advantages: Query-based analysis capable of identifying complex vulnerability patterns.
- Limitations: Requires specialized expertise and lacks enterprise execution modeling.
- Semgrep
- Advantages: Fast, customizable pattern matching for security and quality checks.
- Limitations: Pattern-driven approach lacks dependency and behavioral context.
- Snyk Code
- Advantages: Developer-friendly static analysis integrated into cloud-native workflows.
- Limitations: Focused on application-level security rather than enterprise architecture.
- Pylint
- Advantages: Provides detailed code quality checks for Python projects.
- Limitations: Not designed for cross-project or multi-platform analysis.
- Cppcheck
- Advantages: Open-source static analysis for C and C++ with low false-positive rates.
- Limitations: Limited scalability and enterprise governance support.
- Infer
- Advantages: Detects memory and concurrency issues using advanced analysis techniques.
- Limitations: Narrow language support and limited enterprise integration.
- LGTM
- Advantages: Combines static analysis with cloud-based code review workflows.
- Limitations: Repository-centric with limited system-level insight.
- FxCop Analyzers
- Advantages: Enforces design and coding guidelines for .NET applications.
- Limitations: Does not address cross-application dependencies.
- PHPCS
- Advantages: Enforces coding standards in PHP projects.
- Limitations: Style-focused with minimal analytical depth.
- SpotBugs
- Advantages: Identifies common bug patterns in Java bytecode.
- Limitations: Pattern-based detection without execution path modeling.
- Brakeman
- Advantages: Specialized security scanning for Ruby on Rails applications.
- Limitations: Framework-specific and unsuitable for enterprise-wide analysis.
- ReSharper Command Line Tools
- Advantages: Integrates static analysis into .NET build pipelines.
- Limitations: Developer productivity focus rather than enterprise insight.
- DeepSource
- Advantages: Automated code review and quality analysis for modern repositories.
- Limitations: SaaS-centric with limited structural analysis depth.
- Codacy
- Advantages: Centralized quality reporting across multiple repositories.
- Limitations: Aggregation-focused without deep system understanding.
- Sonatype Lift
- Advantages: Security and quality scanning integrated into DevOps workflows.
- Limitations: Limited visibility into runtime behavior and legacy systems.
- NDepend
- Advantages: Provides dependency analysis for .NET applications.
- Limitations: Technology-specific and not suited for heterogeneous estates.
- Coverity Scan (Open Source)
- Advantages: Free static analysis for selected open-source projects.
- Limitations: Not representative of enterprise deployment scenarios.
- OWASP Dependency-Check
- Advantages: Identifies known vulnerable dependencies.
- Limitations: Does not analyze source code behavior or architecture.
- Rust Clippy
- Advantages: Lints Rust code for idiomatic issues and common mistakes.
- Limitations: Language-specific with no enterprise context.
- GolangCI-Lint
- Advantages: Aggregates multiple linters for Go projects.
- Limitations: Developer-centric with no portfolio-level insight.
- SwiftLint
- Advantages: Enforces Swift coding conventions in mobile projects.
- Limitations: Narrow scope and limited relevance for enterprise systems.
Across the comparison, a clear distinction emerges between tools designed to enforce localized quality or security controls and platforms capable of supporting enterprise-wide understanding. Many solutions excel within narrowly defined scopes, such as developer feedback, vulnerability detection, or architectural visualization, yet remain constrained when applied to heterogeneous estates composed of legacy platforms, batch workloads, and tightly coupled systems. In these environments, the limiting factor is not the absence of analysis, but the fragmentation of insight across disconnected tools.
Enterprise-scale modernization, risk management, and compliance initiatives increasingly require analysis that spans languages, platforms, and execution models without sacrificing depth or performance. Tools that operate primarily at repository or application boundaries struggle to provide sufficient context for change decisions that affect downstream systems, shared data, or operational stability. As a result, enterprises often find themselves combining multiple tools to approximate a complete view, introducing additional complexity and coordination overhead.
The comparison highlights that the most decisive differentiator in 2026 is not the ability to detect individual defects or enforce coding standards, but the capacity to expose how systems behave as interconnected wholes. Static analysis that remains confined to isolated artifacts delivers diminishing value as architectural complexity grows. Platforms that unify discovery, dependency analysis, and impact assessment across entire portfolios provide a more durable foundation for decision-making in large, mission-critical environments.
How Enterprise Static Code Analysis Tools Are Evaluated
Enterprise static code analysis tools are evaluated against a fundamentally different set of criteria than those used for developer-centric or security-only tooling. In large organizations, the primary challenge is rarely the absence of analysis, but rather the fragmentation of insight across disconnected tools, teams, and platforms. Evaluation therefore focuses on whether a tool can operate as a unifying analytical layer across heterogeneous environments rather than as a localized inspection mechanism.
As software estates grow older and more interconnected, evaluation must also account for the operational consequences of change. Static analysis findings that cannot be translated into actionable understanding of execution behavior, dependency scope, or downstream impact provide limited value in environments where outages, compliance violations, or performance regressions carry material risk. The following evaluation dimensions reflect how enterprises assess static code analysis tools in 2026 when architectural complexity and modernization pressure intersect.
Analysis Depth Versus Surface-Level Detection
One of the most critical evaluation dimensions is the depth at which a static code analysis tool can reason about software behavior. Surface-level detection focuses on identifying localized issues such as syntax violations, rule breaches, or known vulnerability patterns. While these findings are useful within controlled development workflows, they provide limited insight into how changes affect complex systems composed of many interacting components.
Deep analysis, by contrast, examines how control flow, data propagation, and dependency relationships evolve across an application or portfolio. This includes understanding how a variable is populated, transformed, and consumed across multiple execution contexts, or how a seemingly isolated change in one module influences batch jobs, downstream services, or reporting layers. Tools capable of this level of reasoning move beyond file-level inspection and toward system-level comprehension.
Enterprises increasingly prioritize depth because modernization initiatives often involve modifying legacy logic without full documentation or institutional knowledge. In such cases, shallow findings create a false sense of confidence, encouraging changes that appear safe locally but introduce instability elsewhere. Deep analysis reduces this risk by exposing hidden couplings and indirect dependencies before execution.
Depth also affects how analysis results are consumed. Shallow tools typically generate large volumes of findings that require manual triage, whereas deeper tools can contextualize findings within execution paths or impact zones. This distinction influences productivity and trust. When teams repeatedly encounter false positives or irrelevant alerts, confidence in analysis erodes. Evaluation therefore considers not just what a tool detects, but how meaningfully those detections map to real system behavior.
This distinction is particularly relevant in environments where performance characteristics matter as much as correctness. Understanding why latency emerges or where resource contention originates often requires insight into execution structure rather than isolated defects. Tools that support reasoning across control flow and dependency chains provide a stronger foundation for performance engineering efforts such as those described in software performance metrics tracking.
Scalability Across Enterprise Portfolios
Scalability in enterprise static code analysis is not limited to processing large volumes of source code. It also encompasses the ability to analyze, query, and visualize relationships across thousands of applications, multiple platforms, and decades of accumulated logic without degrading responsiveness or usability. Evaluation therefore considers both computational scalability and cognitive scalability.
From a computational perspective, enterprises require tools that can ingest millions or billions of lines of code and associated artifacts within reasonable timeframes. This includes not only source files, but also job control definitions, database schemas, configuration files, and supporting documentation. Tools that require prolonged indexing cycles or frequent reprocessing struggle to keep pace with continuous change, reducing their practical value.
Cognitive scalability is equally important. As portfolios grow, the challenge shifts from finding information to making sense of it. Evaluation examines whether a tool can present analysis results in ways that scale with complexity, such as interactive dependency maps, filtered impact views, or layered abstractions. Static reports or flat lists become increasingly unusable as system size increases.
Another aspect of scalability involves user concurrency. Enterprise analysis platforms are often accessed by developers, architects, auditors, and operations teams simultaneously. Tools designed primarily for individual developers may not support shared, real-time access to analysis results. Evaluation therefore includes how well a tool supports collaborative usage without creating contention or performance bottlenecks.
Scalability also intersects with cost models. Tools that require heavy reliance on production environments or specialized infrastructure can introduce hidden operational costs. Enterprises often evaluate whether analysis workloads can be offloaded to cost-effective platforms without sacrificing accuracy or timeliness. This consideration becomes especially relevant in large-scale environments where analysis is performed continuously rather than periodically.
Ultimately, scalability is evaluated in terms of sustained usability under enterprise conditions rather than peak throughput alone. A tool that performs well on isolated projects but degrades as portfolio scope expands fails to meet enterprise requirements.
Dependency Visibility and Impact Awareness
Dependency visibility is a defining criterion for enterprise static code analysis because it directly influences the ability to manage change safely. In complex systems, dependencies rarely align with organizational boundaries or architectural diagrams. They emerge organically over time through shared data structures, reused logic, and implicit execution ordering. Evaluation therefore focuses on whether a tool can surface these relationships accurately and comprehensively.
Effective dependency visibility requires more than identifying direct call relationships. It involves tracing indirect dependencies across layers, platforms, and execution contexts. For example, a database field modified in one application may affect reporting jobs, regulatory extracts, or downstream analytics pipelines. Tools that only model direct code references miss these secondary and tertiary effects.
Impact awareness builds on dependency visibility by translating relationships into actionable scopes. Evaluation considers whether a tool can answer questions such as which components are affected by a proposed change, which execution paths are exercised, and which operational processes rely on the modified logic. This capability is critical for change planning, testing scoping, and risk assessment.
Enterprises also assess how dependency information is presented. Visual representations such as graphs or flow diagrams can make complex relationships comprehensible, but only if they support filtering, drill-down, and context preservation. Static or overly dense diagrams often obscure more than they reveal. Tools are therefore evaluated on their ability to support progressive exploration rather than overwhelming users with undifferentiated detail.
Dependency analysis also supports broader governance objectives. When combined with audit trails and historical context, it enables teams to understand how systems evolved and why certain couplings exist. This perspective is essential for managing technical debt and avoiding repeated mistakes. Concepts such as those discussed in software management complexity analysis highlight how unmanaged dependencies contribute to rising maintenance costs and operational fragility.
Translation of Findings Into Decision Support
A recurring weakness of many static code analysis tools is their inability to translate technical findings into forms that support enterprise decision-making. Evaluation therefore emphasizes whether analysis results can be consumed not only by developers, but also by architects, risk owners, and leadership stakeholders responsible for prioritization and investment decisions.
Decision support requires contextualization. A list of issues without information about scope, impact, or execution relevance provides limited value outside development teams. Enterprises evaluate whether tools can aggregate findings into meaningful units such as impacted business processes, affected applications, or risk categories aligned with governance frameworks.
Another aspect of decision support is traceability. Enterprises often need to demonstrate why a particular change was approved, deferred, or rejected. Tools that provide traceable links between analysis findings, impacted components, and remediation actions support defensible decision-making. This is particularly important in regulated environments where auditability is a requirement rather than an afterthought.
Evaluation also considers how tools support trade-off analysis. Modernization decisions often involve balancing risk reduction against delivery timelines and resource constraints. Static analysis that exposes structural risk, dependency density, or execution complexity allows these trade-offs to be assessed explicitly rather than intuitively. Tools that surface such insights contribute directly to strategic planning.
Finally, decision support is evaluated in terms of longevity. Enterprises favor tools that retain historical analysis results and support longitudinal comparison. Understanding whether complexity is increasing, dependencies are tightening, or risk exposure is shifting over time informs continuous improvement initiatives. This longitudinal perspective aligns static analysis with broader modernization and transformation efforts described in enterprise application modernization strategies.
Static Code Analysis vs Code Scanning Tools in Enterprise Environments
In enterprise contexts, the terms static code analysis and code scanning tools are often used interchangeably, yet they describe fundamentally different analytical approaches with distinct strengths and limitations. This ambiguity becomes problematic as organizations attempt to standardize tooling across development, security, and modernization initiatives. Evaluation errors frequently stem from assuming that tools designed for one purpose can fulfill the requirements of another at enterprise scale.
The distinction matters because enterprise software systems operate under constraints that extend beyond code correctness or vulnerability detection. Legacy platforms, batch processing, shared data structures, and regulatory oversight introduce dependencies that are invisible to tools optimized for repository-level scanning. Understanding where static code analysis ends and code scanning begins is therefore essential for selecting tools that align with architectural reality rather than surface-level needs.
Conceptual Differences Between Analysis and Scanning
Static code analysis and code scanning tools differ primarily in how they interpret and reason about source artifacts. Code scanning tools are typically designed to detect known patterns such as insecure constructs, deprecated APIs, or violations of predefined rulesets. Their strength lies in breadth and speed. They can be applied quickly across many repositories to identify common issues with minimal configuration.
Static code analysis, in the enterprise sense, focuses on structural and behavioral understanding rather than pattern detection alone. It attempts to model how code elements interact, how control flows through a system, and how data propagates across execution contexts. This distinction is not merely academic. It determines whether a tool can answer questions about impact, risk scope, and system behavior rather than simply listing findings.
In practice, scanning tools treat source code as a collection of files or modules to be inspected independently. Analysis tools treat code as a connected system whose behavior emerges from interactions between components. This difference affects the kinds of insights each approach can provide. A scanner may flag a potentially unsafe function call, but it cannot determine whether that call is reachable, under what conditions it executes, or what downstream processes depend on it.
Enterprise environments amplify this gap. As systems evolve over decades, undocumented dependencies accumulate and execution paths become increasingly opaque. Pattern-based scanning identifies issues that match known signatures but cannot reveal how those issues interact with legacy logic or batch workflows. Static analysis that builds control and data flow models is better suited to these conditions, although it is more complex to implement and operate.
This conceptual distinction is explored further in discussions around static code analysis fundamentals, which emphasize that analysis depth determines whether findings can be operationalized. Enterprises therefore evaluate tools not only on detection capability, but on their ability to represent system behavior in a way that supports decision-making.
Why Code Scanning Tools Fall Short at Scale
Code scanning tools perform well in environments where applications are loosely coupled, documentation is current, and changes are localized. These conditions are common in greenfield or cloud-native development, where microservices are independently deployable and ownership boundaries are clear. In such settings, scanning provides fast feedback and supports continuous integration practices.
At enterprise scale, however, these assumptions rarely hold. Applications often share databases, messaging infrastructure, and batch schedules. Changes introduced in one area may affect others indirectly through shared resources or implicit execution ordering. Scanning tools, which lack awareness of these relationships, struggle to provide reliable guidance on impact and risk.
Another limitation emerges in the handling of false positives and false negatives. Scanners rely on generalized rules that must apply across many contexts. In heterogeneous environments, this leads to findings that are either irrelevant or incomplete. Teams spend significant time triaging alerts without gaining clearer understanding of system behavior. Over time, this erodes trust in the tool and reduces adoption.
Scalability also becomes an issue. While scanners can process many repositories quickly, they often do so independently. Aggregating results across hundreds of applications does not automatically produce insight into how those applications interact. Enterprises are left with fragmented views that must be reconciled manually. This fragmentation increases cognitive load and introduces opportunities for error.
These shortcomings are particularly evident when scanning tools are applied to modernization initiatives. Modernization requires understanding how legacy logic supports business processes and how proposed changes will propagate through dependent systems. Scanners provide snapshots of issues but do not reveal execution structure. This gap is highlighted in resources such as the complete code scanning overview, which note that scanning is necessary but insufficient for complex transformation efforts.
As a result, enterprises often supplement scanning tools with deeper analysis platforms. The combination addresses immediate security and quality concerns while enabling structural understanding. Evaluation therefore considers whether a tool can evolve beyond scanning to support broader analytical needs or whether it must be paired with additional capabilities.
Where Static Analysis Provides Enterprise Leverage
Static code analysis delivers its greatest value in enterprise environments by enabling informed change rather than reactive remediation. By constructing models of control flow, data lineage, and dependency structure, analysis tools allow organizations to reason about the consequences of change before execution. This capability directly addresses the uncertainty that characterizes large, interconnected systems.
One area where this leverage is evident is impact analysis. When a proposed change is evaluated, static analysis can identify all affected components, execution paths, and data consumers. This information supports targeted testing and reduces unnecessary regression effort. It also enables more accurate risk assessment by highlighting areas where change intersects with critical business functions.
Static analysis also supports architectural governance. By revealing how systems have evolved, it helps organizations identify deviations from intended design and areas of excessive coupling. This insight informs refactoring strategies and modernization roadmaps. Rather than treating technical debt as an abstract concept, analysis makes it visible and measurable within specific contexts.
Another advantage lies in cross-functional communication. Analysis results can be presented in forms that are accessible to non-developers, such as dependency diagrams or impact summaries. This shared understanding reduces friction between development, operations, and governance teams. Decisions become grounded in evidence rather than assumptions or incomplete documentation.
These benefits align with enterprise needs for consistency and transparency. As discussed in enterprise code analysis practices, organizations increasingly expect analysis tools to serve as knowledge repositories that persist beyond individual projects. Static analysis that captures system structure and behavior contributes to institutional memory and reduces reliance on tacit knowledge.
Ultimately, the distinction between static analysis and scanning shapes tool selection strategy. Enterprises that rely solely on scanning tools may address immediate issues but remain exposed to systemic risk. Those that invest in deeper analysis gain leverage over complexity, enabling safer change and more predictable outcomes as systems continue to evolve.
Static Code Analysis for Legacy and Hybrid Enterprise Systems
Legacy and hybrid enterprise systems present analytical challenges that differ fundamentally from those found in homogeneous, cloud-native environments. These systems are rarely the result of a single architectural vision. Instead, they evolve incrementally over decades as new technologies are layered onto existing platforms, often without retiring older components. Static code analysis in this context must accommodate not only multiple programming languages, but also differing execution models, data representations, and operational assumptions.
Hybrid environments further complicate analysis by introducing interaction points between legacy platforms and modern distributed services. Mainframe batch jobs feed data into downstream analytics pipelines. Online transactions interface with APIs that did not exist when the original applications were designed. Evaluation of static analysis tools therefore considers whether they can operate across these boundaries and provide a coherent view of how systems function as integrated wholes rather than isolated silos.
Multi-Platform Coexistence and Cross-System Understanding
A defining characteristic of legacy enterprise environments is the coexistence of multiple platforms that were never designed to operate together. Mainframe systems, midrange platforms, and distributed environments often share data and responsibilities through mechanisms that are implicit rather than formally documented. Static code analysis must therefore bridge these platforms to provide meaningful insight.
In practice, this requires the ability to analyze not only application code, but also job control definitions, interface contracts, and shared data structures. For example, a batch job written decades ago may populate files or tables that are later consumed by modern services. Without understanding this relationship, changes introduced in one environment can have unintended consequences in another. Static analysis that remains confined to a single platform fails to capture this risk.
Cross-system understanding also extends to execution timing and sequencing. Legacy batch processing often operates on schedules that assume specific data states at specific times. Hybrid systems introduce additional variability as distributed services may consume data asynchronously. Static analysis tools evaluated for enterprise use must be able to trace these relationships and expose assumptions embedded in code and scheduling logic.
The challenge is compounded by the lack of consistent documentation. Institutional knowledge may reside with a shrinking number of subject matter experts. Static analysis that can reconstruct system relationships directly from source artifacts becomes a surrogate for lost documentation. This capability supports safer change and reduces dependence on manual walkthroughs.
These considerations are central to discussions around legacy modernization approaches, which emphasize that understanding existing behavior is a prerequisite for transformation. Tools that cannot operate across platforms or reconcile differing execution models provide limited value in hybrid enterprise contexts.
Handling Long-Lived Code and Structural Drift
Legacy systems often exhibit structural drift, where the implemented architecture diverges significantly from any original design intent. Over time, expedient changes accumulate, introducing tightly coupled logic, duplicated functionality, and implicit dependencies. Static code analysis in such environments must contend with complexity that is not accidental, but the result of sustained operational pressure.
Long-lived codebases frequently rely on shared copybooks, common data definitions, and reused utility programs. Changes to these shared elements can propagate widely, yet the extent of that propagation is often unclear. Static analysis tools are evaluated on their ability to identify these shared structures and trace their usage across applications and platforms.
Structural drift also manifests in control flow complexity. Deeply nested conditionals, exception handling paths, and conditional execution based on runtime parameters obscure the true behavior of the system. Analysis that focuses solely on individual modules cannot reveal how these constructs interact across execution paths. Enterprise-grade analysis must reconstruct control flow at a level that reflects actual runtime behavior.
Another dimension of long-lived systems is the presence of obsolete or partially unused code. Over time, business rules change, but old logic may remain embedded in systems because its removal is perceived as risky. Static analysis can help identify unreachable or redundant code, but only if it can reason about execution conditions and dependencies accurately.
Managing this complexity is closely tied to understanding how shared artifacts evolve. Issues such as copybook changes and downstream impact are discussed in resources like copybook evolution management. Tools that surface these relationships enable more confident refactoring and reduce the risk associated with modifying foundational elements.
Supporting Incremental Modernization Without Disruption
Enterprise modernization rarely occurs as a single, sweeping transformation. Constraints related to availability, regulatory compliance, and business continuity favor incremental approaches that introduce change gradually. Static code analysis plays a critical role in enabling this strategy by reducing uncertainty at each step.
Incremental modernization requires precise scoping of change. Teams must know exactly which components are affected, which interfaces are involved, and which operational processes depend on the modified logic. Static analysis tools are evaluated on their ability to provide this precision without requiring full system rewrites or invasive instrumentation.
Hybrid systems often serve as transitional architectures during modernization. Legacy components continue to operate alongside newly introduced services. Static analysis must therefore support both worlds simultaneously, enabling teams to reason about interactions between old and new components. This includes understanding data transformations, interface contracts, and execution dependencies that span platforms.
Another consideration is risk containment. Incremental change aims to limit blast radius by isolating modifications. Static analysis that can identify dependency boundaries and coupling intensity helps teams choose refactoring entry points that minimize disruption. This capability supports strategies such as strangler patterns and phased replacement without compromising stability.
The importance of this approach is emphasized in discussions around incremental modernization strategies, which highlight the need for continuous insight into system structure. Tools that provide only high-level assessments or localized findings cannot support the level of control required for incremental change.
Ultimately, static code analysis for legacy and hybrid systems is evaluated on its ability to enable progress without destabilization. Enterprises favor tools that illuminate existing behavior, reveal hidden dependencies, and support disciplined, stepwise transformation over those that assume clean architectural boundaries that rarely exist in practice.
Security, Compliance, and Risk Detection with SAST Tools
Security and compliance considerations increasingly shape how enterprises evaluate static analysis tooling, yet these considerations are often misunderstood when viewed in isolation. In large organizations, security risk is rarely confined to a single vulnerability or code fragment. Instead, it emerges from how vulnerabilities intersect with execution paths, data exposure, operational controls, and regulatory obligations. Static application security testing tools therefore operate within a broader risk landscape rather than as standalone solutions.
As regulatory pressure intensifies and audit expectations grow more stringent, enterprises must demonstrate not only that vulnerabilities can be detected, but also that risks are understood, prioritized, and managed in context. Static analysis plays a role in this process, but its effectiveness depends on how well security findings can be integrated into enterprise risk models, compliance workflows, and change governance structures.
Vulnerability Detection Versus Systemic Risk Awareness
Static application security testing tools are primarily designed to identify vulnerability patterns within source code. These patterns often map to well-known categories such as injection risks, improper authentication handling, or insecure data usage. Detection of such issues is essential, particularly in environments where applications are exposed to external interfaces or handle sensitive data.
However, vulnerability detection alone does not equate to systemic risk awareness. In enterprise environments, the impact of a vulnerability depends on whether it is reachable, under what conditions it executes, and which systems or data it affects. A vulnerability buried in rarely executed logic may pose less operational risk than a moderate issue embedded in a critical batch process or transaction path. Static analysis tools that do not model execution context struggle to make this distinction.
This limitation becomes evident during remediation prioritization. Security teams may be presented with large volumes of findings without clear guidance on which issues represent material risk. Development teams, in turn, face competing priorities and limited capacity. Without contextual insight, remediation efforts may focus on issues that are visible rather than those that are consequential.
Enterprises increasingly evaluate whether static analysis tools can contribute to risk-based prioritization. This includes the ability to correlate vulnerabilities with execution paths, data sensitivity, and business criticality. Tools that provide only pattern-based detection require additional manual analysis to assess impact, increasing cost and delaying response.
The distinction between detection and awareness is particularly important in regulated sectors. Regulations often require demonstration that risks are identified and managed proportionally. Simply listing vulnerabilities does not satisfy this requirement. The need for contextual security insight is explored in discussions such as cybersecurity vulnerability management tools, which emphasize that effective risk management depends on understanding exposure rather than raw counts.
Compliance Evidence and Audit Readiness
Compliance obligations introduce another dimension to the evaluation of SAST tools. Enterprises subject to financial, privacy, or operational regulations must provide evidence that controls are in place and functioning as intended. Static analysis contributes to this evidence by demonstrating that code is reviewed for security weaknesses, but the quality and usability of that evidence vary widely across tools.
Audit readiness requires traceability. Auditors typically expect to see not only that scans were performed, but also what was scanned, what was found, how findings were addressed, and how decisions were documented. Tools that generate opaque reports or lack historical context make it difficult to reconstruct this narrative after the fact.
Enterprises therefore evaluate whether static analysis outputs can be preserved, versioned, and linked to change records. This includes the ability to show how security posture evolved over time and how specific findings influenced remediation decisions. Tools that support exportable, timestamped reports align more closely with audit expectations than those that present ephemeral dashboards.
Compliance also intersects with change management. Security findings often influence whether changes are approved, deferred, or rejected. Static analysis tools that integrate with governance workflows support this process by embedding security insight into decision points. Conversely, tools that operate outside formal change processes risk being sidelined or ignored.
Regulatory frameworks increasingly emphasize continuous control monitoring rather than periodic assessments. Static analysis that can be run consistently and produce comparable results over time supports this shift. Discussions around SOX and DORA compliance analysis highlight the importance of linking technical analysis to regulatory control objectives.
Limitations of Security-Only Static Analysis
While SAST tools play a critical role in identifying vulnerabilities, their scope is inherently limited when applied to broader enterprise risk management. Security-only analysis treats code as an isolated artifact rather than as part of an operational system. This perspective is sufficient for identifying certain classes of issues but insufficient for understanding how security risk manifests in real-world execution.
One limitation is the inability to assess blast radius. When a vulnerability is identified, enterprises need to know which processes, users, or downstream systems are affected. SAST tools typically cannot answer these questions without integration with additional analysis capabilities. As a result, risk assessment becomes fragmented and dependent on manual expertise.
Another limitation involves false confidence. Organizations may assume that comprehensive scanning equates to comprehensive security. In reality, vulnerabilities that arise from architectural assumptions, data flows, or operational dependencies may remain undetected. Overreliance on security-only analysis can therefore obscure systemic weaknesses.
This gap is particularly pronounced in environments with legacy components. Older systems may not conform to modern coding standards, yet they often underpin critical business functions. Security analysis that flags numerous issues without context can overwhelm teams and lead to risk acceptance decisions that are not fully informed.
Enterprises increasingly recognize that security analysis must be integrated with broader system understanding. This includes knowledge of data lineage, execution sequencing, and dependency structure. While SAST tools contribute valuable input, they are most effective when complemented by analysis that exposes how systems behave as wholes.
The evolving relationship between security tooling and broader risk management is discussed in resources such as enterprise risk management strategies, which emphasize that technical controls must be contextualized within operational reality. Static analysis that remains security-centric without systemic insight addresses symptoms rather than underlying risk.
CI/CD Integration and Automation at Enterprise Scale
CI/CD integration is often presented as a straightforward extension of static code analysis, yet at enterprise scale it introduces constraints that fundamentally change how automation can be applied. In large organizations, delivery pipelines must accommodate not only frequent code changes, but also legacy release cycles, regulatory approvals, and shared infrastructure dependencies. Static analysis tools are therefore evaluated not just on whether they integrate with CI/CD systems, but on how they behave when automation intersects with organizational complexity.
Automation at scale also exposes tradeoffs between speed and control. While development teams seek rapid feedback, enterprises must ensure that automated analysis does not disrupt production stability or overwhelm governance processes. Evaluation of static analysis tooling increasingly focuses on whether CI/CD integration enhances decision-making without introducing new forms of operational risk or process bottlenecks.
Pipeline Integration Beyond Individual Repositories
At a basic level, CI/CD integration allows static analysis to run automatically during build or deployment stages. This capability is well understood and widely implemented. However, in enterprise environments, pipelines often span multiple repositories, shared libraries, and downstream systems. Static analysis tools must therefore integrate in ways that reflect these interdependencies rather than treating each repository as an isolated unit.
Enterprises evaluate whether analysis results can be aggregated across pipelines to provide a coherent view of change impact. When multiple services or components are released together, isolated findings lose relevance unless they can be correlated. Tools that integrate only at the repository level often fail to provide insight into how concurrent changes interact across the system.
Another consideration is pipeline heterogeneity. Large organizations rarely standardize on a single CI/CD platform. Different teams may use different tooling based on historical or functional requirements. Static analysis solutions must therefore support integration across diverse environments without requiring extensive customization or duplication of effort.
Pipeline integration also affects traceability. Enterprises need to understand which analysis results correspond to which builds, releases, or change requests. This linkage supports accountability and post-incident investigation. Tools that integrate deeply with pipeline metadata provide stronger support for governance than those that operate as detached scanners.
The complexity of pipeline integration is discussed in contexts such as performance regression pipeline strategies, which highlight how automation must account for cumulative effects across stages. Static analysis that aligns with this perspective supports more reliable delivery outcomes.
Automation Constraints in Regulated Environments
Regulated environments impose constraints that fundamentally shape how CI/CD automation is applied. Financial institutions, healthcare providers, and critical infrastructure operators must adhere to change control, segregation of duties, and audit requirements. Static analysis tools integrated into CI/CD pipelines must therefore support controlled automation rather than unrestricted execution.
One constraint involves approval workflows. Automated analysis may identify issues that require human review before remediation decisions are made. Enterprises evaluate whether tools support pausing pipelines, annotating findings, and capturing approval rationale. Tools that enforce binary pass or fail outcomes without contextual flexibility often conflict with governance requirements.
Another constraint is evidence retention. Automated analysis must produce artifacts that can be retained and reviewed later. This includes logs, reports, and metadata that demonstrate compliance with internal policies. Static analysis tools that discard results after pipeline execution fail to meet audit expectations.
Segregation of duties further complicates automation. In some environments, the individuals who develop code cannot be the same individuals who approve changes. Static analysis tooling must integrate with identity and access controls to ensure that results are reviewed by appropriate roles. This requirement extends beyond technical integration and into process design.
Automation must also account for risk-based exceptions. Not all findings warrant the same response. Enterprises evaluate whether tools allow conditional automation based on severity, scope, or business context. Rigid automation increases friction and encourages bypass behavior, undermining the purpose of analysis.
These constraints align with broader discussions around change management automation challenges, which emphasize that automation must reinforce governance rather than bypass it. Static analysis tools that respect these realities are better suited for enterprise CI/CD integration.
Managing Signal Quality in Automated Analysis
As static analysis becomes embedded in CI/CD pipelines, signal quality becomes a critical concern. Automated execution amplifies both useful findings and noise. Enterprises evaluate tools based on their ability to deliver actionable insight without overwhelming teams with false positives or redundant alerts.
Signal quality depends on context. Findings that are relevant during initial development may be less relevant during maintenance or modernization phases. Static analysis tools must support configuration and scoping that reflect pipeline stage and purpose. Tools that apply uniform rules across all contexts often generate excessive noise.
Another factor is incremental analysis. Enterprises favor tools that focus on changes introduced in a specific pipeline run rather than re-reporting known issues. Incremental analysis supports faster feedback and reduces cognitive load. Tools that repeatedly surface legacy issues in every pipeline execution hinder adoption and slow delivery.
Correlation across analysis types also influences signal quality. Static analysis findings may need to be interpreted alongside test results, performance metrics, or deployment feedback. Tools that integrate or align with these signals provide more meaningful insight. Isolated findings lack the context needed for informed decision-making.
Signal management also affects cultural adoption. When developers perceive automated analysis as punitive or irrelevant, they seek ways to circumvent it. Enterprises evaluate whether tools support constructive workflows that guide remediation rather than enforcing blunt controls. This includes clear explanations, prioritization cues, and traceability.
The challenge of balancing automation with insight is discussed in resources such as continuous integration strategies, which note that automation must adapt to system complexity. Static analysis tools that manage signal quality effectively contribute to sustainable CI/CD practices at enterprise scale.
Common Limitations of Static Code Analysis Tools in Large Enterprises
Despite their widespread adoption, static code analysis tools exhibit recurring limitations when applied to large, long-lived enterprise environments. These limitations are not the result of poor implementation, but rather of mismatches between tool design assumptions and the realities of complex systems. Understanding these constraints is essential for setting realistic expectations and avoiding overreliance on analysis outputs.
As enterprise architectures continue to evolve through incremental change, mergers, regulatory pressure, and modernization initiatives, static analysis tools are increasingly asked to perform beyond their original scope. The following limitations consistently emerge across organizations, shaping how static analysis is positioned within broader engineering, risk, and governance strategies.
Incomplete Representation of Runtime Behavior
One of the most fundamental limitations of static code analysis in enterprise environments is its inability to fully represent runtime behavior. Static analysis operates on source artifacts and inferred relationships, which means it must approximate how systems execute under real conditions. While this approximation is often sufficient for identifying structural issues, it falls short when execution depends heavily on runtime state, configuration, or external interactions.
Enterprise systems frequently rely on dynamic behavior that is not visible in source code alone. Runtime configuration files, environment-specific parameters, feature flags, and external service responses all influence execution paths. Static analysis tools can identify potential paths, but they cannot determine which paths are exercised under specific operational conditions. This gap becomes significant when assessing risk associated with rarely executed logic or exception handling branches.
Batch processing further complicates this limitation. Execution order may depend on scheduling systems, conditional job triggers, or upstream data availability. Static analysis can trace job definitions and references, but it cannot simulate timing, concurrency, or data arrival patterns. As a result, certain classes of failures remain invisible until runtime, even in well analyzed systems.
Enterprises therefore evaluate static analysis outputs as necessary but incomplete representations of behavior. This perspective aligns with discussions around runtime analysis limitations, which emphasize that static insight must often be complemented by operational telemetry. Overinterpreting static results as definitive behavioral truth introduces risk rather than reducing it.
Recognizing this limitation does not diminish the value of static analysis. Instead, it frames its role appropriately as a structural and preparatory tool rather than a substitute for runtime understanding. Enterprises that acknowledge this boundary integrate static analysis into layered observability strategies rather than treating it as a standalone source of truth.
Difficulty Managing Scale-Induced Noise
As enterprise codebases grow, static analysis tools often generate an increasing volume of findings that overwhelm users. This phenomenon is not simply a matter of false positives. It reflects the cumulative effect of analyzing decades of accumulated logic, much of which no longer aligns with current standards or practices. Tools designed to flag deviations from idealized rulesets struggle to differentiate between acceptable legacy patterns and actionable issues.
Noise becomes particularly problematic when static analysis is introduced into environments with significant technical debt. Initial scans may surface thousands of findings, creating analysis paralysis. Teams are unable to prioritize effectively, and the perceived value of the tool declines rapidly. Without mechanisms to contextualize or suppress findings, analysis outputs become background noise rather than decision support.
Enterprises evaluate whether tools provide mechanisms for scoping, filtering, and incremental adoption. This includes the ability to focus on newly introduced issues, isolate findings within specific domains, or correlate results with business relevance. Tools that lack these capabilities tend to be abandoned or relegated to compliance checkboxes.
Noise also affects organizational trust. When developers and architects repeatedly encounter findings that do not correspond to real risk or operational impact, skepticism grows. This skepticism undermines adoption and encourages workarounds. Enterprises therefore view signal quality as a critical limitation that must be managed deliberately.
The challenge of scale-induced noise is closely related to discussions around measuring code volatility impact. High volatility areas may justify higher tolerance for findings, while stable areas demand precision. Static analysis tools that cannot adapt to these nuances struggle to remain relevant at scale.
Limited Support for Organizational Context
Another common limitation of static code analysis tools is their limited awareness of organizational context. Enterprises are not monolithic entities. They consist of multiple teams, priorities, regulatory obligations, and risk tolerances. Static analysis tools that apply uniform rules without accommodating these differences fail to align with how decisions are actually made.
Organizational context influences how findings are interpreted and acted upon. A finding that is critical in a customer-facing system may be acceptable in an internal reporting tool. Static analysis tools often lack mechanisms to encode these distinctions, resulting in findings that are technically accurate but operationally misleading.
This limitation extends to governance structures. Enterprises frequently operate under layered governance models where responsibility is distributed across architecture boards, security teams, and business units. Static analysis outputs that do not map cleanly to these structures require manual translation, increasing overhead and reducing timeliness.
Context also includes historical knowledge. Decisions made years earlier may have justified certain design choices that now appear suboptimal. Static analysis tools typically lack access to this rationale. Without context, findings can trigger unnecessary rework or conflict with established risk acceptance decisions.
Enterprises evaluate whether tools support annotation, documentation, and historical tracking to bridge this gap. Tools that allow teams to record rationale, suppress findings with justification, or link analysis results to change records provide greater long-term value. Those that treat analysis as a series of isolated scans do not support institutional learning.
The importance of organizational context is discussed in broader modernization narratives such as enterprise modernization governance, which emphasize that technical insight must align with decision structures. Static analysis tools that ignore this dimension risk becoming technically impressive but practically disconnected from enterprise reality.
Looking Ahead: Static Code Analysis in Enterprise Modernization
As enterprises move deeper into multi-year modernization programs, static code analysis is no longer evaluated solely as a quality or security control. It is increasingly viewed as a strategic capability that supports long-term decision-making under conditions of uncertainty. The future role of static analysis is shaped by the need to manage complexity incrementally rather than eliminate it outright, particularly in environments where legacy systems remain operational alongside modern platforms.
This forward-looking perspective emphasizes continuity over disruption. Enterprises seek analysis approaches that evolve with their systems, preserving institutional knowledge while enabling controlled change. Static code analysis in this context becomes a persistent source of insight that informs architectural choices, investment prioritization, and risk management as modernization progresses.
Static Analysis as a Continuous Modernization Instrument
Historically, static code analysis was often applied episodically, triggered by audits, major releases, or remediation initiatives. In enterprise modernization, this episodic model is giving way to continuous analysis that evolves alongside the system. Rather than producing one-time assessments, static analysis increasingly functions as an ongoing instrument that tracks structural change over time.
This shift reflects the reality that modernization rarely reaches a definitive endpoint. Systems continue to adapt to new regulatory requirements, business models, and technology platforms. Continuous static analysis enables enterprises to observe how complexity, dependency density, and risk profiles change as incremental modifications accumulate. This longitudinal insight supports proactive intervention rather than reactive remediation.
A key advantage of continuous analysis is its ability to establish baselines. By capturing the structural state of systems at defined points, enterprises can measure progress objectively. Decisions about refactoring, platform migration, or service decomposition can be evaluated against concrete evidence rather than intuition. Static analysis thus supports modernization as a managed process rather than an aspirational goal.
Continuous analysis also enhances accountability. When architectural decisions are informed by documented analysis, organizations can trace outcomes back to assumptions and constraints that existed at the time. This traceability reduces blame-driven responses to issues and fosters learning. Static analysis outputs become part of the organizational memory that informs future decisions.
These dynamics align with practices discussed in measurable refactoring objectives, which emphasize that modernization succeeds when change is guided by evidence. Static analysis that operates continuously provides the evidence needed to manage modernization as an evolving discipline rather than a sequence of isolated projects.
Preparing Enterprise Systems for AI-Assisted Change
Another forward-looking dimension of static code analysis is its role in preparing enterprise systems for AI-assisted development and modernization. As organizations explore the use of machine learning to support code transformation, risk assessment, and optimization, the quality of underlying system understanding becomes critical. AI models depend on accurate representations of structure and behavior to produce reliable outcomes.
Static analysis contributes to this foundation by formalizing relationships that would otherwise remain implicit. Dependency graphs, control flow models, and data lineage information provide structured inputs that can be consumed by automated tools. Without this groundwork, AI-assisted change risks amplifying existing misunderstandings rather than resolving them.
Enterprise environments present particular challenges for AI adoption. Legacy code often lacks consistent naming conventions, documentation, or modular boundaries. Static analysis can impose a layer of semantic clarity by identifying patterns, anomalies, and invariants within the codebase. This clarity supports safer experimentation with AI-driven tooling.
Preparation also involves risk containment. AI-assisted refactoring or translation introduces new uncertainties, especially in mission-critical systems. Static analysis enables enterprises to define safe boundaries for experimentation by identifying areas of high coupling or complexity that warrant caution. This selective approach reduces the likelihood of unintended consequences.
The intersection of static analysis and AI readiness is explored in discussions such as preparing code for AI integration, which highlight the need for structural insight before automation. Static analysis thus serves as both an enabler and a safeguard as enterprises adopt advanced tooling.
Evolving From Tooling to Architectural Intelligence
Looking ahead, the most significant transformation in static code analysis is its evolution from isolated tooling into a source of architectural intelligence. Enterprises increasingly expect analysis platforms to provide insights that transcend individual use cases and inform broader strategy. This expectation reflects the growing recognition that architecture is not static, but an emergent property shaped by continuous change.
Architectural intelligence involves understanding not only how systems are structured, but why they have evolved in particular ways. Static analysis contributes by revealing historical layering, dependency accretion, and areas of fragility. These insights help organizations make informed choices about where to invest modernization effort and where to accept constraints.
This evolution also changes how analysis is consumed. Rather than serving primarily developers, static analysis outputs increasingly support architects, platform leaders, and governance bodies. Visualizations, summaries, and impact assessments become decision artifacts that guide planning and oversight. The value of static analysis is measured by its influence on outcomes rather than by the volume of findings it produces.
Architectural intelligence also supports resilience. As systems grow more interconnected, the cost of failure increases. Static analysis that exposes single points of failure, hidden couplings, or excessive complexity enables proactive mitigation. This perspective aligns analysis with resilience engineering rather than defect detection alone.
The transition toward architectural intelligence is discussed in contexts such as enterprise software intelligence platforms, which emphasize the need to unify technical insight across domains. Static code analysis that contributes to this unified view becomes a strategic asset rather than a tactical tool.
From Tool Selection to Enterprise Understanding
The comparison makes clear that static code analysis in 2026 is no longer defined by the ability to flag isolated issues or enforce uniform rules. As enterprise systems continue to expand in scale, age, and interconnectedness, the decisive factor is whether analysis can support understanding rather than inspection. Tools that operate effectively within narrow scopes remain valuable, but their limitations become pronounced when decisions must account for execution behavior, cross-system dependencies, and long-term operational risk.
Enterprises face a persistent tension between the need to change and the need to preserve stability. Modernization initiatives, security remediation, and performance optimization all introduce pressure to act, yet the consequences of misjudged change are increasingly severe. Static code analysis contributes value only insofar as it reduces uncertainty in this environment. When analysis remains confined to repositories, applications, or vulnerability lists, it shifts effort rather than reducing risk.
The evolution of static analysis toward architectural and behavioral insight reflects a broader shift in enterprise engineering priorities. Understanding how systems function as integrated wholes has become more important than optimizing individual components in isolation. This understanding enables organizations to modernize incrementally, prioritize investment rationally, and maintain compliance without resorting to excessive conservatism.
Ultimately, static code analysis tools must be evaluated not as ends in themselves, but as instruments within a larger decision-making framework. The tools that endure are those that scale with complexity, preserve institutional knowledge, and support informed tradeoffs over time. In an enterprise landscape defined by continuous change, the ability to see clearly before acting remains the most valuable capability of all.